
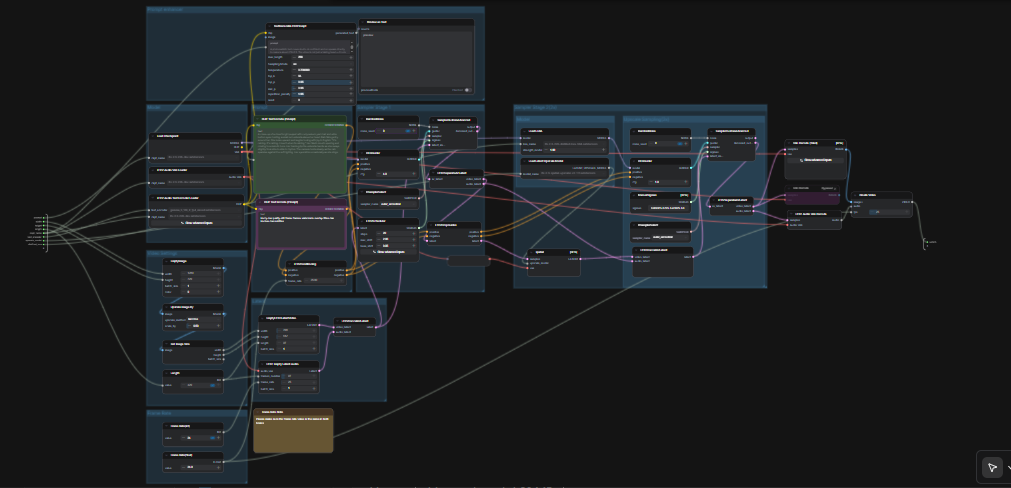
LTX 2.3 ComfyUI : Texte-à-Vidéo avec audio propre, échantillonnage en deux étapes et suréchantillonnage spatial 2×#
Ce workflow LTX 2.3 ComfyUI transforme des invites courtes en vidéos cinématiques polies avec un audio synchronisé. Il est construit autour du modèle LTX‑2.3 de Lightricks et configuré pour une haute cohérence visuelle, un mouvement stable et une sortie adaptée à la diffusion. Les créateurs, éditeurs et artistes techniques peuvent passer d'une seule invite à un MP4 avec audio en une seule passe, en utilisant un graphe simplifié qui inclut un amplificateur d'invite, deux étapes d'échantillonnage, et un suréchantillonneur latent 2×.
Comparé aux configurations typiques de texte-à-vidéo, ce graphe met l'accent sur la consistance des scènes et la fidélité de l'invite. Le chemin par défaut génère un latent AV, le suréchantillonne dans l'espace latent pour un détail plus net, puis le décode en images et audio avant d'emballer le tout dans un fichier vidéo prêt à partager. Si vous explorez des modèles vidéo open-source modernes, ce workflow LTX 2.3 ComfyUI est un moyen rapide d'obtenir un mouvement de qualité production.
Modèles clés dans le workflow Comfyui LTX 2.3 ComfyUI#
- Checkpoint LTX‑2.3 22B (dev) par Lightricks. Le modèle de texte-à-vidéo principal qui produit un mouvement à haute cohérence et une forte consistance de scène. Hugging Face • GitHub
- Encodeur de texte Instruct Gemma 3 12B (FP4 mixte). Fournit une compréhension linguistique robuste pour un meilleur ancrage de l'invite et des détails de scène plus riches. Hugging Face
- Suréchantillonneur Spatial LTX‑2.3 x2 1.0. Un suréchantillonneur de l'espace latent qui affine le détail spatial sans compromettre la consistance du mouvement. Hugging Face
- LTX‑2.3 22B Distilled LoRA (384). Un adaptateur distillé qui affine la fidélité de la texture et stabilise le style pendant l'étape de suréchantillonnage/raffinement. Hugging Face
- LTX Audio VAE. Le module audio associé à LTX‑2.3 qui permet une génération sonore propre et synchronisée à partir de la même invite. Hugging Face
Comment utiliser le workflow Comfyui LTX 2.3 ComfyUI#
Le graphe fonctionne en deux passes coordonnées. D'abord, il génère un latent AV à une résolution de travail avec votre invite. Ensuite, il effectue un suréchantillonnage latent 2× et une seconde passe d'échantillonnage avec un LoRA distillé avant de décoder en images et audio, enfin de muxer en MP4.
