


1. Aperçu du Workflow ComfyUI LayerDiffuse#
Le workflow ComfyUI LayerDiffuse intègre trois sous-workflows spécialisés: créer des images transparentes, générer l'arrière-plan à partir du premier plan et le processus inverse de générer le premier plan basé sur l'arrière-plan existant. Chacun de ces sous-workflows LayerDiffuse fonctionne de manière indépendante, vous offrant la flexibilité de choisir et d'activer la fonctionnalité LayerDiffuse spécifique qui répond à vos besoins créatifs.
1.1. Créer des Images Transparentes avec LayerDiffuse:#
Ce workflow permet la création directe d'images transparentes, vous offrant la flexibilité de générer des images avec ou sans spécifier le masque de canal alpha.
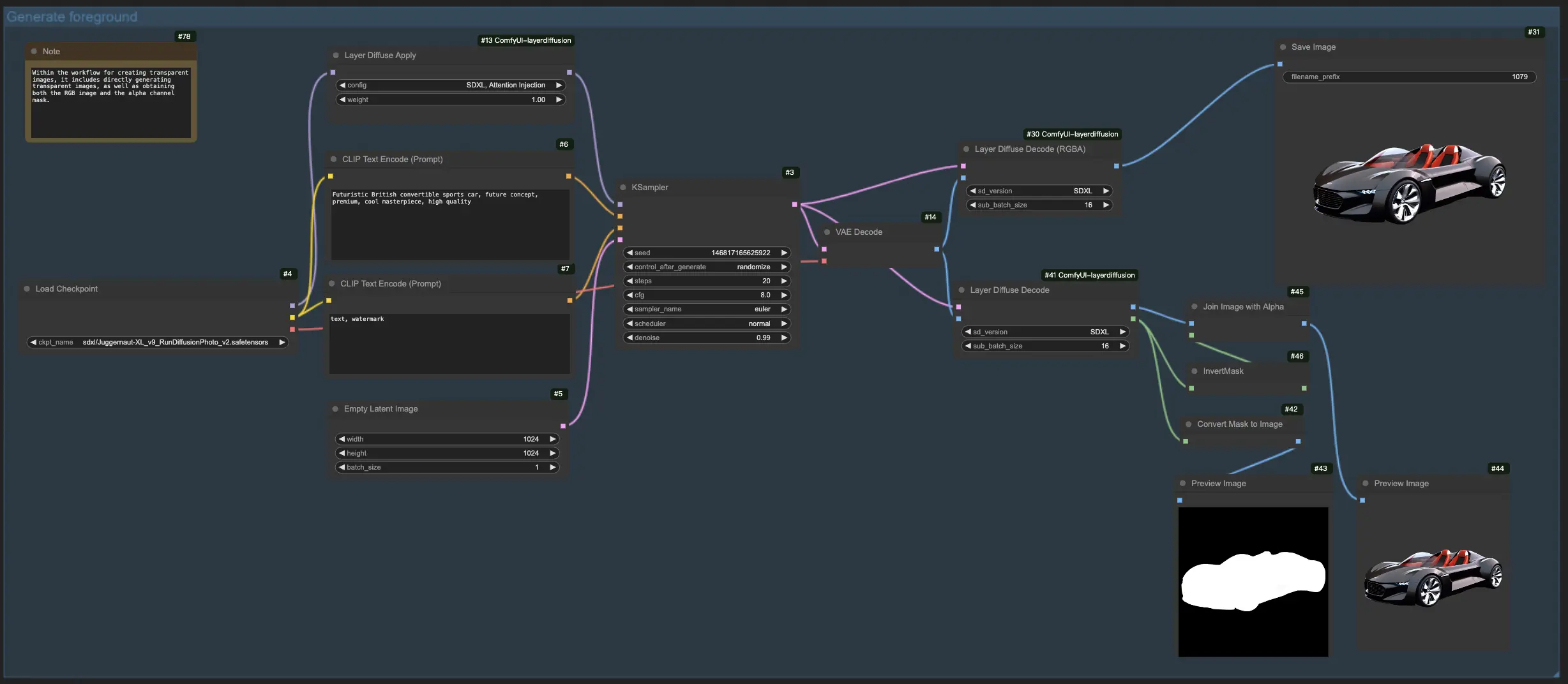
1.2. Générer l'Arrière-plan à partir du Premier Plan avec LayerDiffuse:#
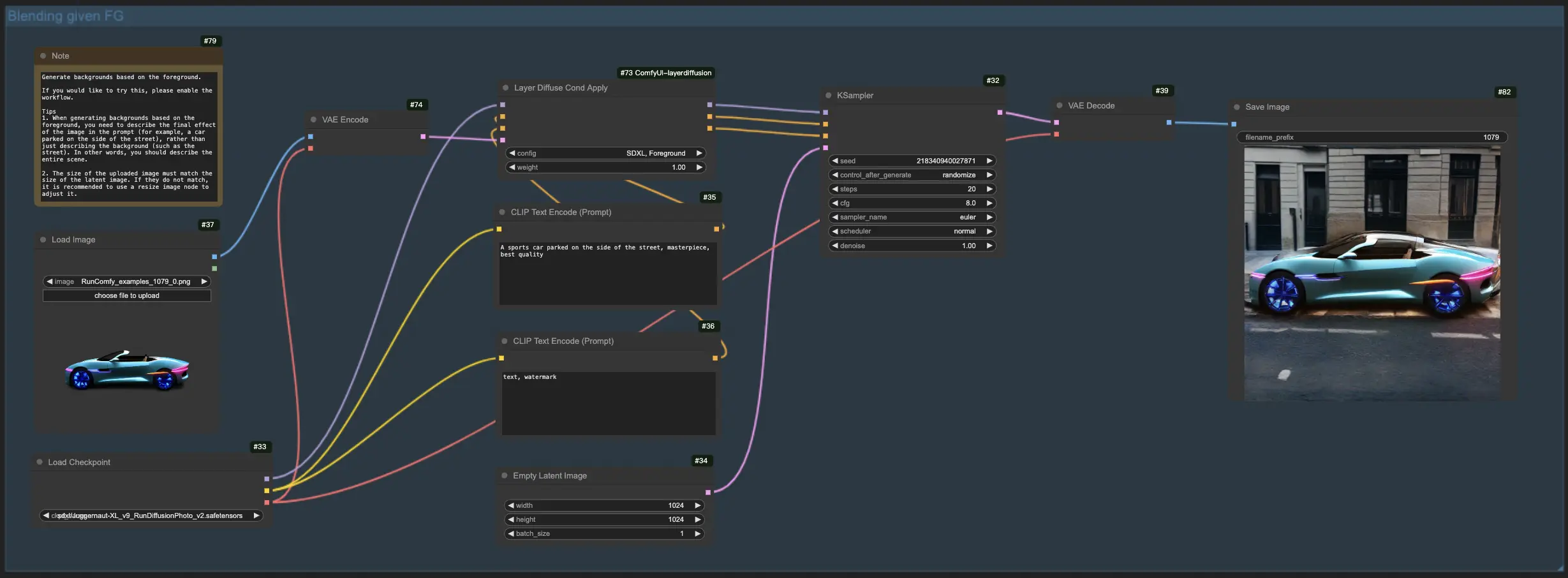
Pour ce workflow LayerDiffuse, commencez par télécharger votre image de premier plan et créer un prompt descriptif. LayerDiffuse mélange ensuite ces éléments pour produire l'image souhaitée. Lors de la rédaction de votre prompt pour LayerDiffuse, il est crucial de détailler la scène complète (par ex., "une voiture garée sur le côté de la rue") au lieu de simplement décrire l'élément d'arrière-plan (par ex., "la rue").
