
⚠️ Note importante : Cette implémentation ComfyUI de MultiTalk ne prend actuellement en charge que la génération d'UNE SEULE PERSONNE. Les fonctionnalités de conversation multi-personnes seront bientôt disponibles.
1. Qu'est-ce que MultiTalk ?#
MultiTalk est un framework révolutionnaire pour la génération de vidéos conversationnelles multi-personnes basées sur l'audio, développé par MeiGen-AI. Contrairement aux méthodes traditionnelles de génération de têtes parlantes qui n'animent que les mouvements faciaux, la technologie MultiTalk peut générer des vidéos réalistes de personnes parlant, chantant et interagissant tout en maintenant une synchronisation labiale parfaite avec l'entrée audio. MultiTalk transforme les photos statiques en vidéos parlantes dynamiques en faisant parler ou chanter la personne exactement comme vous le souhaitez.
2. Comment fonctionne MultiTalk#
MultiTalk utilise une technologie IA avancée pour comprendre à la fois les signaux audio et les informations visuelles. L'implémentation ComfyUI de MultiTalk combine MultiTalk + Wan2.1 + Uni3C pour des résultats optimaux :
Analyse audio : MultiTalk utilise un puissant encodeur audio (Wav2Vec) pour comprendre les nuances de la parole, y compris le rythme, le ton et les schémas de prononciation.
Compréhension visuelle : Construit sur le robuste modèle de diffusion vidéo Wan2.1, MultiTalk comprend l'anatomie humaine, les expressions faciales et les mouvements corporels (vous pouvez visiter notre workflow Wan2.1 pour la génération t2v/i2v).
Contrôle de caméra : MultiTalk avec Uni3C controlnet permet des mouvements subtils de caméra et un contrôle de scène, rendant la vidéo plus dynamique et professionnelle. Découvrez notre workflow Uni3C pour créer de beaux transferts de mouvement de caméra.
