
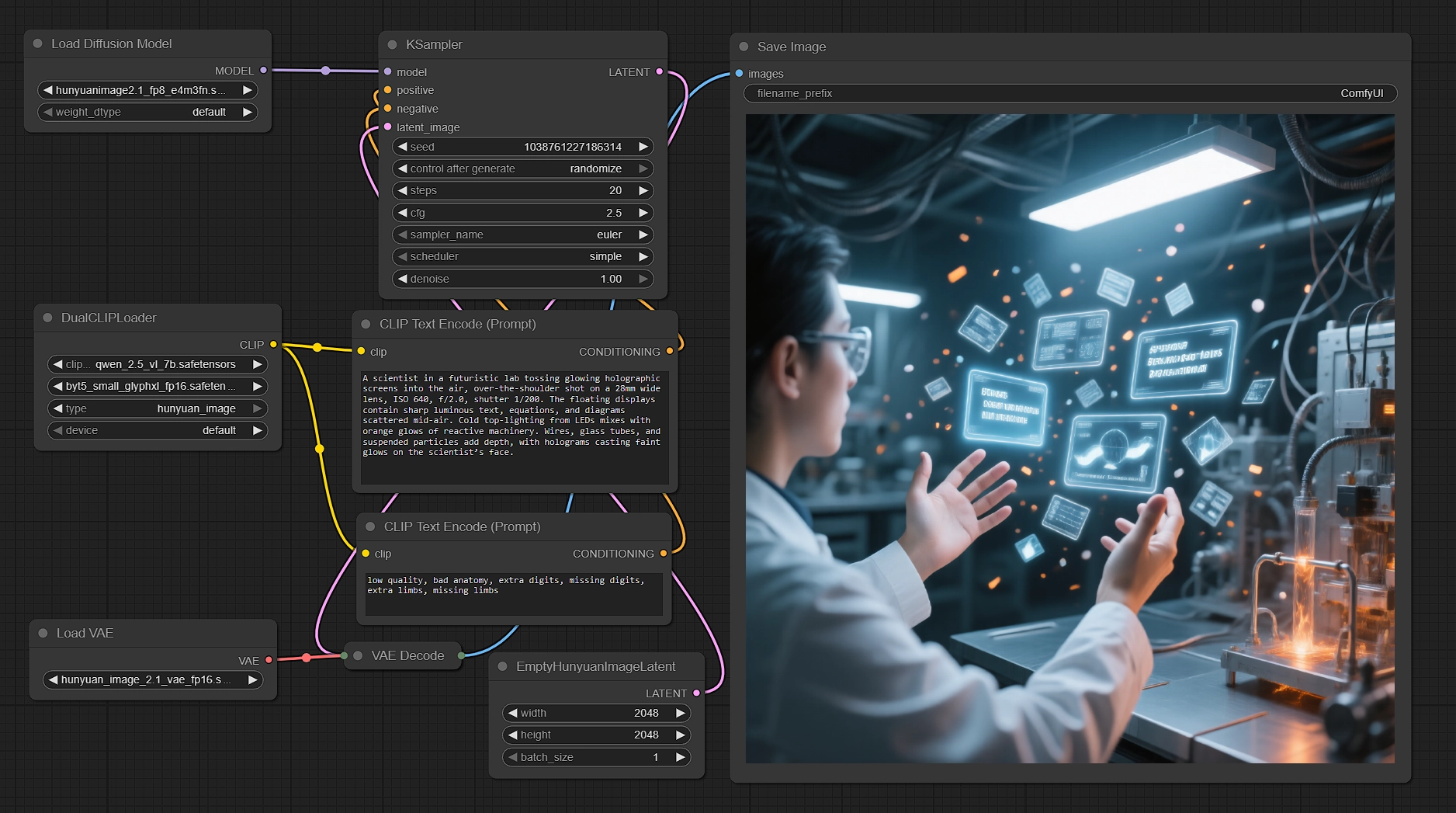










Générez des images natives 2K avec Hunyuan Image 2.1 dans ComfyUI#
Ce workflow transforme vos invites en rendus nets, natifs 2048×2048 en utilisant Hunyuan Image 2.1. Il associe le transformateur de diffusion de Tencent avec des encodeurs de texte doubles pour améliorer l'alignement sémantique et la qualité du rendu textuel, puis échantillonne efficacement et décode via le VAE de haute compression correspondant. Si vous avez besoin de scènes prêtes à la production, de personnages et de texte clair dans l'image en 2K tout en conservant la rapidité et le contrôle, ce workflow ComfyUI Hunyuan Image 2.1 est fait pour vous.
