



Qu'est-ce que le flux de travail ComfyUI LongCat Image texte à image?#
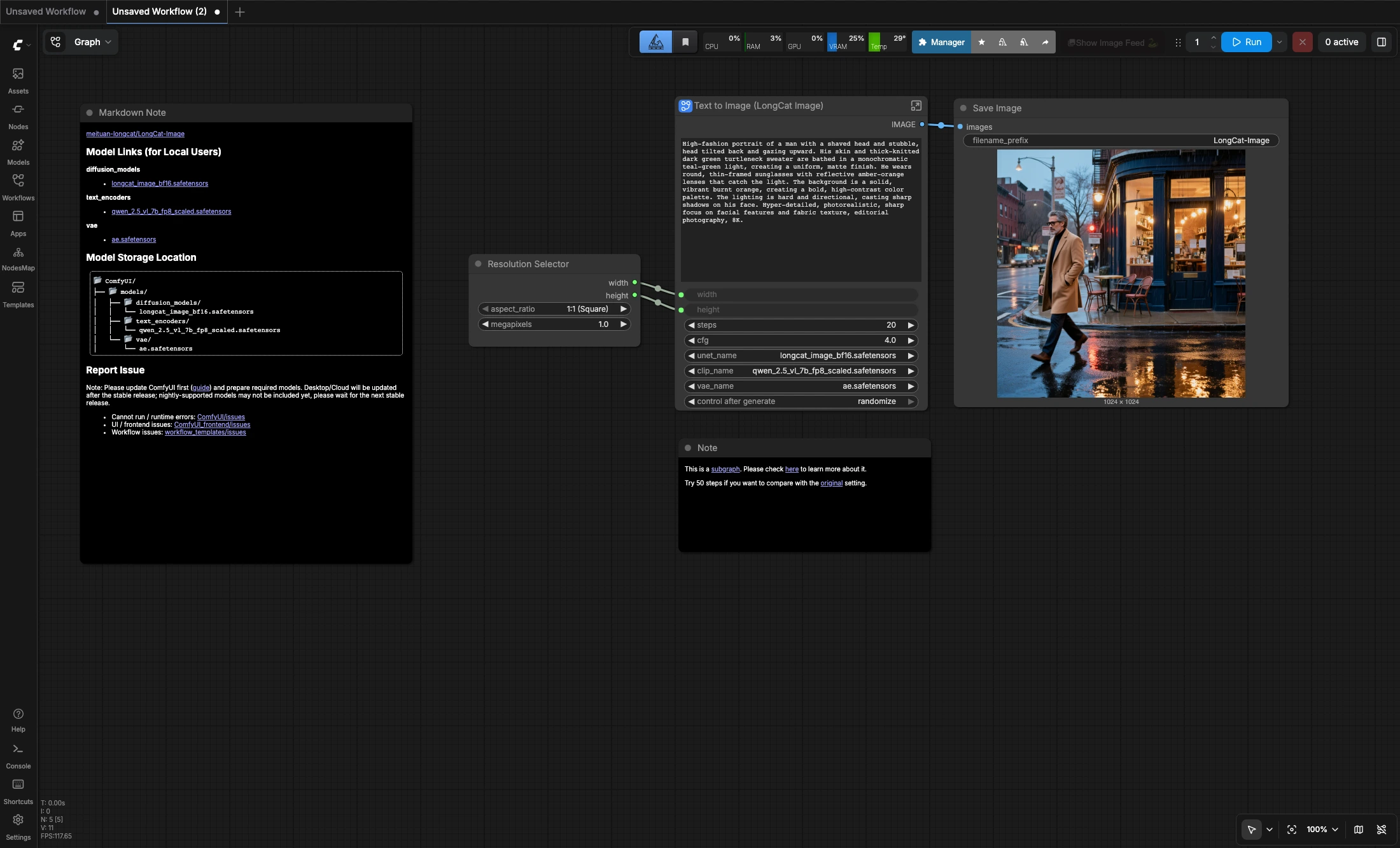
LongCat Image texte à image est un flux de travail ComfyUI compact pour générer des images carrées 1024x1024 à partir de suggestions textuelles. Il utilise le modèle de diffusion LongCat-Image avec l'encodeur de texte Qwen 2.5 VL et l'AE VAE, vous offrant une configuration directe du texte à l'image pour les portraits, les photos de produits et les visuels éditoriaux soignés.
Le graphe est intentionnellement simple : choisissez une résolution carrée, écrivez votre suggestion, exécutez le flux de travail et enregistrez l'image. Il fonctionne bien pour des itérations rapides avec des suggestions en anglais ou en chinois, et la note incluse suggère d'essayer 50 étapes si vous souhaitez comparer le résultat avec le réglage du modèle d'origine.
Caractéristiques principales de LongCat Image texte à image#
- Génération carrée en premier : La configuration par défaut est optimisée pour une sortie 1:1 à 1024x1024.
- Conception de flux de travail compact : Le graphe reste concentré sur la génération du texte à l'image sans complexité de routage supplémentaire.
- Suggestion flexible : Convient aux suggestions textuelles en anglais et en chinois.
- Réglage facile de la qualité : Commencez avec la configuration par défaut de 20 étapes, puis augmentez les étapes lorsque vous souhaitez un échantillonnage plus lent mais plus délibéré.
Comment utiliser LongCat Image dans ComfyUI#
- Choisissez la taille de sortie
- Utilisez le nœud
Resolution Selectorpour conserver la mise en page carrée par défaut ou ajuster les mégapixels cibles si nécessaire.
- Utilisez le nœud
- Écrivez votre suggestion
- Ouvrez le sous-graphe
Text to Image (LongCat Image)et remplacez la suggestion par défaut par vos propres instructions de sujet, d'éclairage, d'humeur et de composition.
- Ouvrez le sous-graphe
- Exécutez le flux de travail
- Placez le graphe en file d'attente pour générer une image unique à partir de votre suggestion.
- Enregistrez le résultat
- Le nœud
Save Imageécrit la sortie finale une fois l'exécution terminée.
- Le nœud
Conseils et paramètres#
- La configuration par défaut actuelle fonctionne à 20 étapes avec CFG 4.
- Si vous souhaitez comparer avec la recommandation originale du flux de travail source, essayez 50 étapes.
- Les suggestions claires et concrètes ont tendance à mieux fonctionner que les fragments de suggestion larges ou abstraits dans ce graphe compact.
Ressources#
- Source du flux de travail : Comfy.org workflow page
- Modèle officiel : meituan-longcat/LongCat-Image on Hugging Face