
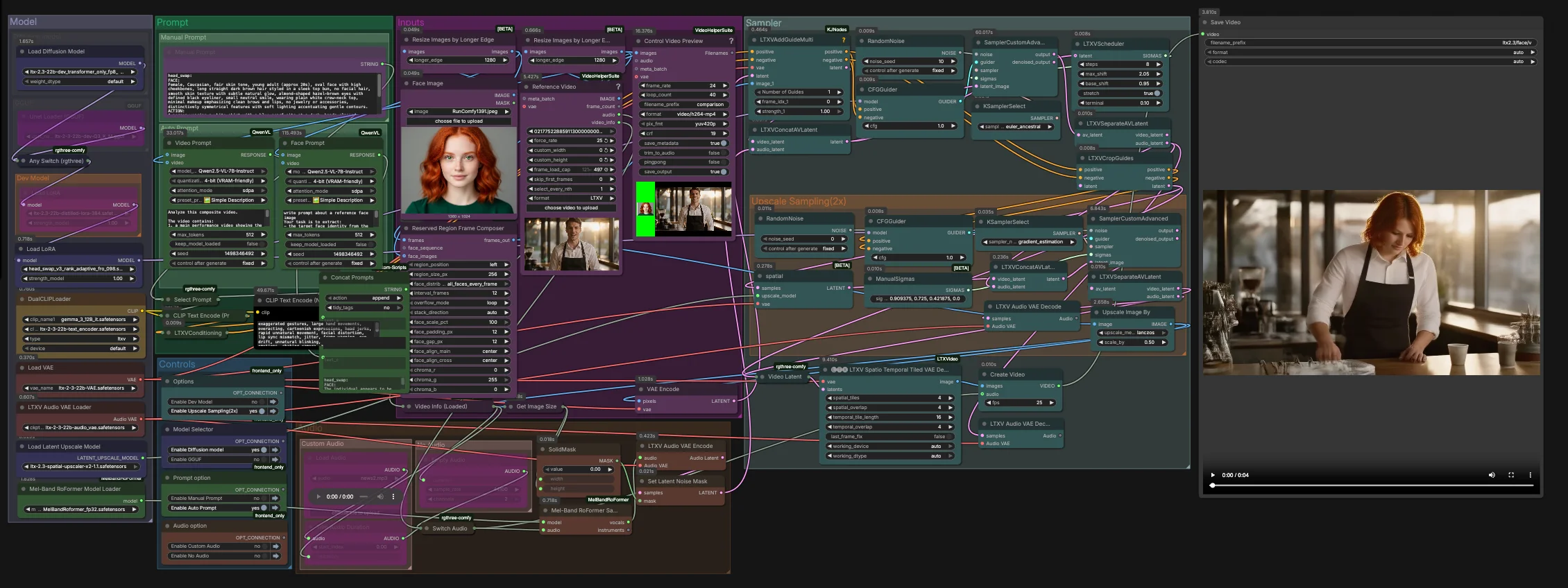
LTX-2.3-Video-Face-Swap pour ComfyUI#
Ce flux de travail offre un remplacement de visage vidéo de haute fidélité et stable dans le temps en utilisant la famille LTX 2.3. Conçu pour RunComfy et ComfyUI, il fusionne une image guide d'identité avec une vidéo cible et une guidance audio optionnelle pour préserver les expressions, l'éclairage et le mouvement à travers les images. Le résultat est un échange réaliste et résistant au scintillement qui tient dans les gros plans et les plans moyens.
Les créateurs, artistes VFX et cinéastes IA peuvent utiliser LTX-2.3-Video-Face-Swap pour garder un contrôle créatif total : proposer manuellement ou générer des invites structurées à partir des entrées, choisir entre les variantes dev, distilled, FP8 ou GGUF, et terminer par un décodage spatio-temporel et un suréchantillonnage latent 2x optionnel pour des détails nets.
Modèles clés dans le flux de travail Comfyui LTX-2.3-Video-Face-Swap#
- LTX 2.3 22B Video Diffusion Transformer. Modèle central de génération et d'édition vidéo qui conduit la préservation de l'identité et la cohérence temporelle. Voir la famille de modèles officielle à Lightricks/LTX-2.3.
- LTX 2.3 Text Encoders. Le graphe associe l'encodeur de texte LTX 2.3 avec un encodeur instruct Gemma 3 12B pour améliorer l'alignement des invites pour l'édition vidéo. Exemples d'artefacts : ltx-2-3-22b-text_encoder.safetensors et gemma_3_12B_it.safetensors.
