
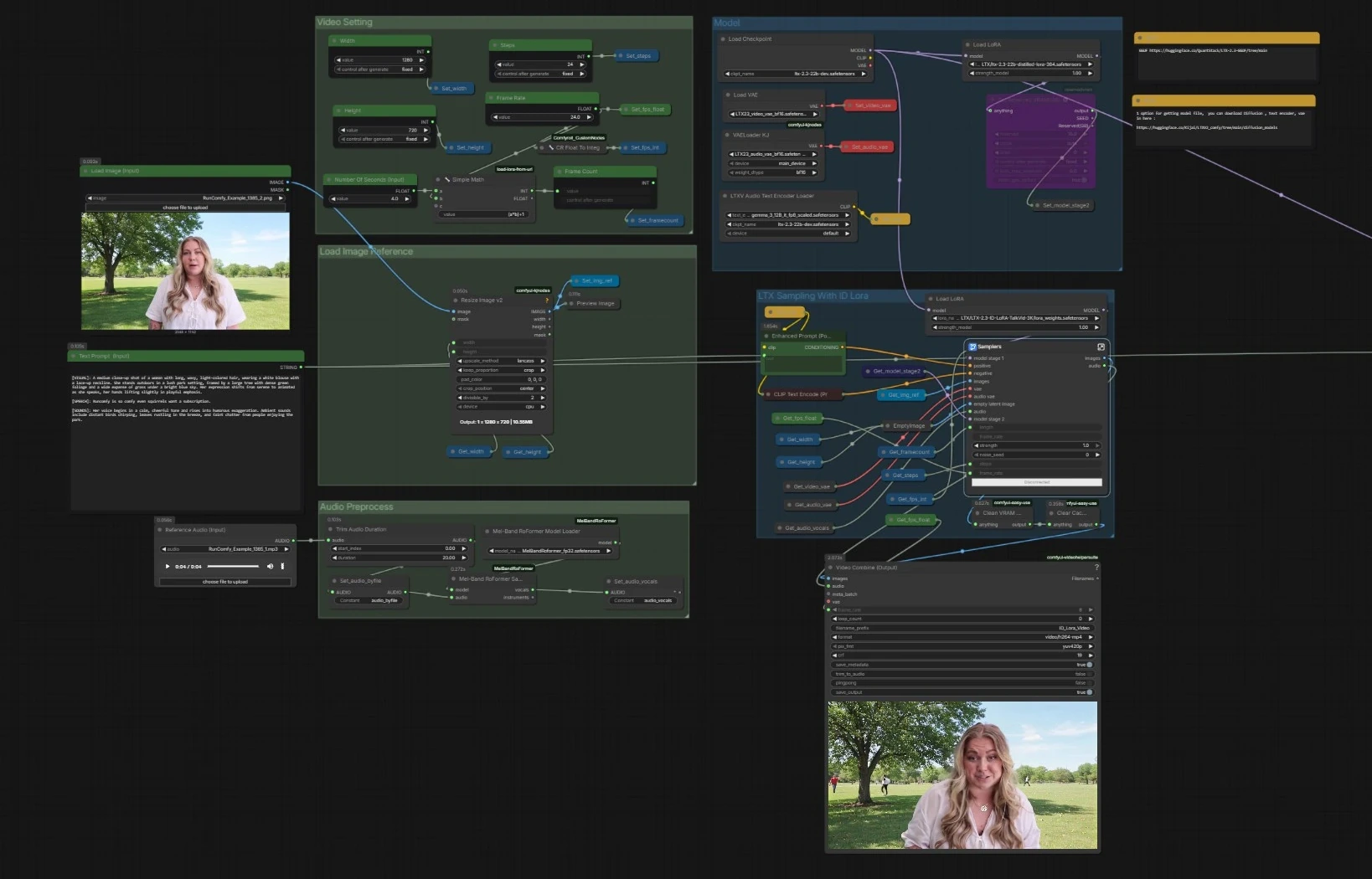
Workflow vidéo‑parlant LTX 2.3 ID-LoRA pour ComfyUI#
Ce workflow transforme une seule image de visage, un court clip vocal, et une invite en une vidéo parlante entièrement synchronisée. Construit sur LTX‑2.3, il fusionne l'audio et les visuels dans un processus de diffusion unique et ajoute un adaptateur d'identité In‑Context LoRA pour que la personne de votre image de référence reste cohérente sur tous les cadres. LTX 2.3 ID-LoRA est idéal pour les avatars, les hôtes virtuels et tout scénario où la synchronisation labiale, la ressemblance et le contrôle de l'invite doivent s'aligner en une seule passe.
