
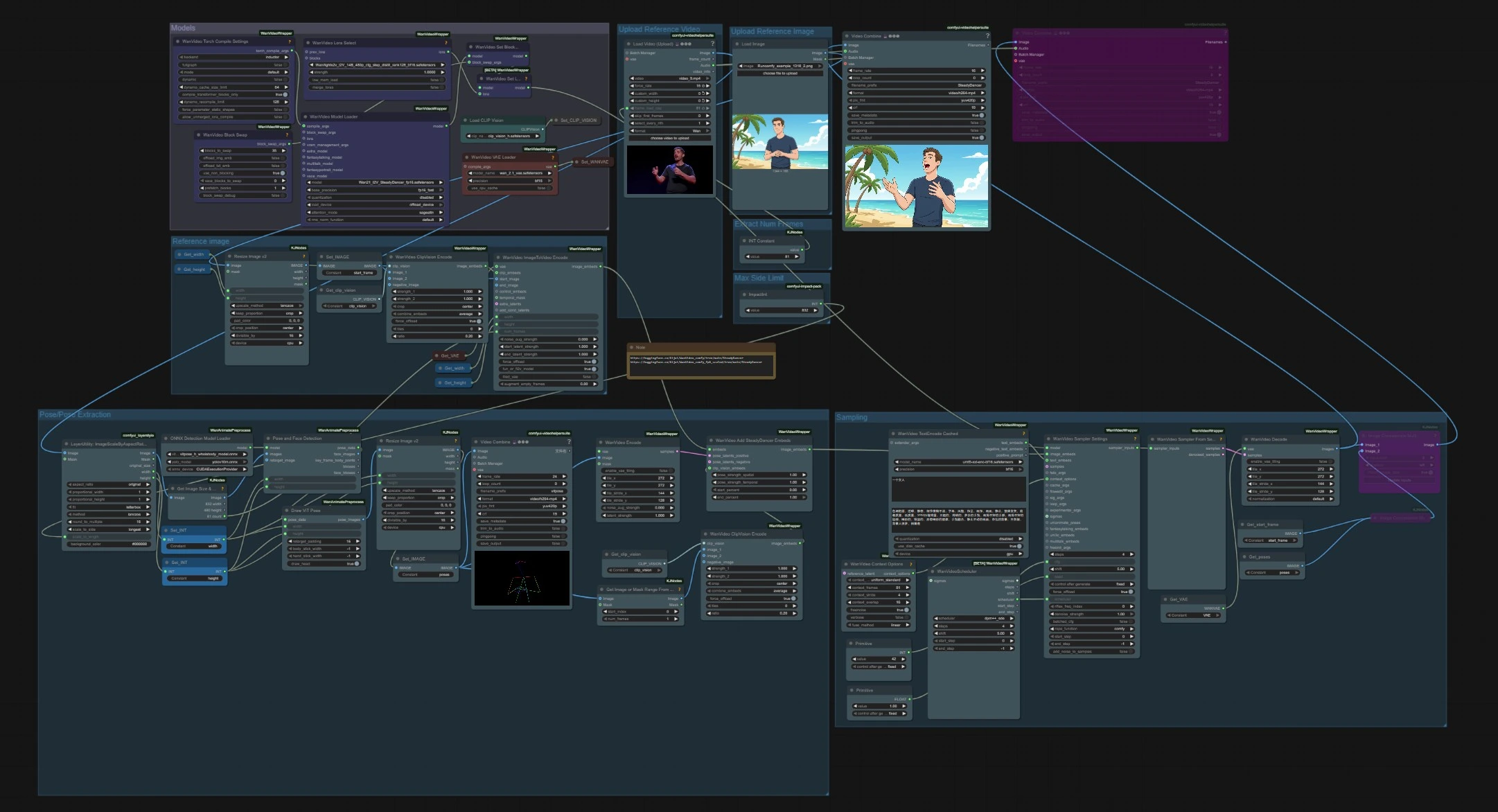
Flux de travail d'animation de pose image-à-vidéo SteadyDancer#
Ce flux de travail ComfyUI transforme une seule image de référence en une vidéo cohérente, guidée par le mouvement d'une source de pose distincte. Il est construit autour du paradigme image-à-vidéo de SteadyDancer, de sorte que le tout premier cadre conserve l'identité et l'apparence de votre image d'entrée tandis que le reste de la séquence suit le mouvement cible. Le graphique réconcilie pose et apparence à travers des intégrations spécifiques à SteadyDancer et un pipeline de pose, produisant un mouvement corporel fluide et réaliste avec une forte cohérence temporelle.
SteadyDancer est idéal pour l'animation humaine, la génération de danse et donner vie aux personnages ou portraits. Fournissez une image fixe plus un clip de mouvement, et le pipeline ComfyUI gère l'extraction de pose, l'intégration, l'échantillonnage et le décodage pour livrer une vidéo prête à être partagée.