Synchronisation parfaite : Grâce à des mécanismes d'attention sophistiqués, MultiTalk apprend à aligner parfaitement les mouvements des lèvres avec l'audio tout en conservant des expressions faciales et un langage corporel naturels.
Suivi d'instructions : Contrairement aux méthodes plus simples, MultiTalk peut suivre des prompts textuels pour contrôler la scène, la pose et le comportement général tout en maintenant la synchronisation audio.
3. Avantages de ComfyUI MultiTalk#
- Synchronisation labiale de haute qualité : MultiTalk atteint une précision de synchronisation labiale à la milliseconde, particulièrement impressionnante pour les scénarios de chant
- Création de contenu polyvalente : MultiTalk prend en charge la génération de parole et de chant avec divers types de personnages, y compris les personnages de dessins animés
- Résolution flexible : MultiTalk génère des vidéos en 480P ou 720P avec des rapports d'aspect arbitraires
- Support de longues vidéos : MultiTalk crée des vidéos d'une durée maximale de 15 secondes
- Suivi d'instructions : MultiTalk contrôle les actions des personnages et les paramètres de scène via des prompts textuels
4. Comment utiliser le workflow ComfyUI MultiTalk#
Guide d'utilisation étape par étape de MultiTalk#
Étape 1 : Préparer les entrées MultiTalk
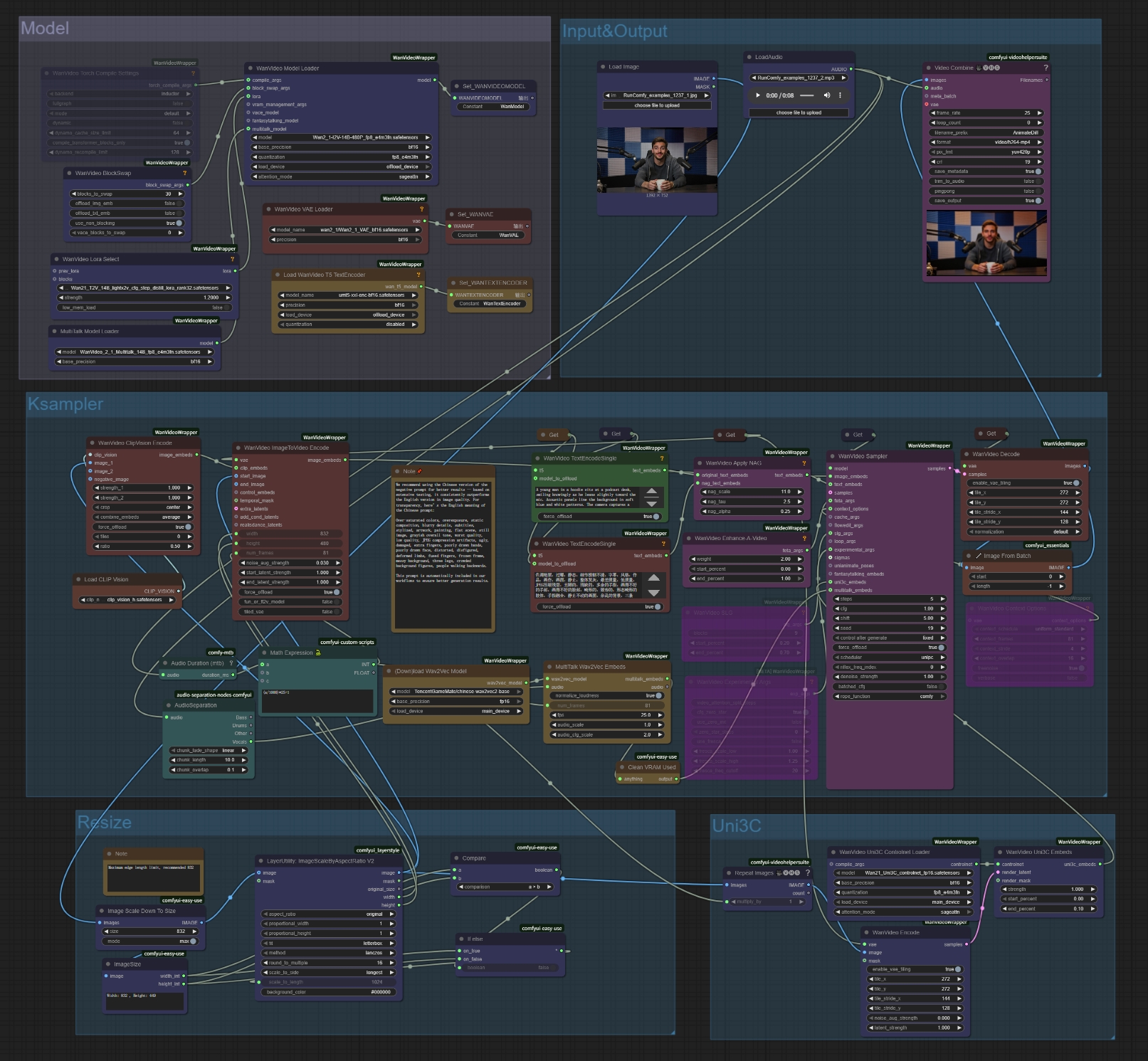
- Télécharger l'image de référence : Cliquez sur "choose file to upload" dans le nœud Load Image
- Utilisez des photos nettes et de face pour les meilleurs résultats MultiTalk
- L'image sera automatiquement redimensionnée aux dimensions optimales (832px recommandé)
- Télécharger le fichier audio : Cliquez sur "choose file to upload" dans le nœud LoadAudio
- MultiTalk prend en charge divers formats audio (WAV, MP3, etc.)
- Une parole/chant clair fonctionne mieux avec MultiTalk
- Pour créer des chansons personnalisées, envisagez d'utiliser notre workflow de génération musicale Ace-Step, qui produit de la musique de haute qualité avec des paroles synchronisées.
