
ComfyUI MOSS TTS: text-to-speech, clonazione vocale, SFX e dialogo in un unico workflow#
Questo workflow ComfyUI MOSS TTS trasforma il testo in un discorso vivido a 24 kHz usando la famiglia OpenMOSS MOSS-TTS. Copre la sintesi veloce per singolo speaker, la clonazione vocale zero-shot da un breve clip di riferimento, il design vocale descrittivo, gli effetti sonori procedurali e il dialogo multi-speaker con riferimenti opzionali per speaker.
Basato sullo stack di nodi ufficiali MOSS-TTS e sulla famiglia di modelli, bilancia velocità e qualità. Il percorso Local 1.7B è la corsia veloce pratica su una singola GPU, mentre i modelli più grandi Delay 8B scambiano velocità per capacità ed espressività più ampie. Se hai bisogno di prompt riutilizzabili, voci clonate o dialoghi all'interno di ComfyUI, questo workflow ComfyUI MOSS TTS è progettato per te.
Modelli chiave nel workflow Comfyui ComfyUI MOSS TTS#
- OpenMOSS MOSS-TTS Local 1.7B. Trasformatore text-to-speech compatibile con GPU singola che offre discorsi veloci e naturali a 24 kHz per lavoro di produzione quotidiano. Scheda modello: MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. Una linea di modelli più grande che enfatizza qualità, somiglianza del speaker e prosodia a scapito della velocità e della memoria. Scheda modello: MOSS-TTS.
- MOSS Audio Tokenizer. Il codec appreso che collega le forme d'onda e i token discreti per i modelli MOSS-TTS, consentendo una decodifica ad alta fedeltà. Scheda modello: MOSS-Audio-Tokenizer.
Per dettagli sull'implementazione e aggiornamenti, vedere i repository ufficiali: OpenMOSS/MOSS-TTS e lo stack di nodi che alimenta questo workflow richservo/comfyui-moss-tts.
Come usare il workflow Comfyui ComfyUI MOSS TTS#
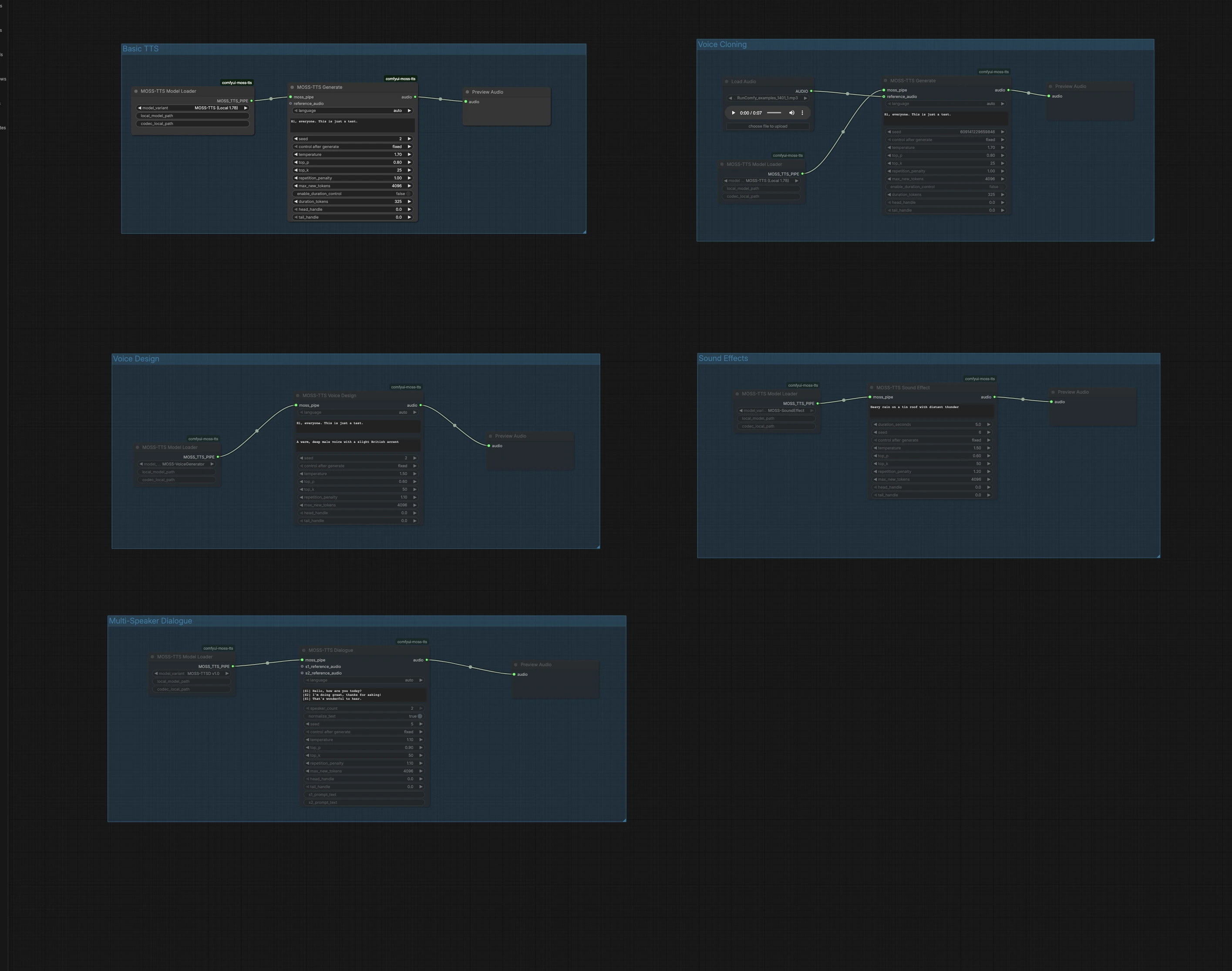
Questo grafico è organizzato in cinque gruppi indipendenti. Scegli il gruppo che corrisponde al tuo obiettivo, eseguilo, quindi visualizza in anteprima l'audio direttamente nella tela. Puoi eseguire più gruppi in parallelo per provare diversi approcci.
TTS di Base#
