
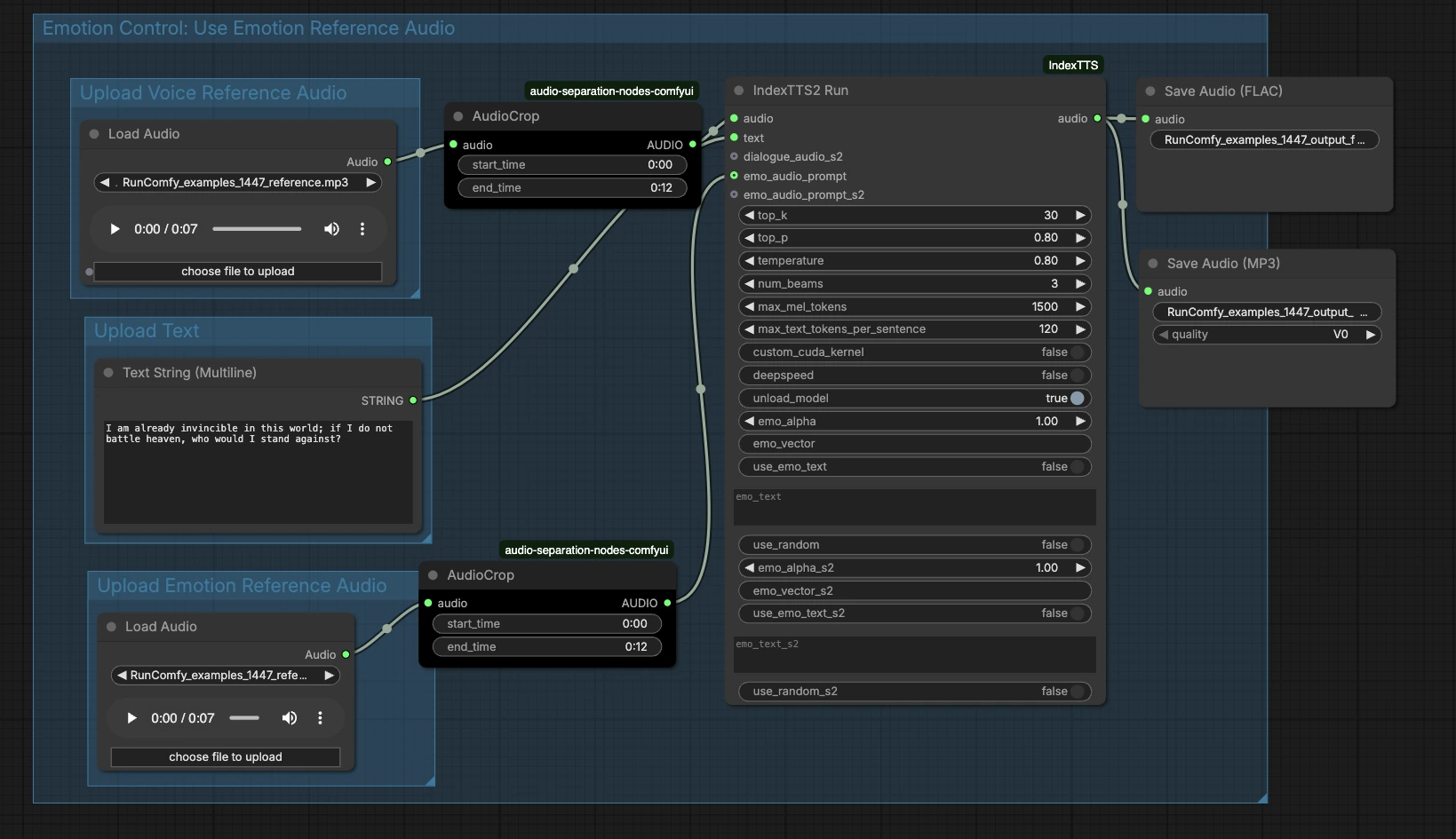
Flux de travail IndexTTS2 ComfyUI : Clonage de voix émotionnelle avec audio de référence#
Ce flux de travail IndexTTS2 ComfyUI transforme un court extrait de référence en un discours naturel et expressif qui correspond au timbre et au style du locuteur. Vous fournissez un audio de référence propre, une incitation émotionnelle optionnelle, et votre script ; le graphe génère des clones vocaux de haute qualité et les exporte en FLAC pour une utilisation archivistique ou en MP3 pour un partage rapide.