- LTX 2.3 VAE et Audio VAE. Encodeurs/décodeurs utilisés pour compresser et reconstruire les images visuelles et les pistes audio tout en préservant les détails et la synchronisation. Voir Lightricks/LTX-2.3 VAE files et les variantes audio VAE dans le dépôt fractionné vantagewithai/LTX-2.3-Split.
- LTX 2.3 Spatial Upscaler x2. Suréchantillonneur latent 2x qui augmente la fidélité spatiale avant le décodage final, idéal pour les détails du visage. ltx-2.3-spatial-upscaler-x2-1.1.safetensors.
- Head-swap LoRA. Un LoRA adaptatif en rang spécialisé pour le transfert d'identité qui améliore la ressemblance et la stabilité lors de l'édition. Exemple : head_swap_v3_rank_adaptive_fro_098.safetensors.
- MelBandRoFormer. Modèle optionnel de séparation de source musicale utilisé ici pour isoler les voix pour une guidance de mouvement buccal plus forte. Kijai/MelBandRoFormer_comfy.
- Variantes de déploiement optionnelles. Poids exclusivement transformateurs FP8 pour la rapidité sur les GPU pris en charge Kijai/LTX2.3_comfy et constructions UNet GGUF légères pour les scénarios CPU ou faible VRAM vantagewithai/LTX-2.3-GGUF.
Comment utiliser le flux de travail Comfyui LTX-2.3-Video-Face-Swap#
Ce graphe fonctionne en deux étapes. La première étape effectue l'échange principal à la résolution latente native avec une guidance audio-consciente. La deuxième étape effectue un suréchantillonnage dans l'espace latent et affine la région du visage avant un décodage spatio-temporel et un mux final en vidéo.
Entrées#
- Chargez votre image d'identité dans
Face Image(LoadImage(#255)). Utilisez une prise frontale ou trois-quarts bien éclairée pour une extraction d'identité plus fiable. - Chargez la séquence cible dans
Reference Video(VHS_LoadVideo(#393)). Les images sont normalisées et prévisualisées viaResizeImagesByLongerEdgeetControl Video Preview(VHS_VideoCombine(#396)) pour des vérifications rapides avant l'échantillonnage. - Le
ReservedRegionFrameComposer(#395) prépare des images guides qui alignent l'image du visage sur la disposition de la scène, aidant le modèle à se concentrer sur la zone d'échange pendant le conditionnement.
Invite#
- Vous pouvez décrire l'apparence et l'action souhaitées manuellement dans
Manual Promptou laisser le graphe composer automatiquement une invite structurée.Video Prompt(AILab_QwenVL(#400)) extrait le mouvement du corps et la scène de la vidéo tandis queFace Prompt(AILab_QwenVL(#401)) extrait les détails d'identité de l'image du visage. Concat Promptsfusionne l'identité et l'action en une instruction concise, puisSelect Promptdirige soit votre texte manuel, soit l'invite automatique versCLIP Text Encode. Le texte de l'invite négative est encodé séparément pour supprimer les artefacts vidéo courants.
Modèle#
- Le groupe
Modelcharge le LTX 2.3 UNet ou sa variante GGUF, applique le LoRA distillé et le head-swap LoRA, et met en place les VAEs LTX et les encodeurs de texte doubles. La configuration à deux encodeurs améliore l'alignement pour le contenu parlé et le blocage de la caméra sans sur-contraindre l'identité. - Si vous optimisez pour la vitesse ou la mémoire, basculez entre dev, distilled, FP8 uniquement transformateur, ou GGUF dans le sélecteur de modèle fourni. Aucune configuration supplémentaire n'est nécessaire dans RunComfy.
Échantillonneur#
- La première étape combine les latents vidéo et audio dans
LTXVConcatAVLatent(#321), puis débruit avecCFGGuider(#326),LTXVScheduler(#324), etSamplerCustomAdvanced(#257). LeLTXVAddGuideMulti(#392) injecte votre guide d'identité afin que le visage soit établi tôt et reste stable dans le temps. - Après un premier passage,
LTXVSeparateAVLatent(#323) divise les flux afin queLTXVCropGuides(#282) puisse concentrer l'édition autour du visage. Cela concentre le calcul là où c'est important et améliore la cohérence temporelle.