Vous fournissez trois éléments : une image de référence, une ou deux phrases d'audio, et une invite textuelle décrivant l'apparence et la performance. Le chemin LTX 2.3 ID-LoRA gère l'identité tandis qu'un préprocesseur audio léger améliore la clarté vocale pour des indices buccaux plus forts. Le résultat est une vidéo cohérente, préservant l'identité avec un discours synchronisé qui ne nécessite pas d'entraînement par sujet.
Modèles clés dans le workflow Comfyui LTX 2.3 ID-LoRA#
- Checkpoint de base Lightricks LTX‑2.3 22B. Le modèle de fondation audio‑vidéo conjoint qui génère des cadres et sons synchronisés à partir du texte, de l'image et de l'audio. C'est le générateur principal utilisé par ce pipeline ComfyUI. Model card
- LTX‑2.3 LoRA distillé 384. Adaptateur LoRA officiel qui applique des conseils distillés au modèle de base pour stabiliser et accélérer l'échantillonnage sans sacrifier la qualité. Il est branché en tant que modèle de deuxième étape dans ce workflow. Voir le tableau des checkpoints sur la page LTX‑2.3. Model card
- Sur-échantillonneur spatial LTX‑2.3 x2. Sur-échantillonneur d'espace latent utilisé dans le sous-graphe de l'échantillonneur pour élever le détail spatial avant le décodage, améliorant la fidélité des visages et des bords dans la vidéo finale. Model card
- Encodeur de texte Instruct Gemma 3 12B pour LTX‑2.3. Fournit le conditionnement textuel qui pilote le style, la scène et la performance. Ce workflow utilise l'encodeur Gemma 3 empaqueté pour LTX‑2 dans ComfyUI. Comfy‑Org text encoders
- VAEs LTX‑2.3 pour vidéo et audio. VAEs conçus sur mesure qui décodent les latents visuels et acoustiques produits par le modèle en images et en une forme d'onde. Les constructions compatibles bf16 sont référencées dans le graphe. Sources d'exemple : Video VAE · Audio VAE
- RoFormer de bande de Mel pour la séparation vocale. Préprocesseur optionnel qui extrait les voix claires de l'audio de référence afin que le modèle puisse suivre les syllabes et les formes buccales plus fiablement. Paper · ComfyUI node
- LTX 2.3 ID‑LoRA (IC‑LoRA). Un LoRA d'identité in‑context entraîné pour l'utilisation de vidéo parlante qui incline le générateur vers le visage de votre image de référence tout en respectant les indices d'invite et de voix. Lightricks documente l'utilisation de LoRA et IC‑LoRA avec LTX‑2.3 sur la page du modèle. Model card
Comment utiliser le workflow Comfyui LTX 2.3 ID-LoRA#
Flux global. Le pipeline charge la base LTX‑2.3 avec des encodeurs de texte et des VAEs, prépare votre image et votre audio, puis exécute un échantillonneur LTX à deux étapes qui combine le texte, la référence faciale et une piste vocale pour générer des cadres et un discours synchronisés. Un échantillonneur parallèle sans ID‑LoRA est inclus pour des comparaisons rapides. Les cadres finaux et l'audio sont multiplexés en un MP4.
- Modèle
- Le graphe charge le checkpoint de base avec
CheckpointLoaderSimple(#5493), les encodeurs de texte basés sur Gemma viaLTXAVTextEncoderLoader(#5494), et les VAEs dédiés pour la vidéoVAELoader(#5651) et l'audioVAELoaderKJ(#5649). Il applique ensuite deux adaptateurs : le LoRA distillé officiel pour former un modèle de deuxième étape et le LTX 2.3 ID-LoRA pour le conditionnement de l'identité viaLoraLoaderModelOnly(#5573). - Cette étape garantit que le générateur comprend votre invite, a les bonnes piles de décodage, et est optimisé avec à la fois des conseils d'efficacité et un biais d'identité.