Amplificateur d'invite#
Le noeud TextGenerateLTX2Prompt (#149) réécrit le langage simple en une invite adaptée au modèle qui couvre les actions, les visuels et les indices audio. Donnez-lui votre description de scène ; des images de référence optionnelles peuvent être connectées lorsque vous souhaitez des conseils pour le cadrage ou le style. Le texte généré est acheminé vers un encodeur positif tandis qu'une invite négative axée sur la qualité réduit les artefacts. Cet équilibre aide le modèle LTX‑2.3 à rester sur le sujet sans trop contraindre la créativité.
Modèle#
Le CheckpointLoaderSimple (#146) charge le checkpoint LTX‑2.3 22B et expose à la fois le modèle et son VAE. LTXAVTextEncoderLoader (#147) introduit l'encodeur de texte Gemma 3 12B Instruct que le workflow utilise pour le conditionnement positif et négatif. Conservez ces sélections sauf si vous testez d'autres variantes LTX, car le reste du graphe est optimisé pour cet appariement.
Paramètres Vidéo#
La résolution et la durée sont définies avec un cadre d'image léger et le contrôle Length. Le graphe lit la taille de l'image, la met à l'échelle pour une résolution de travail, et transmet ces valeurs au créateur de latent vidéo. Les modèles LTX ont des contraintes de pas ; respectez les tailles qui suivent un motif de pas de 32 et les durées qui s'alignent avec la cadence des images du modèle. Le graphe ajustera doucement les valeurs illégales aux plus proches valides, mais choisir des tailles valides dès le départ donne la meilleure composition.
Fréquence d'Image#
Deux petits contrôles définissent le FPS pour le conditionnement et l'encodage final : Frame Rate(int) (#141) et Frame Rate(float) (#140). Gardez-les identiques pour que le timing du mouvement et l'alignement audio restent cohérents tout au long du pipeline. Choisissez un taux cinématographique si vous souhaitez un mouvement plus fluide ou respectez les valeurs par défaut de la plateforme lorsque vous ciblez des formats sociaux.
Latent#
EmptyLTXVLatentVideo (#121) initialise le latent vidéo et LTXVEmptyLatentAudio (#119) fait de même pour l'audio. LTXVConcatAVLatent (#122) les fusionne en un seul latent AV afin que l'orientation textuelle puisse guider les deux modalités ensemble. LTXVConditioning (#120) attache un conditionnement positif et négatif, et LTXVCropGuides (#115) adapte l'orientation à la disposition spatiale du latent pour un cadrage plus fiable.
Échantillonneur Étape 1#
Cette étape crée le latent AV initial en utilisant RandomNoise (#151), KSamplerSelect (#144), et le LTXVScheduler (#112) conscient de LTX avec un CFGGuider (#139). Le planificateur est conçu pour LTX pour équilibrer la stabilité temporelle avec le respect de l'invite. Si vous souhaitez plus de variations, changez la graine de bruit ; pour un respect plus strict du script, privilégiez les échantillonneurs qui maintiennent la cohérence temporelle.
Modèle (LoRA)#
LoraLoaderModelOnly (#143) applique le LoRA distillé LTX‑2.3 avant le raffinement. Cet adaptateur améliore subtilement le polissage de la texture et la fidélité du style sans perdre la cohérence du mouvement. Il est le plus visible sur la peau, les tissus et les reflets spéculaires.
Échantillonnage de Suréchantillonnage (2×)#
LTXVLatentUpsampler (#130) effectue un suréchantillonnage spatial 2× dans l'espace latent en utilisant le LatentUpscaleModelLoader (#114) chargé et le VAE de base. Comme le suréchantillonnage se produit avant le décodage, vous conservez la fluidité temporelle tout en gagnant en détail spatial fin. Les latents vidéo et audio suréchantillonnés sont ensuite regroupés avec LTXVConcatAVLatent (#129) pour la passe de raffinement.
