
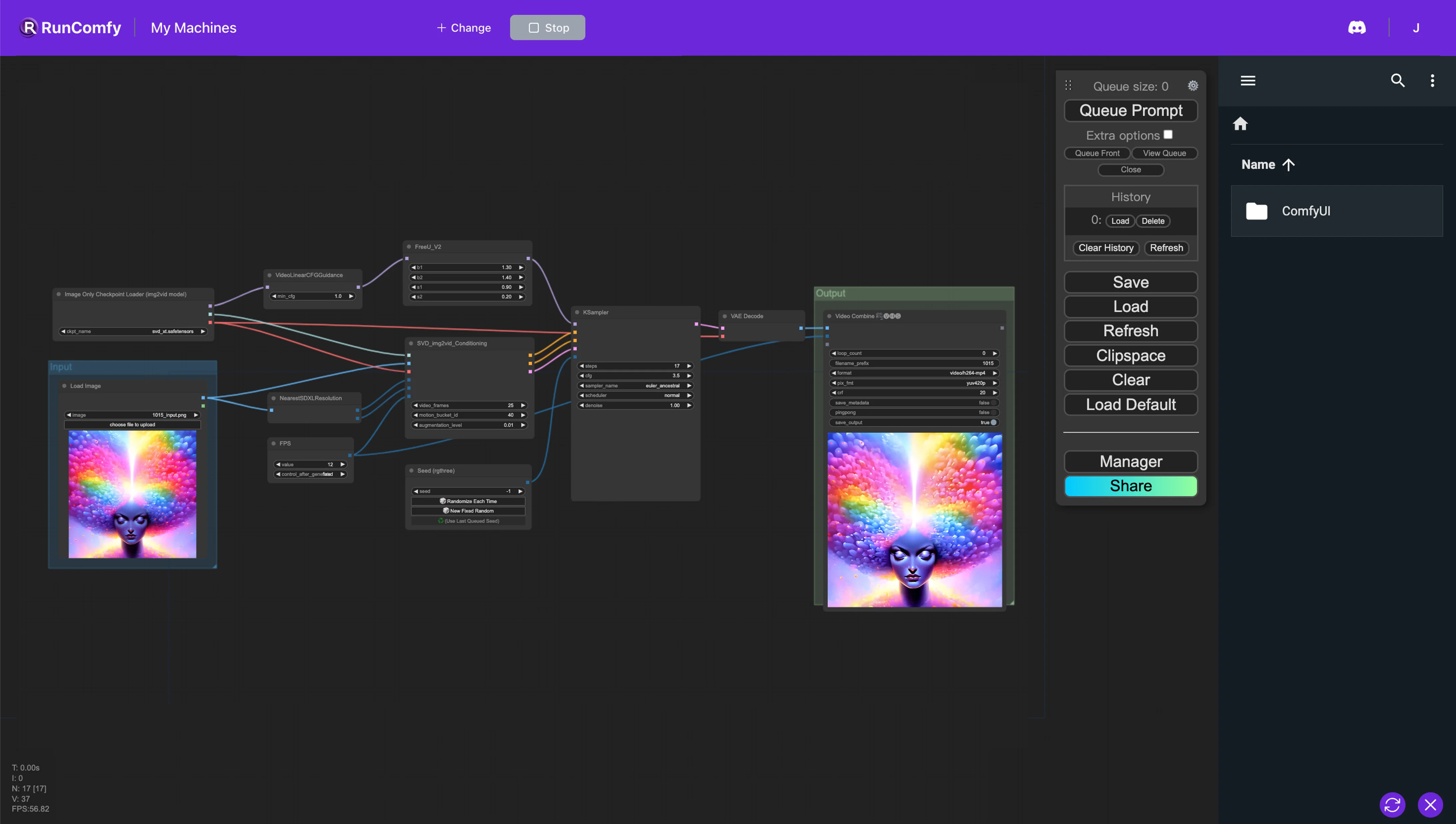
1. Workflow ComfyUI Stable Video Diffusion (SVD) et FreeU#
Ce workflow ComfyUI facilite un pipeline optimisé de conversion d'image en vidéo en tirant parti de Stable Video Diffusion (SVD) et de FreeU pour une sortie de qualité améliorée. FreeU améliore les résultats des modèles de diffusion sans surcoût supplémentaire—il n'y a pas besoin de réentraînement, d'augmentation de paramètres ou de temps de calcul ou de mémoire supplémentaire. Cette intégration garantit que vous pouvez obtenir une plus grande fidélité dans les sorties vidéo.
2. Aperçu de Stable Video Diffusion (SVD)#
Veuillez consulter les détails sur Introduction à SVD
3. Aperçu de FreeU#
Veuillez consulter les détails sur cette Introduction à FreeU
