
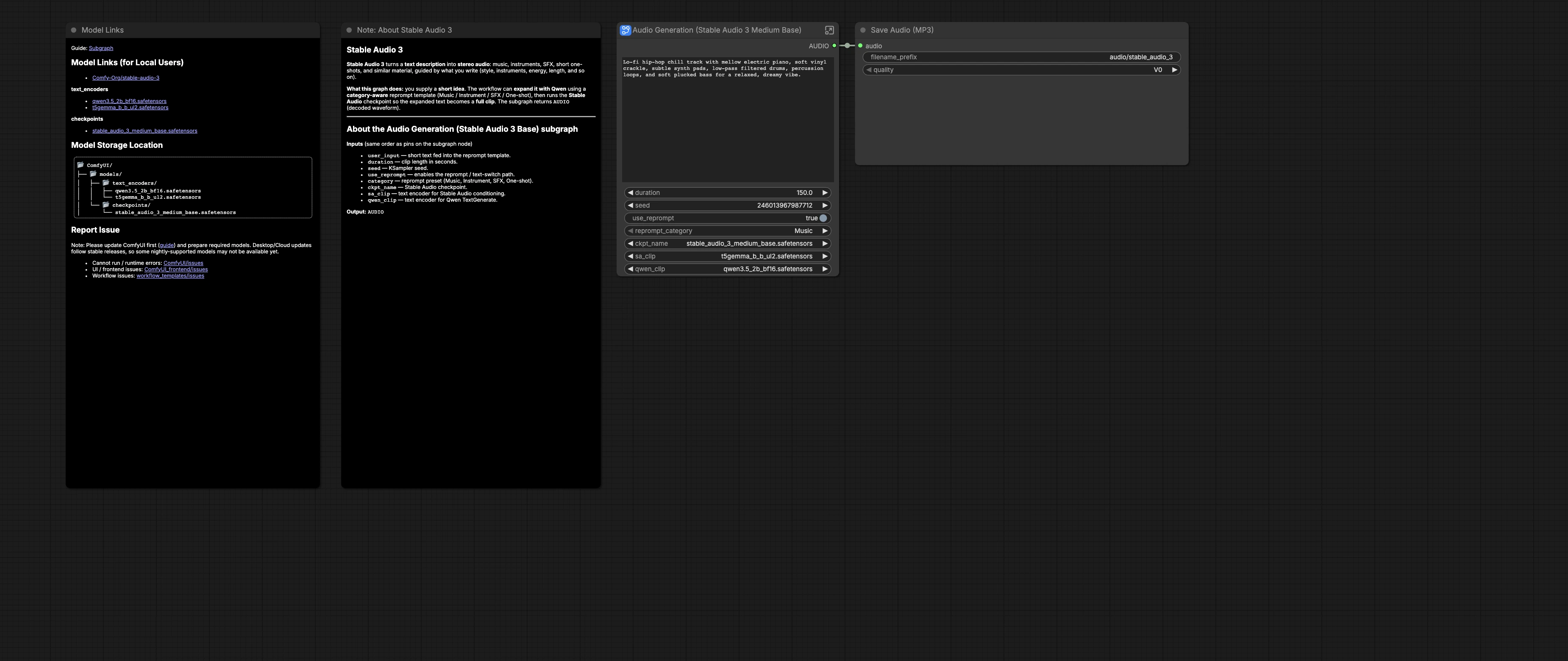
Workflow Stable Audio 3.0 Medium Base pour texte-à-audio long dans ComfyUI#
Ce workflow Stable Audio 3.0 Medium Base transforme de courtes idées textuelles en audio stéréo plus long et musical. Il est construit autour du checkpoint stable_audio_3_medium_base avec les encodeurs de texte T5-Gemma et Qwen3.5 pour livrer des esquisses musicales pilotées par des prompts, des fonds ambiants, des SFX et des one-shots avec des paramètres reproductibles dans ComfyUI.
