
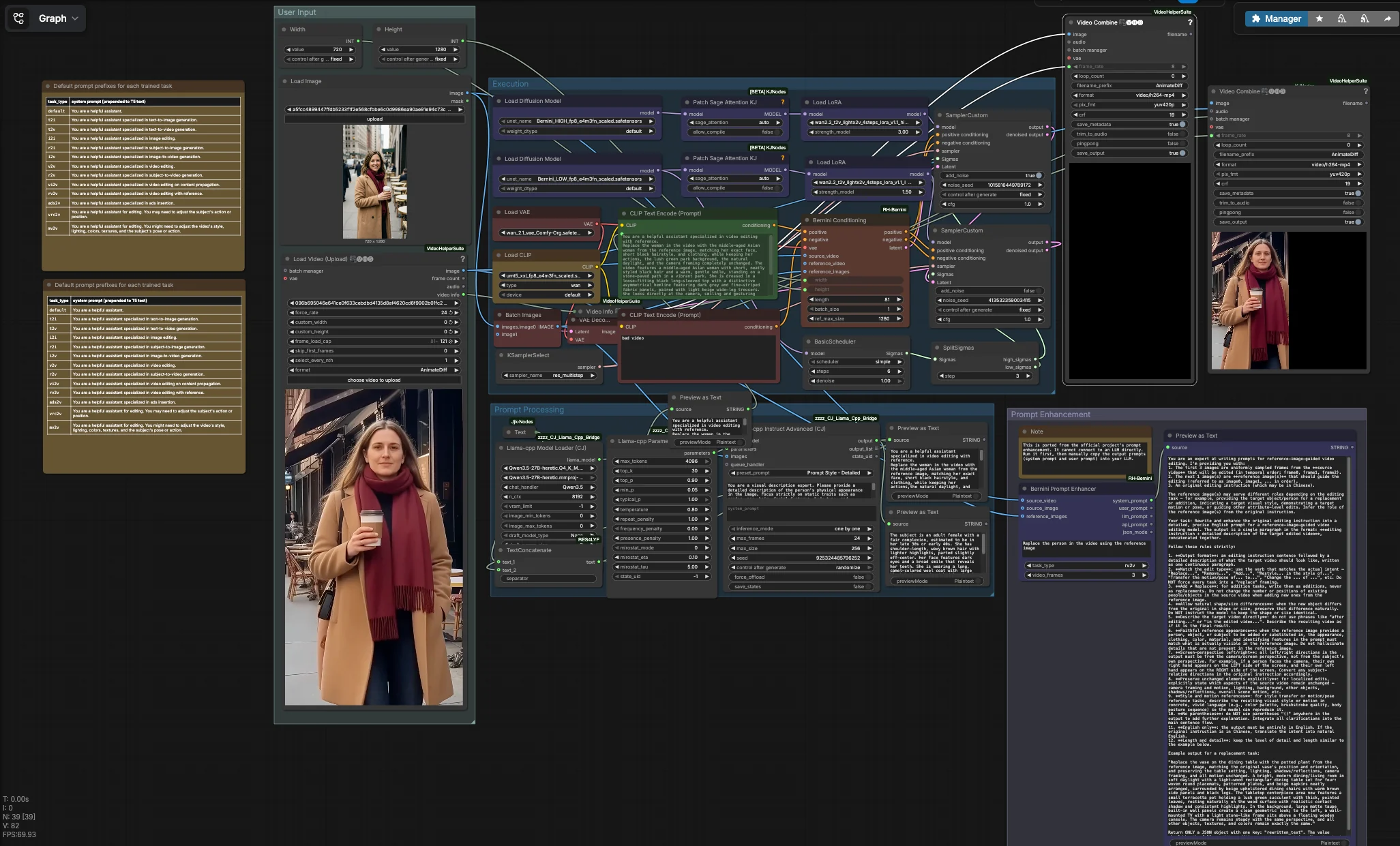
Flux de travail de génération et d'édition vidéo multimodale Bernini#
Ce flux de travail de génération et d'édition vidéo multimodale Bernini est une solution clé en main pour ComfyUI pour l'édition vidéo sensible à l'identité, guidée par référence, et la transformation vidéo à vidéo. Il combine une vidéo source, une ou plusieurs images de référence, et une invite ciblée pour préserver le mouvement et le comportement de la caméra tout en remplaçant ou restylisant le sujet. Le flux de travail associe les backbones de diffusion haute et basse de Bernini avec le codage de texte de style Wan, un VAE compatible Bernini, des LoRAs LightX2V, et un conditionnement spécifique à Bernini pour que les résultats soient cohérents d'une image à l'autre.