Modèles clés dans le flux de travail Comfyui SteadyDancer#
- SteadyDancer. Modèle de recherche pour l'image-à-vidéo préservant l'identité avec un Mécanisme de Réconciliation de Condition et une Modulation de Pose Synergique. Utilisé ici comme méthode I2V principale. GitHub
- Wan 2.1 I2V SteadyDancer poids. Points de contrôle portés pour ComfyUI qui implémentent SteadyDancer sur la pile Wan 2.1. Hugging Face: Kijai/WanVideo_comfy (SteadyDancer) et Kijai/WanVideo_comfy_fp8_scaled (SteadyDancer)
- Wan 2.1 VAE. VAE vidéo utilisé pour l'encodage et le décodage latents dans le pipeline. Inclus avec le port WanVideo sur Hugging Face ci-dessus.
- OpenCLIP CLIP ViT‑H/14. Encodeur visuel qui extrait des intégrations d'apparence robustes de l'image de référence. Hugging Face
- ViTPose‑H WholeBody (ONNX). Modèle de points clés de haute qualité pour le corps, les mains et le visage utilisé pour dériver la séquence de pose motrice. GitHub
- YOLOv10 (ONNX). Détecteur qui améliore la localisation des personnes avant l'estimation de pose sur des vidéos diverses. GitHub
- umT5‑XXL encodeur. Encodeur de texte optionnel pour l'orientation de style ou de scène aux côtés de l'image de référence. Hugging Face
Comment utiliser le flux de travail Comfyui SteadyDancer#
Le flux de travail a deux entrées indépendantes qui se rencontrent à l'échantillonnage : une image de référence pour l'identité et une vidéo motrice pour le mouvement. Les modèles se chargent une fois au début, la pose est extraite du clip motrice, et les intégrations SteadyDancer mélangent pose et apparence avant la génération et le décodage.
Modèles#
Ce groupe charge les poids principaux utilisés tout au long du graphique. WanVideoModelLoader (#22) sélectionne le point de contrôle Wan 2.1 I2V SteadyDancer et gère les paramètres d'attention et de précision. WanVideoVAELoader (#38) fournit le VAE vidéo, et CLIPVisionLoader (#59) prépare la colonne vertébrale visuelle CLIP ViT‑H. Un nœud de sélection LoRA et des options BlockSwap sont présents pour les utilisateurs avancés qui souhaitent modifier le comportement de la mémoire ou attacher des poids supplémentaires.
Télécharger la vidéo de référence#
Importez la source de mouvement en utilisant VHS_LoadVideo (#75). Le nœud lit les images et l'audio, vous permettant de définir un taux de cadre cible ou de limiter le nombre d'images. Le clip peut être n'importe quel mouvement humain tel qu'une danse ou un mouvement sportif. Le flux vidéo passe ensuite à l'échelle du rapport d'aspect et à l'extraction de pose.
Extraire le nombre de cadres#
Une constante simple contrôle combien d'images sont chargées à partir de la vidéo motrice. Cela limite à la fois l'extraction de pose et la longueur de la sortie générée SteadyDancer. Augmentez-la pour des séquences plus longues, ou réduisez-la pour itérer plus rapidement.
Limite latérale maximale#
LayerUtility: ImageScaleByAspectRatio V2 (#146) met à l'échelle les images tout en préservant le rapport d'aspect afin qu'elles s'adaptent à l'allocation de mémoire et de stride du modèle. Définissez une limite longue-côté appropriée pour votre GPU et le niveau de détail souhaité. Les images mises à l'échelle sont utilisées par les nœuds de détection en aval et comme référence pour la taille de sortie.
Pose/Extraction de pose#
La détection de personne et l'estimation de pose s'exécutent sur les images mises à l'échelle. PoseAndFaceDetection (#89) utilise YOLOv10 et ViTPose‑H pour trouver les personnes et les points clés de manière robuste. DrawViTPose (#88) rend une représentation de figure en bâtonnet propre du mouvement, et ImageResizeKJv2 (#77) redimensionne les images de pose résultantes pour correspondre à la toile de génération. WanVideoEncode (#72) convertit les images de pose en latents afin que SteadyDancer puisse moduler le mouvement sans lutter contre le signal d'apparence.
Télécharger l'image de référence#
Chargez l'image d'identité que vous souhaitez que SteadyDancer anime. L'image doit montrer clairement le sujet que vous avez l'intention de déplacer. Utilisez une pose et un angle de caméra qui correspondent largement à la vidéo motrice pour le transfert le plus fidèle. Le cadre est transmis au groupe d'images de référence pour l'intégration.
Image de référence#
L'image fixe est redimensionnée avec ImageResizeKJv2 (#68) et enregistrée comme cadre de départ via Set_IMAGE (#96). WanVideoClipVisionEncode (#65) extrait des intégrations CLIP ViT‑H qui préservent l'identité, les vêtements et la disposition générale. WanVideoImageToVideoEncode (#63) emballe la largeur, la hauteur et le nombre de cadres avec le cadre de départ pour préparer le conditionnement I2V de SteadyDancer.