Construit autour du modèle IndexTTS‑2 et des nœuds ComfyUI IndexTTS, le flux de travail est idéal pour les créateurs, les concepteurs de personnages, les éducateurs, et les utilisateurs de RunComfy qui souhaitent un TTS émotionnel rapide et reproductible. Tout se passe à l'intérieur de ComfyUI, vous pouvez donc inspecter les entrées, ajuster les paramètres, et itérer rapidement sur des exemples de narration, de dialogue et de voix off.
Modèles clés dans le flux de travail IndexTTS2 ComfyUI#
- IndexTTS‑2 par IndexTeam. Un système de synthèse vocale moderne qui effectue le clonage vocal conditionné par référence et le contrôle de la prosodie expressive. Il se conditionne sur un court exemple de locuteur et éventuellement sur des indices émotionnels pour rendre un discours naturel à partir de texte. Voir la carte du modèle sur Hugging Face et l'article accompagnant pour des détails architecturaux et de formation : IndexTTS‑2, projet IndexTTS, article IndexTTS‑2.
Comment utiliser le flux de travail IndexTTS2 ComfyUI#
À un niveau élevé, le graphe prend trois entrées — audio de timbre de référence, texte, et audio émotionnel optionnel — puis exécute la génération et exporte le résultat. Les groupes ci-dessous montrent où ajouter les entrées et comment elles se connectent au discours final.
Télécharger l'audio de référence vocale#
Ce groupe prépare l'identité du locuteur. Chargez un échantillon propre de la voix cible dans LoadAudio (#13), idéalement un seul locuteur parlant clairement sans musique ni effets. Utilisez AudioCrop (#37) pour isoler un segment stable afin que le système apprenne un timbre cohérent. Les segments courts avec une hauteur stable et une livraison neutre produisent généralement le clonage le plus fiable. La référence recadrée est envoyée pour conditionner le générateur.
Télécharger le texte#
Entrez votre script dans PrimitiveStringMultiline (#14). Une ponctuation claire aide le modèle à déduire les pauses et l'accentuation, alors écrivez le texte comme vous voulez qu'il soit parlé. Si vous prévoyez des lectures multi-phrases, assurez-vous que chaque phrase est bien formée et évitez les émojis ou symboles peu communs. Le texte s'écoule directement dans le nœud de synthèse pour le rendu.
Télécharger l'audio de référence émotionnelle#
Fournissez un extrait optionnel qui capture l'émotion ou la livraison que vous souhaitez — par exemple excité, calme, ou sombre — via LoadAudio (#15). Coupez-le avec AudioCrop (#38) pour ne garder que la partie expressive que vous voulez imiter. Cela est séparé de la référence de timbre et se concentre sur le rythme, l'énergie et le ton. Si vous sautez cette étape, le flux de travail IndexTTS2 ComfyUI se basera uniquement sur le texte pour la prosodie.
Contrôle émotionnel : Utiliser l'audio de référence émotionnelle#
Cette zone connecte votre incitation émotionnelle au générateur. Le clip émotionnel recadré alimente l'entrée emo_audio_prompt sur IndexTTS2Run (#12), guidant la cadence et l'intensité tout en préservant la voix cible. Vous pouvez également utiliser les contrôles de texte émotionnel du nœud pour ajuster le style si vous n'avez pas d'exemple audio émotionnel. En pratique, l'audio émotionnel tend à donner une expressivité plus forte et plus cohérente, tandis que le texte émotionnel fournit une orientation plus légère. Combinez-les lorsque vous souhaitez à la fois un exemple concret et un indice textuel.