Conçu pour les créateurs et chercheurs évaluant Bernini dans ComfyUI, le flux de travail excelle dans le remplacement de personnages, les éditions préservant le mouvement, l'imitation, et la génération courte forme consciente de la caméra. Il exporte un MP4 édité plus une comparaison côte à côte optionnelle, facilitant la révision de l'impact de votre invite et de votre ensemble de références. Tout au long de ce README, le terme flux de travail de génération et d'édition vidéo multimodale Bernini fait référence à ce graphique de bout en bout.
Modèles clés dans le flux de travail de génération et d'édition vidéo multimodale Bernini de Comfyui#
- Famille de modèles de diffusion Bernini de ByteDance (backbones HIGH et LOW). Fournit les réseaux de débruitage de base utilisés dans un calendrier à deux étapes : le modèle HIGH gère la structure sous un bruit plus fort tandis que le modèle LOW affine les détails et la cohérence temporelle. Voir le hub de modèles pour les poids de référence et les notes : ByteDance/Bernini.
- Encodeur de texte Wan (umT5-XXL). Un encodeur T5 de style Wan qui transforme votre instruction en conditionnement pour Bernini; exposé dans ComfyUI via une interface compatible CLIP. Les ressources adaptées à ComfyUI sont disponibles ici : Kijai/WanVideo_comfy_fp8_scaled.
- VAE Wan 2.1. Effectue le décodage latent pour transformer les latents débruités en images vidéo avec une fidélité des couleurs correspondant à l'entraînement Wan/Bernini. Un VAE prêt pour ComfyUI est inclus dans le même pack de ressources : Kijai/WanVideo_comfy_fp8_scaled.
- Paire de LoRA LightX2V (high_noise et low_noise). Adaptateurs légers qui orientent Bernini vers un mouvement stable tout en préservant l'identité de référence à travers les images. Les poids FP8 LoRA fournis s'alignent avec l'échantillonnage à deux étapes utilisé dans ce flux de travail et sont emballés avec les actifs Bernini ci-dessus : Kijai/WanVideo_comfy_fp8_scaled.
Comment utiliser le flux de travail de génération et d'édition vidéo multimodale Bernini de Comfyui#
Ce flux de travail comporte quatre groupes coordonnés. Vous fournissez une vidéo source et une ou plusieurs images de référence, façonnez le texte de l'instruction, puis le groupe d'exécution effectue un passage Bernini en deux phases qui décode en images et assemble votre vidéo de sortie. Un utilitaire parallèle peut générer des invites système et utilisateur échafaudées pour l'écriture d'invites assistée par LLM.
Entrée Utilisateur#
Chargez votre vidéo source avec VHS_LoadVideo (#90). Le nœud lit le clip et expose ses métadonnées afin que le rendu final hérite du taux de trame original, ce qui aide à préserver la sensation de mouvement. Ajoutez une ou plusieurs références d'identité avec LoadImage (#31); les visages frontaux bien éclairés avec des expressions neutres fonctionnent le mieux. Réglez la taille cible en utilisant Width (#109) et Height (#110), idéalement en correspondant au ratio d'aspect de la source pour éviter l'étirement. Une invite négative par défaut est encodée par CLIPTextEncode (#4) pour supprimer les artefacts courants dans la vidéo de basse qualité; vous pouvez la raffiner si nécessaire.