Le graphe inclut un système de reprompt facultatif, conscient des catégories, qui peut étendre votre idée brève en un prompt dense et prêt pour la production avant la synthèse. Vous choisissez la catégorie, la durée et la graine, puis le pipeline conditionne Stable Audio 3 et rend l'audio qui est enregistré en MP3. Le workflow suit le modèle officiel et les ressources fournies par Comfy-Org pour Stable Audio 3.0 Medium Base. Consultez le modèle de référence et les modèles sur Comfy-Org/workflow_templates et Comfy-Org/stable-audio-3.
Modèles clés dans le workflow Comfyui Stable Audio 3.0 Medium Base#
- Checkpoint Stable Audio 3 Medium Base. Le modèle génératif principal qui synthétise l'audio stéréo à partir du conditionnement textuel et des latents. Source: Comfy-Org/stable-audio-3.
- Encodeur de texte T5-Gemma Base UL2. Produit les embeddings de texte utilisés pour conditionner Stable Audio 3 pour les prompts positifs et négatifs. Le fichier d'encodeur de texte emballé est inclus dans le dossier text_encoders du dépôt Stable Audio 3: Comfy-Org/stable-audio-3.
- Modèle de texte Qwen3.5 2B. Alimente le reprompt facultatif conscient des catégories qui étend une idée courte en une description détaillée de musique, instrument, SFX ou one-shot. Source: Comfy-Org/Qwen3.5.
Comment utiliser le workflow Comfyui Stable Audio 3.0 Medium Base#
À un niveau élevé, vous fournissez une idée courte et une durée cible. Le graphe peut garder vos mots tels quels ou utiliser Qwen3.5 pour les réécrire via un modèle de catégorie. Le résultat est encodé pour le conditionnement, échantillonné par Stable Audio 3, décodé en audio et sauvegardé.
Entrées utilisateur : prompt et durée#
Le sous-graphe Audio Generation (Stable Audio 3 Medium Base) (#52) expose user_input, duration, seed, use_reprompt, et category. Écrivez une idée brève en langage courant, comme un style, une liste d'instruments, une ambiance et un BPM facultatif. Choisissez une longueur de clip en secondes et définissez une seed pour la reproductibilité ou la variation. Activez use_reprompt lorsque vous souhaitez la réécriture pilotée par un modèle, puis sélectionnez une category telle que Music, Instrument, SFX ou One-shot.
Chargeurs : checkpoint et encodeurs de texte#
CheckpointLoaderSimple (#25) charge stable_audio_3_medium_base.safetensors, fournissant le MODEL et le VAE utilisés plus tard pour l'échantillonnage et le décodage. CLIPLoader (#26) charge l'encodeur T5-Gemma utilisé pour le conditionnement. Un second CLIPLoader (#29) charge le modèle Qwen3.5 qui alimente l'étape de reprompt.
Reprompt : modèles JSON et catégorie#
Un sélecteur de catégorie CustomCombo (#43) alimente un grand JSON de prompts système dans JsonExtractString (#49). Le modèle sélectionné est inséré dans un méta-prompt par Text Replace (PROMPT TEMPLATE) (#38). Votre user_input est injecté par Text Replace (USER INPUT) (#39), et la longueur cible est insérée à l'aide de Text Replace (AUDIO LENGTH) (#40), maintenant la réécriture alignée avec votre durée choisie.
Reprompt : Qwen TextGenerate#
TextGenerate (#28) utilise Qwen3.5 pour transformer le modèle assemblé plus votre idée en un prompt concis et détaillé qui suit les règles spécifiques à la catégorie. Cette étape est particulièrement utile pour les structures musicales plus longues et pour les SFX où le langage technique concret est important. La réécriture du prompt est prévisualisable, vous pouvez donc itérer rapidement sur le choix de la catégorie et le phrasé.
Basculement entre le texte original et réécrit#
ComfySwitchNode (#34) sélectionne soit votre texte original, soit la réécriture générée par Qwen en fonction de use_reprompt. Laissez-le activé pour obtenir des prompts structurés et conscients de la longueur, ou désactivez-le lorsque vous voulez un contrôle littéral sur le libellé. Ce simple commutateur facilite les tests A/B.