Échantillonnage de Suréchantillonnage (2x)#
LTXVLatentUpsampler(#279) applique le suréchantillonneur spatial x2 de LTX 2.3 dans l'espace latent. Le latent vidéo suréchantillonné est ensuite réuni avec le latent audio dansLTXVConcatAVLatent(#287) et affiné par un second passage deSamplerCustomAdvanced(#288) guidé parCFGGuider(#284).- Cette stratégie en deux étapes produit une peau, des yeux et des cheveux plus nets tout en maintenant l'échange verrouillé sur l'identité souhaitée.
Audio#
- Le groupe
Audiovous permet de router l'audio original, le silence ou un segment coupé viaSwitch Audio. Pour des indices de mouvement des lèvres plus forts, la piste sélectionnée est envoyée viaMelBandRoFormerSampler(#355) pour isoler les voix, puis encodée avecLTXVAudioVAEEncode(#364). - Un masque de bruit solide (
SetLatentNoiseMask(#365)) empêche les changements non désirés entraînés par l'audio en dehors de la région buccale tout en tirant parti du timing de la parole pour guider les expressions.
Décodage et exportation#
- Les images finales sont reconstruites avec
LTXVSpatioTemporalTiledVAEDecode(#377), qui décode avec un carrelage temporel pour éviter les coutures et maintenir la continuité du mouvement.CreateVideo(#292) multiplexe les images avec l'audio choisi, etSaveVideoécrit le clip fini.
Nœuds clés dans le flux de travail Comfyui LTX-2.3-Video-Face-Swap#
LTXVAddGuideMulti(#392). Alimente le guide de visage aligné dans le flux de conditionnement pour que le modèle se verrouille sur l'identité cible dès les premières étapes. Si la ressemblance dérive dans les mouvements rapides, augmentez le nombre ou la fréquence des images guides plutôt que d'augmenter globalement la guidance.LTXVCropGuides(#282). Se concentre automatiquement sur la région faciale dérivée des latents de la première étape et des invites. Utilisez-le pour resserrer la zone d'édition lorsque les arrière-plans ou les mains rivalisent pour attirer l'attention.SamplerCustomAdvanced(#257). Passage principal de débruitage qui établit l'identité, l'éclairage et le mouvement grossier. Associez-le avec leLTXVSchedulerpour la mise en forme des étapes et gardez le choix de l'échantillonneur stable à travers les expériences pour rendre les comparaisons significatives.LTXVLatentUpsampler(#279). Effectue un suréchantillonnage latent 2x en utilisant le suréchantillonneur spatial LTX avant le raffinement. Utilisez ceci lorsque vous avez besoin de pores, de cils et de coutures de chapeau plus nets sans introduire de scintillement à partir des suréchantillonneurs de pixels post-décodage.SamplerCustomAdvanced(#288). Passage de raffinement après le suréchantillonnage. Ajustez modérément la guidance ici pour affiner les caractéristiques tout en préservant l'identité définie par le premier passage.LTXVSpatioTemporalTiledVAEDecode(#377). Décodeur temporel qui réduit les coutures de tuiles à travers les images. Si vous atteignez les limites de VRAM sur de longs clips, préférez ajuster sa disposition de tuiles plutôt que de baisser la résolution.MelBandRoFormerSampler(#355). Séparation vocale utilisée uniquement pour la guidance. Si l'audio source est bruyant, passez à l'audio original ou silencieux pour éviter de propager les artefacts dans le mouvement buccal.
Extras optionnels#
- La qualité de l'image du visage est importante. Utilisez une photo neutre, bien éclairée, de face ou légèrement trois-quarts à un âge et une expression similaires à la performance.
- Gardez la vidéo de référence stable. Les prises statiques ou sur trépied produisent les résultats LTX-2.3-Video-Face-Swap les plus stables, surtout dans les plans moyens et rapprochés.
- Les invites doivent être concises. Énoncez la scène et l'action en un seul paragraphe et réservez les adjectifs d'identité pour l'invite de visage, pas l'invite d'action.
- La guidance audio est optionnelle. Un discours clair améliore les formes de bouche ; les pistes uniquement musicales apportent peu de bénéfice, donc choisissez le silence pour concentrer le calcul sur les visuels.
- Pour les exécutions avec faible VRAM ou uniquement CPU, préférez la construction UNet GGUF ; pour un débit élevé sur les GPU modernes, les poids exclusivement transformateurs FP8 sont un bon choix par défaut.
- Utilisez de manière responsable. Obtenez le consentement pour toute ressemblance que vous échangez et respectez les lois et politiques de plateforme applicables.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement LTX-2.3 pour le modèle LTX-2.3, et EyeForAILabs pour le tutoriel YouTube, pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- LTX-2.3/LTX-2.3 Model
- Hugging Face: Hugging Face Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.