Traitement de l'Invite#
Si vous souhaitez que l'instruction corresponde précisément à l'identité de référence, le graphique peut résumer les traits statiques de vos images de référence à l'aide d'un LLM local. llama_cpp_model_loader (#93) et llama_cpp_instruct_adv (#92) analysent les images groupées par BatchImagesNode (#74) et renvoient une description concise des attributs immuables tels que les cheveux, l'âge, et les vêtements. Cette description est concaténée avec votre directive de tâche de JjkText (#104) via TextConcatenate (#102). Le résultat s'écoule dans CLIPTextEncode (#3), qui devient le conditionnement positif pour Bernini. Les nœuds d'aperçu montrent le texte composé pour que vous puissiez itérer rapidement avant de lancer les étapes lourdes.
Amélioration de l'Invite#
BerniniPromptEnhancer (#60) génère des invites “système” et “utilisateur” structurées adaptées au type de tâche sélectionné et aux entrées. Exécutez-le pour obtenir des instructions plus fortes que vous pouvez coller dans votre LLM pour une expansion d'invite plus riche; par conception, il n'est pas câblé dans le graphique principal. Cet utilitaire provient du pack de nœuds personnalisés Bernini : ComfyUI-RH-Bernini. Considérez-le comme un outil de pré-écriture pour standardiser le langage qui fonctionne bien avec le conditionnement de Bernini.
Exécution#
Le chemin principal commence par le chargement des UNets HIGH et LOW de Bernini et l'attachement des LoRAs LightX2V pour chaque étape. BerniniConditioning (#34) fusionne vos encodages positifs et négatifs, VAE, images vidéo source, et images de référence pour construire le conditionnement spécifique à Bernini et un latent initial aligné à votre résolution et au nombre d'images. Un BasicScheduler (#18) crée le calendrier de débruitage, puis SplitSigmas (#17) le divise en plages HIGH et LOW. L'échantillonneur HIGH SamplerCustom (#19) établit la structure et l'identité sous un bruit plus fort, passant son latent à l'échantillonneur LOW SamplerCustom (#15) pour le détail et le polissage temporel. KSamplerSelect (#27) choisit l'algorithme d'échantillonnage, VAEDecode (#16) transforme le latent final en images, et VHS_VideoCombine (#87) rend un MP4 qui hérite du taux de trame source. En parallèle, ImageConcanate (#97) et un second VHS_VideoCombine (#96) produisent une comparaison côte à côte pour des vérifications rapides de qualité. L'I/O vidéo et l'assemblage sont fournis par la Suite d'Aide Vidéo : ComfyUI-VideoHelperSuite.
Nœuds clés dans le flux de travail de génération et d'édition vidéo multimodale Bernini de Comfyui#
BerniniConditioning (#34) Construit le conditionnement natif Bernini en combinant vos encodages de texte, VAE, vidéo source, et imagerie de référence. Il prépare également le volume latent de départ et gère les dimensions spatiales et temporelles. Réglez width et height pour correspondre à votre résolution cible et utilisez length pour contrôler le nombre d'images générées. Si le sujet de référence est petit dans l'image, augmentez ref_max_size pour que le modèle perçoive mieux les détails d'identité. Ce nœud fait partie du pack personnalisé Bernini : ComfyUI-RH-Bernini.
LoraLoaderModelOnly (#11) Applique le LoRA high_noise LightX2V au backbone HIGH. Augmenter son strength_model accroît l'adhésion à la référence à l'étape structurelle, utile lorsque la silhouette ou les caractéristiques grossières du sujet ne correspondent pas à la vidéo source. Abaissez-le si l'édition devient trop rigide ou supprime le mouvement naturel. Utilisez-le en tandem avec le LoRA de l'étape LOW pour équilibrer la fidélité et la fluidité.
LoraLoaderModelOnly (#29) Applique le LoRA low_noise LightX2V au backbone LOW. Ce LoRA affine les textures comme les cheveux, la peau, et les vêtements tout en conservant le mouvement défini par l'étape HIGH. Si les détails d'identité dérivent entre les images, augmentez légèrement la force; si les textures deviennent trop nettes ou semblent surajustées, réduisez-la. Avec le LoRA de l'étape HIGH, il forme une paire complémentaire.