Les créateurs, directeurs artistiques et artistes techniques peuvent insérer des invites multilingues, affiner quelques réglages et obtenir systématiquement des résultats nets. Le graphe est fourni avec une invite négative sensée, une toile native 2K et un FP8 UNet pour garder la VRAM sous contrôle, montrant ce que Hunyuan Image 2.1 peut offrir dès la sortie de la boîte.
Modèles clés dans le workflow Comfyui Hunyuan Image 2.1#
- HunyuanImage‑2.1 par Tencent. Modèle de base texte-à-image avec un transformateur de diffusion, des encodeurs de texte doubles, un VAE 32×, un post-entrainement RLHF et une distillation meanflow pour un échantillonnage efficace. Liens : Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Encodeur vision-langage multimodal utilisé ici comme encodeur de texte sémantique pour améliorer la compréhension des invites à travers des scènes complexes et des langues. Lien : Hugging Face
- ByT5 Small. Encodeur sans tokenizer au niveau des octets qui renforce la gestion des caractères et des glyphes pour le rendu textuel à l'intérieur des images. Liens : Hugging Face · Paper
Comment utiliser le workflow Comfyui Hunyuan Image 2.1#
Le graphe suit un chemin clair du texte aux pixels : encoder le texte avec deux encodeurs, préparer une toile latente native 2K, échantillonner avec Hunyuan Image 2.1, décoder via le VAE correspondant et enregistrer la sortie.
Encodage de texte avec des encodeurs doubles#
- Le
DualCLIPLoader(#33) charge Qwen2.5‑VL‑7B et ByT5 Small configurés pour Hunyuan Image 2.1. Cette configuration double permet au modèle de comprendre la sémantique des scènes tout en restant robuste aux glyphes et aux textes multilingues. - Entrez votre description principale dans
CLIPTextEncode(#6). Vous pouvez écrire en anglais ou en chinois, mélanger des indices de caméra et d'éclairage, et inclure des instructions de texte-dans-image. - Une invite négative prête à l'emploi dans
CLIPTextEncode(#7) supprime les artefacts courants. Vous pouvez l'adapter à votre style ou la laisser telle quelle pour des résultats équilibrés.
Toile latente en 2K native#
EmptyHunyuanImageLatent(#29) initialise la toile à 2048×2048 avec un seul lot. Hunyuan Image 2.1 est conçu pour la génération 2K, donc les tailles 2K natives sont recommandées pour la meilleure qualité.- Ajustez la largeur et la hauteur si nécessaire, en conservant les ratios d'aspect que Hunyuan supporte. Pour des ratios alternatifs, respectez les dimensions compatibles avec le modèle pour éviter les artefacts.
Échantillonnage efficace avec Hunyuan Image 2.1#
UNETLoader(#37) charge le point de contrôle FP8 pour réduire la VRAM tout en préservant la fidélité, puis alimenteKSampler(#3) pour le débruitage.- Utilisez les conditionnements positifs et négatifs des encodeurs pour orienter la composition et la clarté. Ajustez la graine pour la variété, les étapes pour la qualité par rapport à la vitesse et le guidage pour l'adhérence à l'invite.
- Le workflow se concentre sur le chemin du modèle de base. Hunyuan Image 2.1 prend également en charge une étape de raffinement ; vous pouvez en ajouter un plus tard si vous souhaitez une finition supplémentaire.
Décoder et enregistrer#
VAELoader(#34) intègre le VAE de Hunyuan Image 2.1, etVAEDecode(#8) reconstruit l'image finale à partir du latent échantillonné avec le schéma de compression 32× du modèle.SaveImage(#9) écrit la sortie dans le répertoire choisi. Définissez un préfixe de nom de fichier clair si vous prévoyez d'itérer sur des graines ou des invites.