- Vous ne modifiez généralement rien ici au-delà de l'échange de checkpoints ou de LoRAs si vous avez des alternatives.
- Le graphe charge le checkpoint de base avec
- Réglage Vidéo
- Contrôle les dimensions de sortie, la fréquence d'images, les étapes, et la durée.
Width(#5284),Height(#5286), etFrame Rate(#5289) alimentent un petit utilitaire qui calcule le nombre total de cadres à partir des secondes, maintenant une synchronisation cohérente entre l'audio et la vidéo. - Les paramètres sont stockés une fois et lus par tous les nœuds en aval pour que les deux échantillonneurs et le multiplexeur restent alignés.
- Ajustez ces valeurs d'abord lorsque vous voulez un aspect, une fluidité ou une durée différente.
- Contrôle les dimensions de sortie, la fréquence d'images, les étapes, et la durée.
- Charger l'Image de Référence
- Fournissez une seule image de visage claire via
Load Image (Input)(#5525). L'image est redimensionnée avecImageResizeKJv2(#5280) pour correspondre à votre sortie choisie. - Cette image prétraitée devient l'ancre pour l'identité dans l'étape LTX 2.3 ID-LoRA, guidant la ressemblance et la composition du plan.
- Utilisez une photo bien éclairée, frontale avec un flou de mouvement minimal pour de meilleurs résultats.
- Fournissez une seule image de visage claire via
- Prétraitement Audio
- Déposez un court WAV ou MP3 en utilisant
Reference Audio (Input)(#5652). Le clip est coupé si nécessaire puis passé àMelBandRoFormerSampler(#5473) pour isoler les voix. - Les voix claires aident le modèle à déduire les phonèmes et le timing pour des mouvements labiaux précis et un rythme de discours.
- Si votre audio est déjà uniquement vocal, vous pouvez sauter la séparation et l'alimenter directement.
- Déposez un court WAV ou MP3 en utilisant
- Échantillonnage LTX Avec ID Lora
- C'est le chemin principal. Le sous-graphe de l'échantillonneur (
Samplers(#5278)) mélange votre invite positive deEnhanced Prompt (Positive)(#5174), la liste négative, la référence faciale, et la piste vocale à travers le pipeline latent AV de LTX‑2.3. LTXVReferenceAudioaligne le mouvement avec le discours tandis queLTXVImgToVideoInplaceinjecte l'image faciale dans le latent comme ancre. L'adaptateur LTX 2.3 ID-LoRA oriente le générateur vers l'identité de votre sujet.- L'étape comprend un sur-échantillonneur latent interne pour élever le détail avant le décodage. Il produit des cadres plus un flux audio synchronisé.
- C'est le chemin principal. Le sous-graphe de l'échantillonneur (
- Échantillonnage LTX Sans ID Lora
- Un échantillonneur miroir (
Samplers(#5643)) exécute le même conditionnement mais sans l'adaptateur ID‑LoRA. Utilisez ceci pour des vérifications A/B ou lorsque vous voulez plus de liberté par rapport à l'identité de référence. - Tout le reste reste identique, donc les différences que vous remarquez sont dues uniquement au conditionnement de l'identité.
- Ce chemin peut être utile pour des brouillons rapides ou des départs créatifs.
- Un échantillonneur miroir (
- Combiner et Sortir Vidéo
- Les cadres et l'audio généré sont multiplexés en MP4 avec
Video Combine (Output)(#5218). Le taux de trame provient de votre paramètre global, donc le mouvement et la synchronisation labiale correspondent au timing de l'échantillonneur. - Le
Video Combinesecondaire (#5645) prévisualise la branche sans ID‑LoRA si vous l'avez activée, ce qui est utile pour des comparaisons. - Le workflow nettoie le cache entre les exécutions pour garder la VRAM stable sur de longues sessions.