Générer et exporter#
IndexTTS2Run (#12) synthétise le discours en utilisant votre texte, référence de timbre, et toute orientation émotionnelle. La sortie s'achemine vers SaveAudio (#17) pour un FLAC sans perte et vers SaveAudioMP3 (#39) pour un aperçu web convivial et léger. Utilisez les champs de nom de fichier sur les nœuds de sauvegarde pour garder les prises organisées à travers les itérations. Ce design facilite l'A/B testing de différents textes ou émotions tout en conservant la même identité de locuteur.
Nœuds clés dans le flux de travail IndexTTS2 ComfyUI#
IndexTTS2Run (#12)#
C'est le générateur principal qui enveloppe IndexTTS‑2 et expose des contrôles pour l'échantillonnage, la recherche par faisceau, et le conditionnement émotionnel. Ajustez top_p, top_k, et temperature pour équilibrer stabilité et variété — des valeurs plus basses donnent des lectures plus cohérentes, des valeurs plus élevées augmentent la spontanéité. Utilisez num_beams lorsque vous souhaitez que le nœud recherche plus de lectures candidates, échangeant vitesse pour qualité. Pour les scripts longs, max_mel_tokens et max_text_tokens_per_sentence aident à prévenir les débordements en limitant les tailles de morceaux audio et texte. L'émotion peut être dirigée avec emo_audio_prompt, emo_alpha pour la force du mélange, ou avec use_emo_text et emo_text lorsque vous préférez un indice textuel. Des aides à la performance telles que deepspeed, custom_cuda_kernel, et unload_model sont disponibles selon votre matériel. L'implémentation du nœud est fournie par les nœuds personnalisés ComfyUI IndexTTS : ComfyUI_IndexTTS, et le modèle sous-jacent est documenté ici : IndexTTS‑2, projet IndexTTS.
AudioCrop (#37) — timbre de référence#
Utilisez ce nœud pour isoler un extrait propre et stable de votre échantillon de locuteur. Évitez les bruits de fond, le rire, ou une émotion extrême car ces détails peuvent se glisser dans la voix clonée. Recadrer à un ton cohérent améliore la fixation de l'identité et réduit les artefacts indésirables.
AudioCrop (#38) — incitation émotionnelle#
Ce recadrage sélectionne l'indice expressif qui contrôle la livraison. Choisissez une partie avec le rythme ou l'intensité exacte que vous souhaitez, et gardez-la concise pour éviter de diluer le signal. Pour une meilleure cohérence, utilisez des incitations émotionnelles du même locuteur que la référence de timbre lorsque possible.
Extras optionnels#
- Gardez l'audio de référence sec et monophonique ; retirez la réverbération, la musique de fond, et la compression lourde pour un clonage plus propre.
- Ponctuez intentionnellement. Les virgules, points et points d'interrogation aident le modèle à placer des pauses et des inflexions qui correspondent à votre intention.
- Pour des prises reproductibles, désactivez l'aléatoire dans le nœud ou gardez des notes sur les sélections de texte et d'audio pour pouvoir régénérer la même sortie plus tard.
- Si la VRAM est limitée, activez le déchargement du modèle entre les exécutions ; cela peut ajouter un petit coût en temps mais libère de la mémoire pour d'autres graphes.
- Respectez les droits de voix. N'utilisez que des enregistrements de référence que vous êtes autorisé à cloner et divulguez le discours synthétique là où c'est requis.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement RunningHub pour la référence du flux de travail, RunComfy pour le flux de travail Cloud Save, Index Team pour IndexTTS et IndexTTS-2, les auteurs de l'article IndexTTS2, et billwuhao pour les nœuds personnalisés ComfyUI IndexTTS pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux dépôts liés ci-dessous.
Ressources#
- RunningHub/Workflow Reference
- Docs / Notes de version : RunningHub post
- RunComfy/Cloud Save Workflow
- Docs / Notes de version : RunComfy workflow
- index-tts/index-tts
- GitHub : index-tts/index-tts
- IndexTeam/IndexTTS-2
- Hugging Face : IndexTeam/IndexTTS-2
- IndexTTS2/Paper
- arXiv : 2506.21619
- billwuhao/ComfyUI_IndexTTS
- GitHub : billwuhao/ComfyUI_IndexTTS
Note: L'utilisation des modèles, ensembles de données et du code référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.