SplitSigmas (#17) Divise le calendrier de débruitage en plages HIGH et LOW. Déplacer la division plus tôt donne des éditions plus douces qui conservent plus de la vidéo originale, tandis que la déplacer plus tard accorde plus d'influence à l'étape HIGH pour des remplacements plus forts. Ajustez la division lorsque vous changez d'invites ou de forces LoRA pour que les deux étapes restent équilibrées. Ce contrôle est particulièrement utile pour les éditions préservant le mouvement, verrouillées sur la caméra.
KSamplerSelect (#27) Sélectionne l'algorithme d'échantillonnage utilisé par les deux étapes de débruitage. Certains échantillonneurs favorisent la stabilité et la douceur temporelle tandis que d'autres privilégient le détail ou la vitesse. Si vous voyez des scintillements, essayez un échantillonneur connu pour sa consistance; si vous avez besoin de netteté supplémentaire, essayez un algorithme qui injecte plus de variance. Gardez le même choix pour les deux étapes pour maintenir un comportement prévisible.
VHS_VideoCombine (#87) Encode les images décodées dans un MP4 final tout en héritant du taux de trame rapporté par VHS_VideoInfo pour que la vitesse de lecture corresponde au clip source. Utilisez les contrôles de nom de fichier pour organiser les exécutions et activez la sauvegarde des métadonnées si vous prévoyez d'auditer les paramètres. Une seconde instance (#96) produit un rendu côte à côte pour une comparaison visuelle rapide. Fourni par ComfyUI-VideoHelperSuite.
Extras optionnels#
- Pour les tâches critiques pour l'identité, fournissez deux ou trois images de référence de haute qualité montrant des cheveux, un éclairage, et une expression cohérents. Utilisez l'entrée par lots pour les alimenter ensemble.
- Gardez le ratio d'aspect cible proche de la vidéo source. De grands écarts peuvent étirer les visages et déstabiliser le mouvement.
- Si l'arrière-plan ou la caméra dérive, renforcez le langage dans votre instruction qui verrouille la position de la caméra et la scène, et renforcez avec une invite négative concise.
- Utilisez l'exportation côte à côte lors de l'ajustement des forces LoRA ou de la division sigma. Cela réduit le temps d'itération en rendant les différences évidentes.
- Pour des essais plus rapides, limitez le nombre d'images que vous chargez, puis augmentez une fois que vous êtes satisfait de la correspondance d'identité et de la qualité du mouvement.
Ce flux de travail de génération et d'édition vidéo multimodale Bernini est conçu pour être modifié en toute sécurité : commencez avec les paramètres par défaut, itérez sur l'instruction et les références, puis affinez les forces LoRA et la division sigma pour votre sujet et scène.
Remerciements#
Ce flux de travail met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement ByteDance pour Bernini, RH-RunningHub pour ComfyUI-RH-Bernini, et Kosinkadink pour ComfyUI-VideoHelperSuite pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- RunningHub/Bernini Génération et Édition Vidéo Multimodale (Flux de travail ComfyUI)
- Docs / Notes de version : Référence de flux de travail RunningHub
- RunComfy/Cloud Save flux de travail
- Docs / Notes de version : Flux de travail RunComfy Cloud Save
- ByteDance/Bernini-R
- GitHub : bytedance/Bernini
- Hugging Face : ByteDance/Bernini-R
- arXiv : arXiv:2605.22344
- Docs / Notes de version : Source du modèle ByteDance Bernini
- Kijai/WanVideo_comfy_fp8_scaled (actifs Bernini)
- Hugging Face : Kijai/WanVideo_comfy_fp8_scaled
- Docs / Notes de version : Actifs de modèle Kijai Bernini ComfyUI fp8
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub : RH-RunningHub/ComfyUI-RH-Bernini
- Docs / Notes de version : Nœuds personnalisés RunComfy Bernini
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub : Kosinkadink/ComfyUI-VideoHelperSuite
- Docs / Notes de version : Suite d'aide vidéo ComfyUI
Note : L'utilisation des modèles, jeux de données, et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.