- Les cadres et l'audio généré sont multiplexés en MP4 avec
Nœuds clés dans le workflow Comfyui LTX 2.3 ID-LoRA#
LoraLoaderModelOnly(#5573)- Charge le LTX 2.3 ID-LoRA qui préserve l'identité faciale. Réduisez son poids si vous voulez plus de variance créative ou augmentez-le pour verrouiller la ressemblance plus étroitement. Associez-le judicieusement avec la force de l'invite pour que l'identité et le style ne se concurrencent pas. Référence : utilisation de LoRA LTX‑2.3 sur la page du modèle. Model card
LTXVReferenceAudio(#5589)- Convertit votre audio de référence en conditionnement pour le timing des syllabes, la prosodie, et les formes buccales. Fournissez un discours clair pour le meilleur alignement. Si vous entendez des pompages ou une articulation décalée, raccourcissez ou simplifiez le clip plutôt que de renforcer la force.
LTXVImgToVideoInplace(#5245, aussi utilisé plus tard)- Injecte l'image faciale dans le flux vidéo latent comme un préalable spatial. Le contrôle de la force de l'image équilibre l'adhérence à la photo par rapport à la liberté de mouvement. Pour une forte identité avec un mouvement naturel, gardez la force de l'image modérée et laissez l'ID‑LoRA porter la ressemblance.
LTXVConditioning(#5621)- Emballe le conditionnement textuel et les indices de timing pour les échantillonneurs LTX. Assurez-vous que son entrée de fréquence d'images correspond à votre fréquence d'images de sortie pour que les champs de mouvement et le timing des phonèmes restent cohérents.
VHS_VideoCombine(#5218)- Multiplexe les cadres et l'audio dans le fichier final. Si votre audio est légèrement plus long que les cadres, activez le découpage ici pour éviter une queue noire traînante. Pour la compatibilité des plateformes, gardez les paramètres H.264 par défaut sauf si vous avez une raison de les changer. Référence de nœud : ComfyUI‑VideoHelperSuite
MelBandRoFormerSampler(#5473)- Sépare les voix de la musique en utilisant un transformateur de bande de Mel pour que le générateur se verrouille sur le discours. Si les sibilantes se mélangent ou les plosives éclatent, essayez un fichier modèle différent de la même famille ou réduisez la sonorité d'entrée. Lecture de fond : arXiv
Extras optionnels#
- Pour les générations les plus stables avec LTX‑2.3, utilisez une largeur et une hauteur divisibles par 32 et choisissez un nombre de cadres de 8n + 1 comme documenté par Lightricks. Model card
- Gardez l'image de référence cohérente avec votre invite. Si vous décrivez un éclairage extérieur mais fournissez une photo intérieure, l'identité peut se maintenir tandis que la couleur et l'ombrage luttent contre l'invite.
- Donnez à l'audio 2 à 8 secondes avec un rythme naturel. Les clips trop compressés ou réverbérants réduisent la fidélité de la synchronisation labiale même après la séparation vocale.
- Lorsque les visages dérivent, réduisez légèrement la force de l'image et reposez-vous davantage sur le LTX 2.3 ID-LoRA. Lorsque les visages errent trop, faites l'inverse.
- Pour des prises plus longues, générez en segments qui partagent la même graine et les mêmes paramètres globaux, puis joignez les clips en montage vidéo si nécessaire.
Références et dépôts utiles#
- Poids ouverts LTX‑2.3 et notes : Page du modèle Hugging Face
- Nœuds ComfyUI officiels pour la vidéo LTX : Lightricks/ComfyUI‑LTXVideo
- Codebase et article LTX‑2 : Lightricks/LTX‑Video · arXiv
- Encodeurs IT Gemma 3 12B pour LTX dans ComfyUI : Comfy‑Org/ltx‑2 text_encoders
- Fond RoFormer de bande de Mel : arXiv
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement les créateurs de LTX 2.3 ID-LoRA Source pour le workflow LTX 2.3 ID-LoRA Source pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- LTX 2.3 ID-LoRA Source
- Docs / Notes de version : YouTube @Benji’s AI Playground
Note : L'utilisation des modèles, jeux de données, et code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.