Nœuds clés dans le workflow Comfyui Hunyuan Image 2.1#
DualCLIPLoader (#33)#
Ce nœud charge la paire d'encodeurs de texte qu'attend Hunyuan Image 2.1. Gardez le type de modèle défini pour Hunyuan et sélectionnez Qwen2.5‑VL‑7B et ByT5 Small pour combiner une forte compréhension des scènes avec une gestion du texte sensible aux glyphes. Si vous itérez sur le style, ajustez l'invite positive en tandem avec le guidage plutôt que de changer d'encodeurs.
CLIPTextEncode (#6 et #7)#
Ces nœuds transforment vos invites positives et négatives en conditionnement. Gardez l'invite positive concise en haut, puis ajoutez des indices de lentille, d'éclairage et de style. Utilisez l'invite négative pour supprimer les artefacts comme les membres supplémentaires ou le texte bruyant ; réduisez-la si vous la trouvez trop restrictive pour votre concept.
EmptyHunyuanImageLatent (#29)#
Définit la résolution de travail et le lot. Le 2048×2048 par défaut s'aligne avec la capacité native 2K de Hunyuan Image 2.1. Pour d'autres ratios d'aspect, choisissez des paires de largeur et hauteur compatibles avec le modèle et envisagez d'augmenter légèrement les étapes si vous vous éloignez du carré.
KSampler (#3)#
Conduit le processus de débruitage avec Hunyuan Image 2.1. Augmentez les étapes lorsque vous avez besoin de détails micro-fins, diminuez pour des brouillons rapides. Augmentez le guidage pour une adhérence plus forte à l'invite mais surveillez la sursaturation ou la rigidité ; baissez-le pour plus de variation naturelle. Changez de graines pour explorer des compositions sans changer votre invite.
UNETLoader (#37)#
Charge le UNet de Hunyuan Image 2.1. Le point de contrôle FP8 inclus maintient l'utilisation de la mémoire modeste pour une sortie 2K. Si vous avez suffisamment de VRAM et voulez un maximum de marge pour des réglages agressifs, envisagez une variante de précision supérieure du même modèle à partir des versions officielles.
VAELoader (#34) et VAEDecode (#8)#
Ces nœuds doivent correspondre à la version Hunyuan Image 2.1 pour décoder correctement. Le VAE de haute compression du modèle est essentiel pour une génération 2K rapide ; associer le bon VAE évite les décalages de couleur et les textures en blocs. Si vous changez le modèle de base, mettez toujours à jour le VAE en conséquence.
Extras optionnels#
- Invitation
- Hunyuan Image 2.1 répond bien aux invites structurées : sujet, action, environnement, caméra, éclairage, style. Pour le texte dans l'image, citez exactement les mots que vous voulez et gardez-les brefs.
- Vitesse et mémoire
- Le UNet FP8 est déjà efficace. Si vous devez compresser davantage, désactivez les gros lots et privilégiez moins d'étapes. Les nœuds de chargeur GGUF optionnels sont présents dans le graphe mais désactivés par défaut ; les utilisateurs avancés peuvent les échanger lorsqu'ils expérimentent avec des points de contrôle quantifiés.
- Ratios d'aspect
- Respectez les tailles compatibles 2K natives pour de meilleurs résultats. Si vous vous aventurez vers des formats larges ou hauts, vérifiez un rendu propre et envisagez une petite augmentation des étapes.
- Raffinement
- Hunyuan Image 2.1 prend en charge une étape de raffinement. Pour l'essayer, ajoutez un deuxième échantillonneur après le passage de base avec un point de contrôle de raffinement et un léger débruitage pour préserver la structure tout en augmentant le micro-détail.
- Références
- Détails du modèle Hunyuan Image 2.1 et téléchargements : Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct : Hugging Face
- ByT5 Small et papier : Hugging Face · Paper
Remerciements#
Ce workflow implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement @Ai Verse et Hunyuan pour Hunyuan Image 2.1 Demo pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation originale et aux référentiels ci-dessous.
Ressources#
- Hunyuan/Hunyuan Image 2.1 Demo
- Docs / Notes de version : Hunyuan Image 2.1 Demo tutorial from @Ai Verse
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.