Échantillonneur Étape 2 (2×)#
La seconde passe affine le latent suréchantillonné en utilisant RandomNoise (#127), KSamplerSelect (#145), et un plan ManualSigmas (#113) sous un CFGGuider (#116). Cette étape est là où les micro-détails et la netteté des bords sont finalisés. Cela fonctionne mieux lorsque le LoRA est actif et que l'invite est spécifique sur les textures et l'éclairage.
Décodage et Sortie#
LTXVSeparateAVLatent (#135) sépare le latent raffiné pour que VAEDecodeTiled (#137) puisse reconstruire les images tandis que LTXVAudioVAEDecode (#138) restaure l'audio. CreateVideo (#133) muxe les images et l'audio au FPS choisi, et le noeud de haut niveau SaveVideo écrit un MP4 dans le dossier vidéo du workflow. Le résultat est un fichier propre, prêt à partager, produit entièrement à l'intérieur du pipeline LTX 2.3 ComfyUI.
Noeuds clés dans le workflow Comfyui LTX 2.3 ComfyUI#
TextGenerateLTX2Prompt(#149) : Convertit des descriptions simples en invites structurées qui couvrent le mouvement, les attributs visuels et l'audio. Modifiez d'abord votre formulation ici lorsque vous orientez les rythmes de l'histoire ou le rythme ; cela donne généralement de plus grands gains que les ajustements d'échantillonneur.LTXVScheduler(#112) : Un planificateur spécifique à LTX qui façonne la façon dont le bruit est supprimé au fil du temps. Associez-le judicieusement à l'échantillonneur choisi pour équilibrer la stabilité temporelle et la fidélité de l'invite.LTXVLatentUpsampler(#130) : Effectue un suréchantillonnage spatial 2× directement dans l'espace latent, préservant la continuité du mouvement tout en ajoutant des détails nets. Utilisez-le lorsque vous souhaitez des résultats plus nets sans recourir à des suréchantillonneurs post-décodage.LoraLoaderModelOnly(#143) : Applique le LoRA distillé LTX‑2.3 pour le raffinement. Augmentez l'influence pour un contrôle de style plus serré ; réduisez-la si vous souhaitez un look plus large du modèle de base.CreateVideo(#133) : Muxe les images décodées avec l'audio généré au FPS sélectionné pour que le timing et la synchronisation labiale restent intacts. Si vous changez le FPS, gardez les deux contrôles de fréquence d'image appariés.
Extras optionnels#
- Conseils d'invite : Décrivez les actions au fil du temps, énumérez les éléments visuels clés, et spécifiez le son ou le dialogue que vous attendez. Une formulation claire et concise donne au encodeur LTX‑2.3 le meilleur signal.
- Dimensions et durée : Privilégiez les tailles sur un pas de 32 et les durées qui respectent la cadence des images du modèle. Bien que le graphe ajuste automatiquement les valeurs proches, des entrées valides améliorent la composition et réduisent les légers tremblements.
- Itération rapide : Changez la graine de
RandomNoiseentre les exécutions pour explorer des variantes tout en gardant la même invite et les mêmes paramètres. - Changement de modèle : Les paramètres par défaut sont optimisés pour LTX‑2.3 22B avec Gemma 3 12B IT et le suréchantillonneur spatial 2×. Échangez des modèles uniquement si vous comprenez comment chacun affecte le conditionnement et le décodage.
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Lightricks pour le modèle LTX-2.3 et EyeForAILabs pour le tutoriel YouTube pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- Lightricks/LTX-2.3
- GitHub : Lightricks/LTX-2
- Hugging Face : Lightricks/LTX-2.3
- arXiv : 2601.03233
- EyeForAILabs/Tutoriel YouTube
- Docs / Notes de Version : Chaîne YouTube de @eyeforailabs
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.