
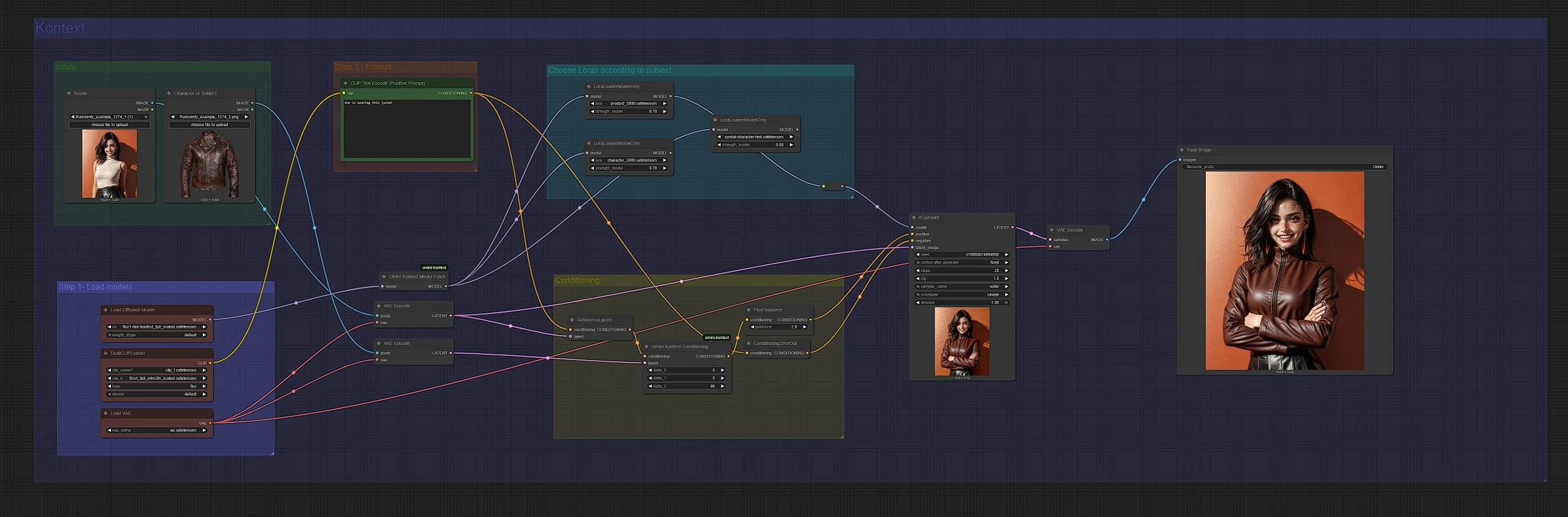





Workflow de composition d'image Omni Kontext pour ComfyUI#
Ce workflow vous permet d'ajouter un sujet dans une nouvelle scène avec une forte préservation de l'identité et du contexte en utilisant Omni Kontext. Il combine des patchs de modèle Flux Omni Kontext avec un conditionnement guidé par référence de sorte qu'un personnage ou un produit fourni se fond naturellement dans un arrière-plan cible tout en respectant votre invite. Deux chemins parallèles sont inclus : un chemin Flux standard pour une fidélité maximale et un chemin Nunchaku pour un échantillonnage plus rapide et économe en mémoire avec des poids quantifiés.
Les créateurs qui souhaitent des actifs de marque cohérents, des échanges de produits ou des placements de personnages trouveront cela particulièrement utile. Vous fournissez une image de sujet propre, une image de scène et une courte invite, et le graphe gère l'extraction de contexte, la guidance, le style LoRA et le décodage pour produire un composite cohérent.
Modèles clés dans le workflow Comfyui Omni Kontext#
- FLUX.1 Dev – L'épine dorsale du transformateur de diffusion utilisée pour la génération. Il offre une forte adhérence aux invites et un comportement d'échantillonneur moderne adapté à la composition sensible au contexte. Model card
- Encodeurs de texte Flux (CLIP-L et T5-XXL) – Encodeurs jumelés qui tokenisent et intègrent votre texte dans un conditionnement adapté à FLUX. Le workflow charge les variantes
clip_l.safetensorsett5xxloptimisées pour Flux. Encoders - Nœuds Omni Kontext – Nœuds personnalisés qui patchent le modèle et le conditionnement pour injecter le contexte de votre sujet latent dans le flux de guidance final. Repository
- Nunchaku Flux DiT – Chargeur optionnel qui prend en charge les poids FLUX quantifiés FP16/BF16 et INT4 pour la vitesse et une VRAM plus faible tout en maintenant une qualité compétitive. Repository
- Lumina VAE – Un VAE robuste utilisé pour encoder les images de sujet et de scène et décoder les sorties finales. Le workflow référence
ae.safetensorsdu Lumina Image 2.0 reconditionné. VAE
Comment utiliser le workflow Comfyui Omni Kontext#
Le graphe a deux voies miroirées : la voie supérieure est le chemin standard Flux Omni Kontext, et la voie inférieure est le chemin Nunchaku. Les deux acceptent une image de sujet et une image de scène, construisent un conditionnement sensible au contexte, et échantillonnent avec Flux pour produire le composite.
Entrées#
Fournissez deux images : un cliché de sujet propre et une scène cible. Le sujet doit être bien éclairé, centré et non obstrué pour maximiser le transfert d'identité. La scène doit correspondre approximativement à votre angle de caméra et à l'éclairage prévus. Chargez-les dans les nœuds étiquetés "Character or Subject" et "Scene", puis gardez-les cohérents à travers les itérations des invites.
