
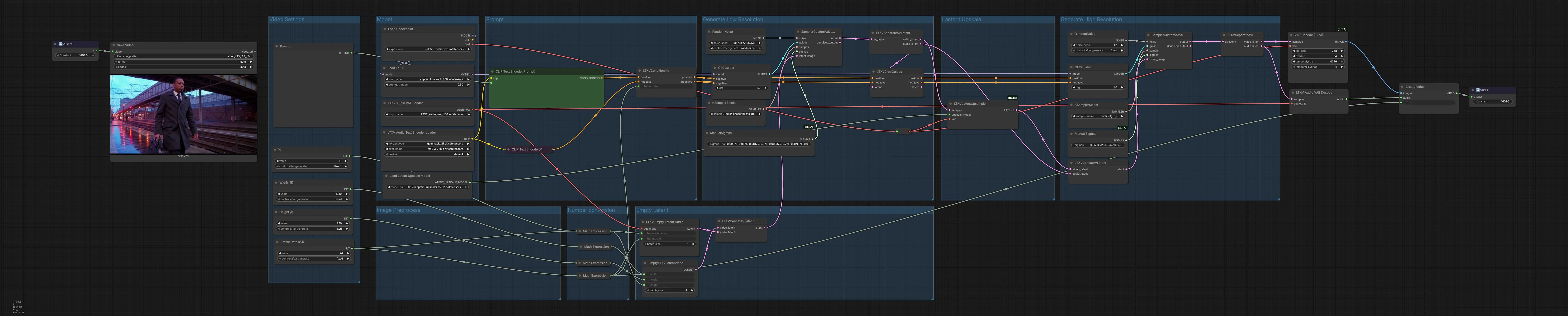
LTX 2.3 Sulphur 2 workflow de texte à vidéo pour l'animation de personnages cinématographiques#
Ce pipeline ComfyUI transforme des invites en langage naturel en vidéos courtes, cinématographiques, axées sur les personnages avec audio optionnel, construit autour des composants Lightricks LTX-2.3 et Sulphur 2. Il met en scène la génération en basse résolution pour la planification du mouvement, met à l'échelle la séquence latente, puis affine en haute résolution avant de décoder en images et de muxer une piste audio synchronisée.
Le workflow de texte à vidéo LTX 2.3 Sulphur 2 est idéal pour des tests rapides d'animation de personnages, des concepts de mouvement de style D-Human, et des expériences de texte-à-vidéo raffinées. Il ne repose pas sur des entrées image-à-vidéo ou des relais d'invites; tout commence à partir du texte, avec le conditionnement LTXV guidant à la fois les latents vidéo et audio de bout en bout.
Modèles clés dans le workflow Comfyui LTX 2.3 Sulphur 2 texte à vidéo#
- Lightricks LTX-2.3. Générateur de texte-à-vidéo principal utilisé pour la synthèse spatiotemporelle et les latents AV multimodaux. Voir le dépôt officiel du modèle pour les poids et les notes sur les capacités et les limitations. Hugging Face: Lightricks/LTX-2.3
- Lightricks LTX-2.3 FP8 checkpoint. Variante économe en mémoire de LTX-2.3 qui accélère l'inférence et permet des clips plus longs ou des résolutions plus élevées sur des GPU contraints. Hugging Face: Lightricks/LTX-2.3-fp8
- Modèle de base Sulphur 2. Fournit des prioris de style et des détails de personnages via LoRA dans ce workflow, aidant à obtenir des visages nets et une tonalité cinématographique. Hugging Face: SulphurAI/Sulphur-2-base
- LTX-2.3 Spatial Upscaler x2 1.1. Upscaler d'espace latent qui augmente le détail spatial avant le passage de raffinement haute résolution. Hugging Face: Lightricks/LTX-2.3 file ltx-2.3-spatial-upscaler-x2-1.1.safetensors
- Encodeur de texte LTX (Gemma 3 12B IT emballé pour LTX). Fournit l'espace d'embedding de texte adapté au conditionnement LTX-2.3 pour un suivi fidèle de l'invite. Hugging Face: Comfy-Org/ltx-2
- LTX Audio VAE. Décode le latent audio généré en parallèle de la vidéo afin que le rendu final puisse inclure une bande sonore synchronisée. Hugging Face: Lightricks/LTX-2.3
Comment utiliser le workflow Comfyui LTX 2.3 Sulphur 2 texte à vidéo#
Logique générale Le pipeline fonctionne en trois actes : génération en basse résolution pour établir le mouvement et la composition, mise à l'échelle latente pour augmenter le détail spatial, et un passage de raffinement haute résolution qui produit également l'audio final. Les latents sont décodés en images et en formes d'onde, puis muxés dans un conteneur MP4 prêt pour la livraison.