Il gruppo TTS di Base converte il testo semplice in discorso con il percorso veloce Local 1.7B. Carica il modello in MossTTSModelLoader (#1), inserisci il tuo testo in MossTTSGenerate (#2), quindi ascolta in PreviewAudio (#3). Il generatore si condiziona sul tuo prompt per modellare la pronuncia e la prosodia, quindi scrivi naturalmente con punteggiatura per il ritmo. Mantieni il seme fisso quando desideri ripetere le prese, o randomizzalo quando esplori varianti di consegna.
Clonazione Vocale#
Il gruppo Clonazione Vocale esegue la clonazione vocale zero-shot da un breve clip audio di riferimento. Importa un campione vocale pulito usando LoadAudio (#4), collegalo a MossTTSGenerate (#6) guidato da MossTTSModelLoader (#5), e fornisci il testo di destinazione. Il modello estrae il timbro e lo stile del speaker dal riferimento e rende il tuo nuovo script in quella voce. Usa contenuti neutri e rumore di fondo minimo nel riferimento per migliorare la somiglianza, e mantieni le durate moderate per la massima velocità di esecuzione.
Design Vocale#
Il Design Vocale crea una nuova voce da una descrizione in linguaggio naturale piuttosto che da un clip di esempio. MossTTSVoiceDesign (#9) utilizza una descrizione testuale come "Una voce maschile calda, profonda con un leggero accento britannico," combinata con il tuo script, per sintetizzare un discorso a 24 kHz. Il nodo è alimentato da un percorso generatore vocale dedicato caricato tramite MossTTSModelLoader (#8). Questo è ideale quando desideri una personalità coerente e riproducibile senza dover reperire registrazioni reali. Raffina i descrittori con tratti come età, timbro, accento ed energia per guidare il suono.
Effetti Sonori#
Gli Effetti Sonori generano audio non verbale da prompt testuali, utili per tracce di sottofondo, transizioni o strati ambientali. Con MossTTSSoundEffect (#12) e il suo tubo modello da MossTTSModelLoader (#11), prompt come "Pioggia pesante su un tetto di latta con tuoni lontani" producono texture ricche e ripetibili. Usa sostantivi e azioni concisi per definire la scena, quindi aggiungi alcuni aggettivi per fissare l'intensità o la distanza. Visualizza in anteprima in PreviewAudio (#13) e itera rapidamente per adattarlo al tuo mix.