- Écrire le prompt textuel : Décrivez votre scène souhaitée dans les nœuds d'encodage de texte pour la génération MultiTalk
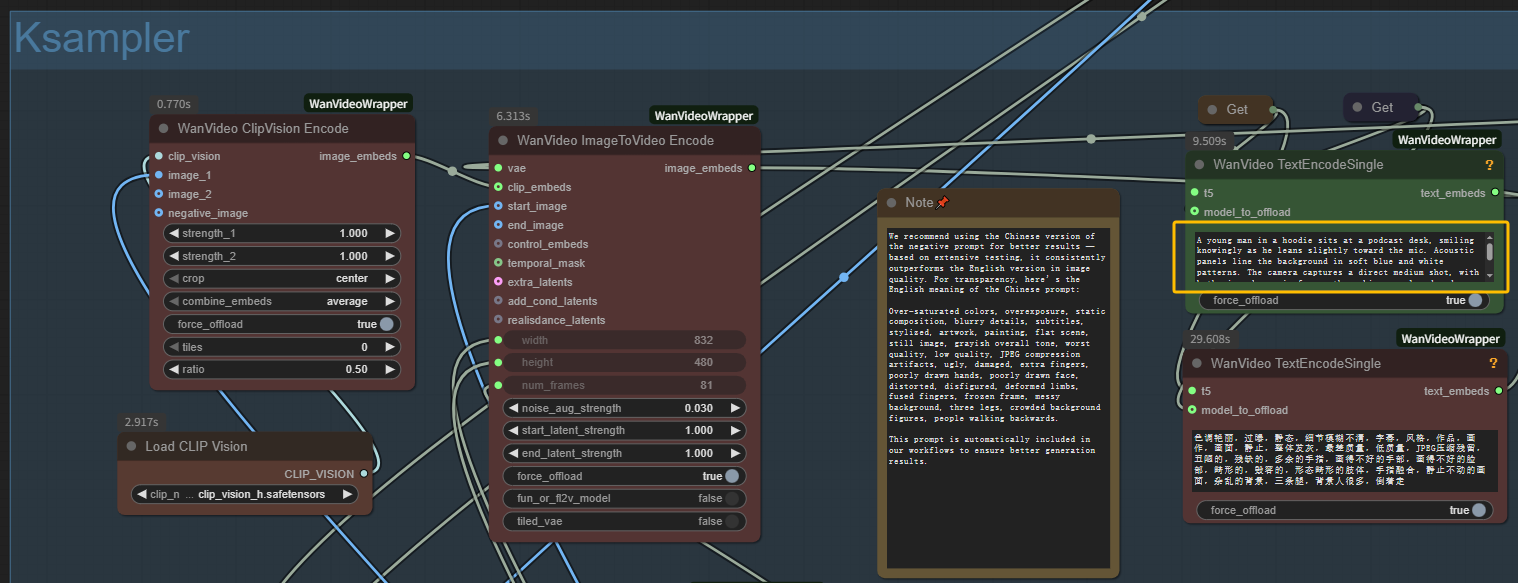
Étape 2 : Configurer les paramètres de génération MultiTalk
- Étapes d'échantillonnage : 20-40 étapes (plus élevé = meilleure qualité MultiTalk, génération plus lente)
- Audio Scale : Garder à 1.0 pour une synchronisation labiale MultiTalk optimale
- Embed Cond Scale : 2.0 pour un conditionnement audio MultiTalk équilibré
- Contrôle de caméra : Activer Uni3C pour des mouvements subtils, ou désactiver pour des prises MultiTalk statiques
Étape 3 : Améliorations optionnelles de MultiTalk
- Accélération LoRA : Activer pour une génération MultiTalk plus rapide avec une perte de qualité minimale
- Amélioration vidéo : Utiliser les nœuds d'amélioration pour le post-traitement MultiTalk
- Prompts négatifs : Ajouter les éléments indésirables à éviter dans la sortie MultiTalk (flou, déformé, etc.)
Étape 4 : Générer avec MultiTalk
- Mettre le prompt en file d'attente et attendre la génération MultiTalk
- Surveiller l'utilisation de la VRAM (48 Go recommandés pour MultiTalk)
- Temps de génération MultiTalk : 7-15 minutes selon les paramètres et le matériel
5. Remerciements#
Recherche originale : MultiTalk est développé par MeiGen-AI en collaboration avec des chercheurs de premier plan dans le domaine. L'article original "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" présente la recherche révolutionnaire derrière cette technologie.
Intégration ComfyUI : L'implémentation ComfyUI est fournie par Kijai via le dépôt ComfyUI-WanVideoWrapper, rendant cette technologie avancée accessible à la communauté créative élargie.
Technologie de base : Construit sur le modèle de diffusion vidéo Wan2.1 et intègre des techniques de traitement audio de Wav2Vec, représentant une synthèse de la recherche IA de pointe.
6. Liens et ressources#
- Recherche originale : MeiGen-AI MultiTalk Repository
- Page du projet : https://meigen-ai.github.io/multi-talk/
- Intégration ComfyUI : ComfyUI-WanVideoWrapper