Paramètres Vidéo Utilisez le groupe "Paramètres Vidéo" pour définir la largeur, la hauteur, le taux de trame et la durée. Le nombre de trames est calculé automatiquement à partir de votre durée et fps pour que le timing et le rythme restent cohérents. Ces valeurs pilotent l'allocation et le décodage latents, donc définissez-les d'abord pour correspondre à votre rapport d'aspect et à votre durée cible. Ajuster le fps ici informe également le conditionnement afin que la fluidité du mouvement et l'alignement audio utilisent la même horloge.
Invite Dans "Invite", chargez l'encodeur de texte LTX avec LTXAVTextEncoderLoader (#316), puis écrivez votre description positive dans CLIPTextEncode (#303) et les traits indésirables dans CLIPTextEncode (#312). Le nœud LTXVConditioning (#304) fusionne le conditionnement positif et négatif et ajoute le taux de trame choisi pour que l'orientation temporelle corresponde à votre fps. Traitez l'invite positive comme un brief de prise de vue : sujet, caméra, éclairage, ambiance et indices de style. Gardez la liste négative axée sur les artefacts que vous voyez régulièrement et que vous souhaitez supprimer.
Modèle Le groupe "Modèle" charge le point de contrôle principal via CheckpointLoaderSimple (#315) et applique un Sulphur 2 LoRA avec LoraLoaderModelOnly (#285) pour infuser une texture cinématographique et une fidélité de personnage. C'est ici que vous pouvez échanger des points de contrôle ou des LoRAs pour changer l'apparence générale et les prioris de mouvement. La sortie du modèle est acheminée vers les guides initiaux et de raffinement pour que le style et l'identité soient cohérents à travers les passes. Associer LTX-2.3 avec Sulphur 2 donne un contraste percutant et des visages détaillés qui se lisent bien en mouvement.
Conversion de nombre Les expressions utilitaires convertissent votre fps et secondes en nombre entier de trames utilisé en aval. Cela garde les lignes de temps audio et vidéo alignées sans calcul manuel. Si vous réviser le fps ou la durée plus tard, le graphique met à jour automatiquement les nœuds dépendants.
Latent Vide "Latent Vide" crée des conteneurs alignés pour la génération : EmptyLTXVLatentVideo (#295) définit la taille spatiale et la longueur du latent vidéo, LTXVEmptyLatentAudio (#305) alloue le latent audio au même taux de trame, et LTXVConcatAVLatent (#321) les fusionne en un seul latent AV. Partir de latents vides garantit que le passage de diffusion reflète pleinement votre invite et conditionnement plutôt que tout contenu préexistant.
Générer Basse Résolution La première étape d'échantillonnage établit le mouvement et la composition à moindre coût. CFGGuider (#313), KSamplerSelect (#291), et ManualSigmas (#306) régissent la force avec laquelle l'invite dirige la génération et le calendrier de bruit global. SamplerCustomAdvanced (#283) débruite ensuite le latent AV en un clip cohérent. Le résultat est divisé par LTXVSeparateAVLatent (#307), et LTXVCropGuides (#284) affine l'attention spatiale pour que le cadrage du sujet souhaité soit préservé lors de la mise à l'échelle ultérieure.
Mise à l'échelle Latente LTXVLatentUpsampler (#287) utilise l'upscaler x2 LTX-2.3 pour augmenter le détail spatial tout en restant dans l'espace latent pour la rapidité et la stabilité. Alimenter le latent vidéo mis à l'échelle vers l'avant améliore la texture et la lisibilité avant le raffinement haute résolution. Cela préserve le mouvement que vous avez aimé de la première passe tout en ouvrant de la marge pour des bords plus nets et des matériaux plus riches.
Générer Haute Résolution Le latent vidéo mis à l'échelle est rejoint avec le latent audio dans LTXVConcatAVLatent (#278) et guidé à nouveau pour la qualité finale. CFGGuider (#282), KSamplerSelect (#280), et ManualSigmas (#281) donnent le dernier mot sur la force de l'invite, le détail et la cohérence temporelle, avec SamplerCustomAdvanced (#308) produisant le latent AV raffiné. LTXVSeparateAVLatent (#309) remet la vidéo à VAEDecodeTiled (#314) pour un décodage de trames adapté à la mémoire et l'audio à LTXVAudioVAEDecode (#297) pour la reconstruction de forme d'onde. CreateVideo (#310) muxe les trames et l'audio à votre fps cible, et SaveVideo (#75) écrit un fichier MP4/H.264.