Charger les modèles#
La voie standard charge Flux avec UNETLoader (#37) et applique le patch de modèle Omni Kontext avec OminiKontextModelPatch (#194). La voie Nunchaku charge un modèle Flux quantifié avec NunchakuFluxDiTLoader (#217) et applique NunchakuOminiKontextPatch (#216). Les deux voies partagent les mêmes encodeurs de texte via DualCLIPLoader (#38) et le même VAE via VAELoader (#39 ou #204). Si vous prévoyez d'utiliser des styles ou identités LoRA, gardez-les connectés dans cette section pour qu'ils affectent les poids du modèle avant l'échantillonnage.
Invite#
Écrivez des invites concises qui disent au système quoi faire avec le sujet. Dans la voie supérieure, CLIP Text Encode (Positive Prompt) (#6) conduit l'insertion ou le style, et dans la voie inférieure CLIP Text Encode (Positive Prompt) (#210) joue le même rôle. Des invites comme "ajouter le personnage à l'image" ou "elle porte cette veste" fonctionnent bien. Évitez les descriptions trop longues ; restez sur les éléments essentiels que vous souhaitez changer ou maintenir.
Conditionnement#
Chaque voie encode le sujet et la scène en latents avec VAEEncode, puis fusionne ces latents avec votre texte via ReferenceLatent et OminiKontextConditioning (#193 dans la voie supérieure, #215 dans la voie inférieure). C'est l'étape Omni Kontext qui injecte des indices d'identité et spatiaux significatifs de la référence dans le flux de conditionnement. Après cela, FluxGuidance (#35 supérieure, #207 inférieure) définit la force avec laquelle le modèle suit le conditionnement composite. Les invites négatives sont simplifiées avec ConditioningZeroOut (#135, #202) pour que vous puissiez vous concentrer sur ce que vous voulez plutôt que sur ce que vous voulez éviter.
Choisir les Loras selon le sujet#
Si votre sujet bénéficie d'un LoRA, connectez-le avant l'échantillonnage. La voie standard utilise LoraLoaderModelOnly (#201 et compagnons) et la voie Nunchaku utilise NunchakuFluxLoraLoader (#219, #220, #221). Utilisez les LoRAs de sujet pour la cohérence de l'identité ou de la tenue et les LoRAs de style pour la direction artistique. Gardez les forces modérées pour préserver le réalisme de la scène tout en appliquant les traits du sujet.
Nunchaku#
Tournez-vous vers le groupe Nunchaku lorsque vous souhaitez des itérations plus rapides ou avez une VRAM limitée. Le NunchakuFluxDiTLoader (#217) prend en charge les paramètres INT4 qui réduisent considérablement la mémoire tout en maintenant le comportement "Flux Omni Kontext" via NunchakuOminiKontextPatch (#216). Vous pouvez toujours utiliser les mêmes invites, entrées et LoRAs, puis échantillonner avec KSampler (#213) et décoder avec VAEDecode (#208) pour enregistrer les résultats.
Nœuds clés dans le workflow Comfyui Omni Kontext#
OminiKontextModelPatch (#194)#
Applique les modifications du modèle Omni Kontext à l'épine dorsale Flux pour que le contexte de référence soit honoré pendant l'échantillonnage. Laissez-le activé chaque fois que vous souhaitez que l'identité du sujet et les indices spatiaux soient intégrés à la génération. Associez-le à une force LoRA modérée lors de l'utilisation de LoRAs de personnage ou de produit pour que le patch et le LoRA ne soient pas en concurrence.
OminiKontextConditioning (#193, #215)#
Fusionne votre conditionnement de texte avec des latents de référence du sujet et de la scène. Si l'identité dérive, augmentez l'emphase sur la référence du sujet ; si la scène est supplantée, réduisez-la légèrement. Ce nœud est au cœur de la composition Omni Kontext et nécessite généralement seulement de petits ajustements une fois que vos entrées sont propres.
FluxGuidance (#35, #207)#
Contrôle la rigueur avec laquelle le modèle suit le conditionnement composite. Des valeurs plus élevées poussent plus près de l'invite et de la référence au détriment de la spontanéité ; des valeurs plus basses permettent plus de variété. Si vous voyez des textures trop cuites ou une perte d'harmonie avec la scène, essayez une petite réduction ici.
NunchakuFluxDiTLoader (#217)#
Charge une variante Flux DiT quantifiée pour la vitesse et une mémoire réduite. Choisissez INT4 pour des aperçus rapides et FP16 ou BF16 pour la qualité finale. Combinez avec NunchakuFluxLoraLoader lorsque vous avez besoin de support LoRA dans la voie Nunchaku.
Extras optionnels#
- Utilisez des recadrages serrés du sujet avec des arrière-plans propres pour améliorer la capture de l'identité lors de l'encodage VAE.
- Gardez les invites courtes et concrètes. Préférez "ajouter le produit sur la table" à de longues listes de styles.
- Si le sujet semble collé, réduisez un peu la force LoRA et diminuez légèrement la guidance pour laisser la scène réaffirmer l'éclairage et la perspective.
- Pour les tours rapides, itérez sur la voie Nunchaku, puis revenez à la voie standard Flux Omni Kontext pour les rendus finaux.
- Enregistrez quelques graines intermédiaires qui ont bien fonctionné pour pouvoir les réutiliser tout en affinant la force LoRA et la guidance.
Remerciements#
- Omni Kontext par Saquib764. Ce workflow adapte des concepts et des composants du projet pour permettre la composition Flux Omni Kontext dans ComfyUI. Repository