Encodage CLIP : conditionnement#
CLIPTextEncode (#6) convertit le prompt sélectionné en le conditionnement positif qui alimente le modèle. Un second CLIPTextEncode (#7) fournit un conditionnement négatif neutre par défaut. Ce couplage fournit à Stable Audio 3 une orientation claire tout en évitant les artefacts non intentionnels.
Génération audio : Stable Audio#
EmptyLatentAudio (#11) crée un latent audio dont la longueur correspond à duration. KSampler (#3) effectue le processus de débruitage à l'aide du MODEL Stable Audio 3 Medium Base du checkpoint. VAEDecodeAudio (#12) transforme le latent final en une onde sonore stéréo audible. Parce que la même duration informe également le reprompt, la longueur du clip rendu et le texte réécrit restent synchronisés.
Sauvegarde et exportation#
En dehors du sous-graphe, SaveAudioMP3 (#19) écrit le résultat dans un fichier MP3 avec un préfixe utile pour l'organisation. Utilisez ceci lors de la génération par lots avec différentes valeurs de seed ou catégories, puis auditionnez et conservez vos favoris.
Nœuds clés dans le workflow Comfyui Stable Audio 3.0 Medium Base#
ComfySwitchNode(#34). Bascule entre leuser_inputoriginal et le texte généré par Qwen. Activez-le pour des réécritures structurées et adaptées à la longueur ou désactivez-le pour un contrôle direct.TextGenerate(#28). Exécute Qwen3.5 avec un prompt système spécifique à la catégorie pour développer les idées. Pour personnaliser le style de réécriture, modifiez les modèles de catégorie dansJsonExtractString(#49) et les prompts de liaison dans les nœudsText Replaceadjacents.EmptyLatentAudio(#11). Définit la longueur du clip. Gardez cela aligné avec le jetonAUDIO_LENGTHinséré pour que le temps de synthèse corresponde à l'intention textuelle.KSampler(#3). Régit la trajectoire de débruitage pour Stable Audio 3. Ajustezseedpour des variations tout en gardant les autres paramètres stables pour comparer les prises équitablement.SaveAudioMP3(#19). Contrôle le préfixe et le format du nom de fichier de sortie pour une construction rapide de la bibliothèque à partir de plusieurs exécutions.
Extras facultatifs#
- Commencez avec une idée d'une ou deux phrases qui nomme le genre ou la source, les instruments clés ou les textures, et l'ambiance. Le reprompt peut remplir des détails comme le BPM et l'arrangement.
- Choisissez la catégorie qui correspond à votre objectif : Music pour des morceaux complets, Instrument pour des boucles ou des stems, SFX pour des environnements et actions, One-shot pour des frappes isolées.
- Gardez la durée réaliste pour votre contenu cible. Les clips très longs sont plus lourds à calculer et peuvent bénéficier d'une
seedstable pendant que vous itérez. - Lorsque les résultats semblent encombrés, désactivez le reprompt et essayez une phrase plus simple, puis réactivez-le une fois que vous aimez la direction.
- Pour des prises alternatives rapides, gardez tout constant et changez seulement la
seed.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy-Org pour l'article de support ComfyUI Stable Audio 3 Day-0, Comfy-Org pour le modèle de workflow officiel Stable Audio 3.0 Medium Base, Comfy-Org pour les fichiers modèle Stable Audio 3, et Comfy-Org pour les fichiers modèle d'encodeur Qwen3.5 pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Comfy-Org/Article de Support ComfyUI Stable Audio 3 Day-0
- Docs / Notes de version : Stable Audio 3 Day-0 Support
- Comfy-Org/Modèle de Workflow Officiel Stable Audio 3.0 Medium Base
- GitHub : Comfy-Org/workflow_templates
- Fichiers Modèle Stable Audio 3 de Comfy-Org
- Hugging Face : Comfy-Org/stable-audio-3
- Fichiers Modèle d'Encodeur Qwen3.5 de Comfy-Org
- Hugging Face : Comfy-Org/Qwen3.5
Note : L'utilisation des modèles, jeux de données et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.