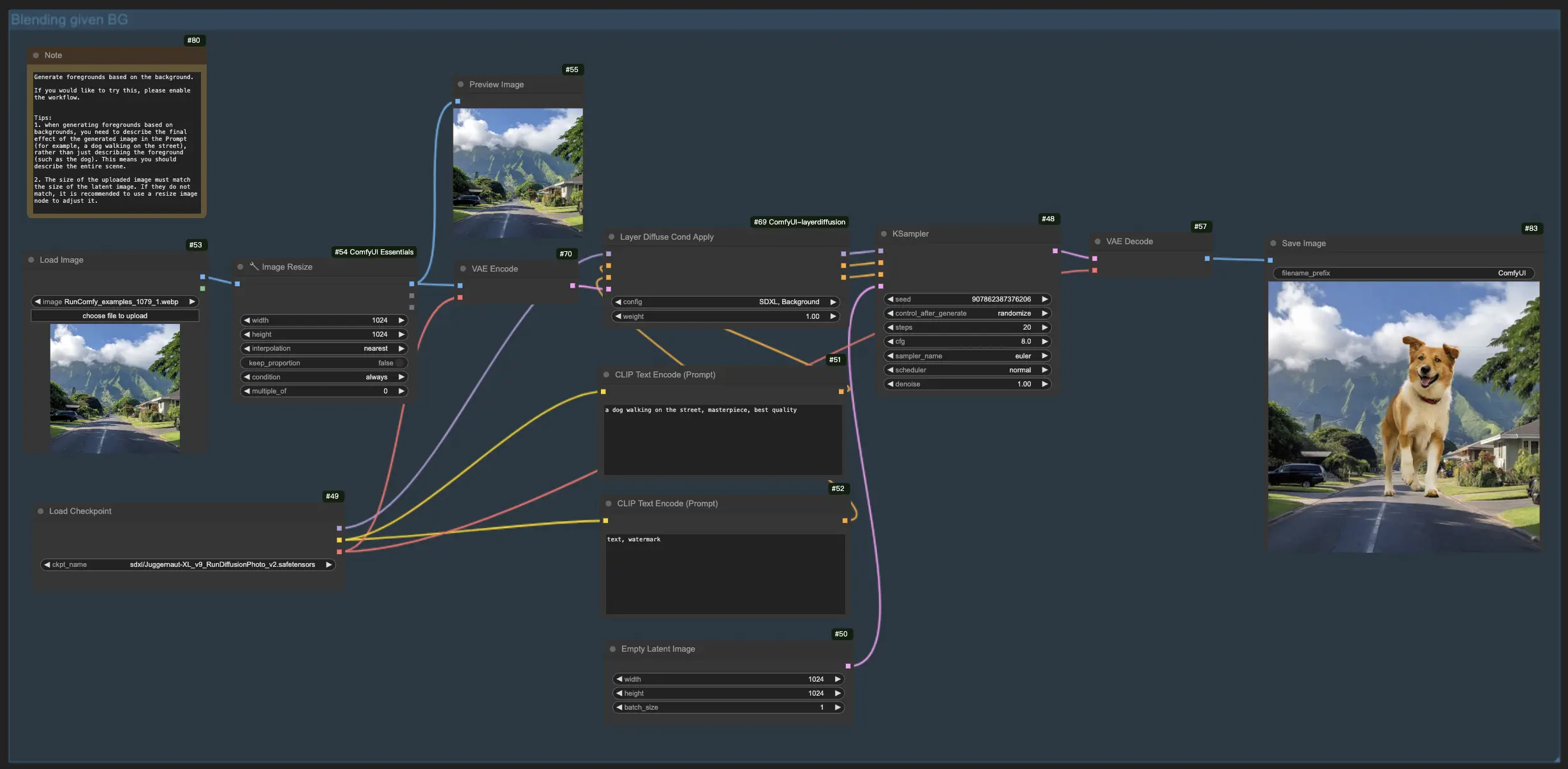
1.3. Générer le Premier Plan basé sur l'Arrière-plan:#
Reflétant le workflow précédent, cette fonctionnalité LayerDiffuse inverse l'objectif, visant à fusionner des éléments de premier plan avec un arrière-plan existant. Par conséquent, vous devez télécharger l'image d'arrière-plan et décrire l'image finale envisagée dans votre prompt, en mettant l'accent sur la scène complète (par ex., "un chien marchant dans la rue") plutôt que sur les éléments individuels (par ex., "le chien").
Pour plus de workflows LayerDiffuse, consultez-le sur github
2. Efficacité du Workflow LayerDiffuse#
Bien que le processus de création d'images transparentes soit robuste et produise de manière fiable des résultats de haute qualité, les workflows pour mélanger les arrière-plans et les premiers plans sont plus expérimentaux. Ils peuvent ne pas toujours parvenir à un mélange parfait, indicatif de la nature innovante mais en développement de cette technologie.
3. Introduction technique à LayerDiffuse#
LayerDiffuse est une approche innovante conçue pour permettre aux modèles de diffusion latente pré-entraînés à grande échelle de générer des images avec transparence. Cette technique introduit le concept de "transparence latente", qui implique l'encodage de la transparence du canal alpha directement dans la variété latente des modèles existants. Cela permet la création d'images transparentes ou de plusieurs couches transparentes sans modifier significativement la distribution latente originale du modèle pré-entraîné. L'objectif est de maintenir la sortie de haute qualité de ces modèles tout en ajoutant la capacité de générer des images avec transparence.
Pour y parvenir, LayerDiffuse ajuste finement les modèles de diffusion latente pré-entraînés en ajustant leur espace latent pour inclure la transparence comme un décalage latent. Ce processus implique des changements minimaux au modèle, préservant ses qualités et performances d'origine. L'entraînement de LayerDiffuse utilise un jeu de données d'un million de paires de couches d'images transparentes, collectées via un schéma human-in-the-loop pour assurer une grande variété d'effets de transparence.
La méthode s'est avérée adaptable à divers générateurs d'images open-source et peut être intégrée dans différents systèmes de contrôle conditionnel. Cette polyvalence permet une gamme d'applications, telles que la génération d'images avec une transparence spécifique à l'arrière-plan/premier plan, la création de couches avec des capacités de génération jointe et le contrôle du contenu structurel des couches.