Dialogo Multi-Speaker#
Il gruppo Dialogo Multi-Speaker rende conversazioni sceneggiate con clip di riferimento opzionali per speaker. Scrivi il tuo script usando tag speaker tra parentesi, ad esempio [S1] Ciao. e [S2] Salve!, quindi passalo a MossTTSDialogue (#15) sotto il tubo modello da MossTTSModelLoader (#14). Puoi allegare input audio di riferimento per S1 e S2 per clonare voci specifiche per ciascun ruolo, o lasciarli vuoti per permettere al modello di scegliere speaker distinti dal solo contesto testuale. Questo percorso è ben adatto per call-and-response, narrazione con linee di carattere, o mockup di interfaccia utente vocale.
Nodi chiave nel workflow Comfyui ComfyUI MOSS TTS#
MossTTSModelLoader (#1)#
Carica la famiglia di modelli OpenMOSS selezionata e assembla la pipeline TTS interna. Scegli la variante Local 1.7B per iterazioni rapide su una singola GPU, o passa a un modello più grande Delay 8B quando dai priorità all'espressività e alla somiglianza. Mantieni un loader per famiglia di compiti così che ogni ramo a valle rimanga autosufficiente.
MossTTSGenerate (#2)#
Il principale sintetizzatore per singolo speaker che consuma il tuo prompt testuale e l'audio di riferimento opzionale per produrre un discorso a 24 kHz. Fornisci testo pulito e ben punteggiato per una cadenza più chiara, e collega un breve clip vocale quando hai bisogno di clonazione zero-shot. Alterna il seeding tra fisso e casuale per bilanciare riproducibilità ed esplorazione.
MossTTSVoiceDesign (#9)#
Genera una voce nuova da un prompt descrittivo insieme al testo da pronunciare. Concentrati su timbro, età, accento ed energia per guidare l'identità mantenendola concisa. Questa è una scelta forte quando il licensing o il reperimento di una voce reale non è pratico.
MossTTSSoundEffect (#12)#
Sintetizza audio non verbale da una breve descrizione testuale. Scrivi prompt compatti che ancorano la sorgente, l'azione e lo spazio, quindi itera per adattare la scena. Ottimo per ambienti e one-shot all'interno dello stesso grafico ComfyUI MOSS TTS che usi per il dialogo.
MossTTSDialogue (#15)#
Analizza i tag speaker tra parentesi e rende conversazioni multi-turn come un output audio unico. Usa [S1], [S2], e così via per contrassegnare ogni linea, e opzionalmente collega clip di riferimento per speaker per preservare l'identità tra i turni. Mantieni le linee concise per i passaggi più affidabili tra gli speaker.
Extra opzionali#
- Inizia con il modello Local 1.7B per bozze rapide, quindi passa a un checkpoint Delay 8B quando hai bisogno di una somiglianza più forte o una prosodia più ricca.
- Per la clonazione zero-shot, usa un clip vocale pulito di 5–15 s con riverbero e rumore minimi per migliorare il trasferimento del timbro.
- Nel dialogo, mantieni i tag speaker coerenti e privi di punteggiatura come
[S1]per evitare errori di parsing. - Crea prompt di design vocale con 3–6 tratti come timbro, età, accento, stile ed energia per risultati prevedibili.
- Usa la punteggiatura e le interruzioni di linea nel tuo testo per controllare le pause e il ritmo nei risultati ComfyUI MOSS TTS.
- Aggiungi un nodo
SaveAudiodopo qualsiasi anteprima se desideri l'esportazione automatica dei file per render batch.
Riferimenti: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
Riconoscimenti#
Questo workflow implementa e si basa sui seguenti lavori e risorse. Ringraziamo sentitamente richservo per i nodi personalizzati ComfyUI MOSS-TTS, OpenMOSS per il repository MOSS-TTS e OpenMOSS-Team per i modelli MOSS-TTS (Delay 8B e Local 1.7B) e il MOSS Audio Tokenizer per i loro contributi e manutenzione. Per dettagli autorevoli, si prega di fare riferimento alla documentazione originale e ai repository collegati di seguito.
Risorse#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
Nota: L'uso dei modelli, dataset e codice citati è soggetto alle rispettive licenze e termini forniti dai loro autori e manutentori.