Prétraitement d'Image Cette zone achemine les modèles de VAE de base et d'upscaler de manière à ce que le carrelage et la mise à l'échelle latente fonctionnent dans votre budget VRAM. Si vous subissez une pression mémoire, privilégiez les poids LTX-2.3 FP8 et gardez le décodage carrelé activé pour maintenir le débit et la qualité.
Nœuds clés dans le workflow Comfyui LTX 2.3 Sulphur 2 texte à vidéo#
LTXVConditioning (#304) Fusionne le conditionnement de texte positif et négatif et attache le taux de trame de travail pour que l'orientation temporelle corresponde à votre rendu. Un langage de scène fort et spécifique améliore la structure des plans; des négatifs concis réduisent les artefacts. Voir la carte du modèle LTX-2.3 pour les notes de conditionnement. Hugging Face: Lightricks/LTX-2.3
LTXVCropGuides (#284) Dirige doucement la composition pour garder le sujet principal cadré comme prévu. Utilisez-le pour protéger la taille du visage, le placement de l'horizon, ou un sujet centré avant la mise à l'échelle et le raffinement. Il est particulièrement utile pour les plans de type dialogue et les plans rapprochés moyens.
CFGGuider (#313, #282) Contrôle la façon dont l'invite influence agressivement la trajectoire de diffusion dans les deux passes. Utilisez le premier guide pour verrouiller le mouvement et la mise en scène, puis le second pour ajouter de la netteté sans s'éloigner du plan établi.
ManualSigmas (#306, #281) Définit le calendrier de bruit. Chargement frontal de plus de bruit encourage une exploration de mouvement plus large; un calendrier plus doux met l'accent sur la cohérence temporelle. Gardez les calendriers basse résolution et haute résolution complémentaires plutôt qu'identiques.
LTXVLatentUpsampler (#287) Effectue une mise à l'échelle latente x2 en utilisant l'upscaler LTX officiel pour que vous gagniez en détail avant l'échantillonneur de raffinement. Changer pour une autre variante d'upscaler LTX-2.3 peut légèrement modifier la netteté et le grain. Hugging Face: Lightricks/LTX-2.3
VAEDecodeTiled (#314) Décode des clips longs ou grands en tuiles gérables pour éviter les pics de VRAM. Si vous changez la taille spatiale ou la longueur du clip, ajustez le carrelage pour équilibrer la marge mémoire et la vitesse de décodage.
LoraLoaderModelOnly (#285) Applique le Sulphur 2 LoRA au chemin du modèle de base afin que la fidélité des personnages et les indices de style soient transférés dans les deux étapes d'échantillonnage. Utilisez ceci pour changer rapidement de look tout en gardant la même base LTX-2.3. Hugging Face: SulphurAI/Sulphur-2-base
Extras optionnels#
- Contrôle de la graine : définissez des valeurs fixes dans les deux nœuds
RandomNoisepour que les prises soient reproductibles; changez une graine pour explorer des alternatives. - Invites : écrivez des invites comme des directions de prise de vue (sujet, caméra, éclairage, ambiance). Gardez la liste négative ciblée et courte.
- Performance : si la VRAM est limitée, préférez les poids LTX-2.3 FP8 et gardez le décodage carrelé activé.
- Sortie : le graphique écrit en MP4/H.264; changez de conteneur ou de codec dans
SaveVideosi vous avez besoin de workflows proxy ProRes.
Ce workflow de texte à vidéo LTX 2.3 Sulphur 2 offre un chemin propre, de bout en bout, de l'invite à la vidéo polie avec audio synchronisé, conçu pour une itération rapide sur l'animation de personnages cinématographiques.
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement RunningHub pour le Workflow de Base Sulphur2 pour la Production Vidéo, SulphurAI pour le modèle de base Sulphur-2, Lightricks pour les modèles LTX-2.3 et LTX-2.3-fp8, et Comfy-Org pour l'encodeur de texte LTX-2 pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- RunningHub/Sulphur2 Basic Workflow for Video Production
- Docs / Notes de version : Sulphur2 Basic Workflow for Video Production
- SulphurAI/Sulphur-2-base
- Hugging Face : SulphurAI/Sulphur-2-base
- Lightricks/LTX-2.3
- GitHub : Lightricks/LTX-2
- Hugging Face : Lightricks/LTX-2.3
- arXiv : LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Lightricks/LTX-2.3-fp8
- GitHub : Lightricks/LTX-2
- Hugging Face : Lightricks/LTX-2.3-fp8
- arXiv : LTX-2: Efficient Joint Audio-Visual Foundation Model (2601.03233)
- Comfy-Org/ltx-2
- Hugging Face : Comfy-Org/ltx-2
Note : L'utilisation des modèles référencés, des jeux de données et du code est soumise aux licences respectives et aux conditions fournies par leurs auteurs et mainteneurs.