Échantillonnage#
C'est ici que l'apparence et le mouvement se rencontrent pour générer la vidéo. WanVideoAddSteadyDancerEmbeds (#71) reçoit le conditionnement d'image de WanVideoImageToVideoEncode et l'augmente avec des latents de pose plus une référence CLIP‑vision, permettant la réconciliation de conditions de SteadyDancer. Des fenêtres de contexte et des chevauchements sont définis dans WanVideoContextOptions (#87) pour la cohérence temporelle. Optionnellement, WanVideoTextEncodeCached (#92) ajoute des orientations de texte umT5 pour des ajustements de style. WanVideoSamplerSettings (#119) et WanVideoSamplerFromSettings (#129) exécutent les étapes de débruitage réelles sur le modèle Wan 2.1, après quoi WanVideoDecode (#28) convertit les latents en images RVB. Les vidéos finales sont enregistrées avec VHS_VideoCombine (#141, #83).
Nœuds clés dans le flux de travail Comfyui SteadyDancer#
WanVideoAddSteadyDancerEmbeds (#71)#
Ce nœud est le cœur de SteadyDancer du graphique. Il fusionne le conditionnement d'image avec des latents de pose et des indices CLIP‑vision de sorte que le premier cadre verrouille l'identité tandis que le mouvement se déploie naturellement. Ajustez pose_strength_spatial pour contrôler à quel point les membres suivent le squelette détecté et pose_strength_temporal pour réguler la fluidité du mouvement dans le temps. Utilisez start_percent et end_percent pour limiter où le contrôle de pose s'applique dans la séquence pour des intros et outros plus naturels.
PoseAndFaceDetection (#89)#
Exécute la détection YOLOv10 et l'estimation des points clés ViTPose‑H sur la vidéo motrice. Si les poses manquent de petits membres ou de visages, augmentez la résolution d'entrée en amont ou choisissez des séquences avec moins d'occlusions et un éclairage plus propre. Lorsque plusieurs personnes sont présentes, gardez le sujet cible le plus grand dans le cadre pour que le détecteur et la tête de pose restent stables.
VHS_LoadVideo (#75)#
Contrôle quelle partie de la source de mouvement vous utilisez. Augmentez la limite de cadre pour des sorties plus longues ou réduisez-la pour prototyper rapidement. L'entrée force_rate aligne l'espacement des poses avec le taux de génération et peut aider à réduire le bégaiement lorsque le FPS du clip original est inhabituel.
LayerUtility: ImageScaleByAspectRatio V2 (#146)#
Garde les images dans une limite longue-côté choisie tout en maintenant le rapport d'aspect et en les regroupant à une taille divisible. Associez l'échelle ici à la toile de génération pour que SteadyDancer n'ait pas besoin de suréchantillonner ou de couper de manière aggressive. Si vous voyez des résultats flous ou des artefacts de bord, rapprochez le côté long de l'échelle d'entraînement native du modèle pour un décodage plus propre.
WanVideoSamplerSettings (#119)#
Définit le plan de débruitage pour le sampler Wan 2.1. Le scheduler et steps définissent la qualité générale par rapport à la vitesse, tandis que cfg équilibre l'adhésion à l'image plus l'invite contre la diversité. seed verrouille la reproductibilité, et denoise_strength peut être abaissé lorsque vous voulez vous rapprocher encore plus de l'apparence de l'image de référence.
WanVideoModelLoader (#22)#
Charge le point de contrôle Wan 2.1 I2V SteadyDancer et gère la précision, la mise en œuvre de l'attention et le placement de l'appareil. Laissez ces paramètres tels quels pour la stabilité. Les utilisateurs avancés peuvent attacher un I2V LoRA pour modifier le comportement du mouvement ou alléger le coût informatique lors des expérimentations.
Extras optionnels#
- Choisissez une image de référence claire et bien éclairée. Les vues de face ou légèrement inclinées qui ressemblent à la caméra de la vidéo motrice rendent SteadyDancer plus fiable pour préserver l'identité.
- Préférez les clips de mouvement avec un seul sujet proéminent et un minimum d'occlusions. Les arrière-plans chargés ou les coupes rapides réduisent la stabilité de la pose.
- Si les mains et les pieds tremblent, augmentez légèrement la force temporelle de la pose dans
WanVideoAddSteadyDancerEmbedsou augmentez le FPS vidéo pour densifier les poses. - Pour des scènes plus longues, traitez en segments avec un contexte chevauchant et assemblez les sorties. Cela maintient l'utilisation de la mémoire raisonnable et assure la continuité temporelle.
- Utilisez les mosaïques de prévisualisation intégrées pour comparer les cadres générés par rapport au cadre de départ et à la séquence de pose pendant que vous ajustez les paramètres.
Ce flux de travail SteadyDancer vous offre un chemin pratique, de bout en bout, d'une image fixe à une vidéo fidèle, guidée par la pose, avec l'identité préservée dès le tout premier cadre.
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous reconnaissons avec gratitude MCG-NJU pour SteadyDancer pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux référentiels liés ci-dessous.
Ressources#
- MCG-NJU/SteadyDancer
- GitHub: MCG-NJU/SteadyDancer
- Hugging Face: MCG-NJU/SteadyDancer-14B
- arXiv: arXiv:2511.19320
Note: L'utilisation des modèles, ensembles de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.

