
Workflow ACE-Step 1.5XL Turbo Text-to-Music ComfyUI#
Transformez des invites compactes en musique MP3 soignée avec ce workflow comfyui axé sur la rapidité et la répétabilité. Il associe le générateur ACE-Step 1.5XL Turbo avec son VAE officiel et des encodeurs de texte Qwen doubles, puis exporte directement en MP3 pour un aperçu facile et une réutilisation. Les producteurs, concepteurs sonores et artistes d'invites peuvent itérer rapidement tout en maintenant la cohérence des résultats à chaque exécution.
Modèles clés dans ce workflow comfyui#
- ACE-Step 1.5XL Turbo (bf16). Le modèle de diffusion principal qui synthétise la musique à partir du conditionnement textuel, optimisé pour un débruitage rapide et des latents audio de haute qualité. Fichier modèle
- ACE-Step 1.5 VAE. Le décodeur qui transforme les latents audio en une forme d'onde finale tout en préservant le timbre et la dynamique attendus par la famille ACE-Step. Fichier modèle
- Qwen 0.6B ACE 1.5 encodeur de texte. Encodeur léger qui convertit votre invite descriptive en vecteurs de conditionnement utilisés par le générateur. Fichier modèle
- Qwen 4B ACE 1.5 encodeur de texte. Encodeur compagnon plus grand qui enrichit les sémantiques, les indices de style, les instruments et les indications vocales pour des rendus plus fidèles. Fichier modèle
Comment utiliser ce workflow comfyui#
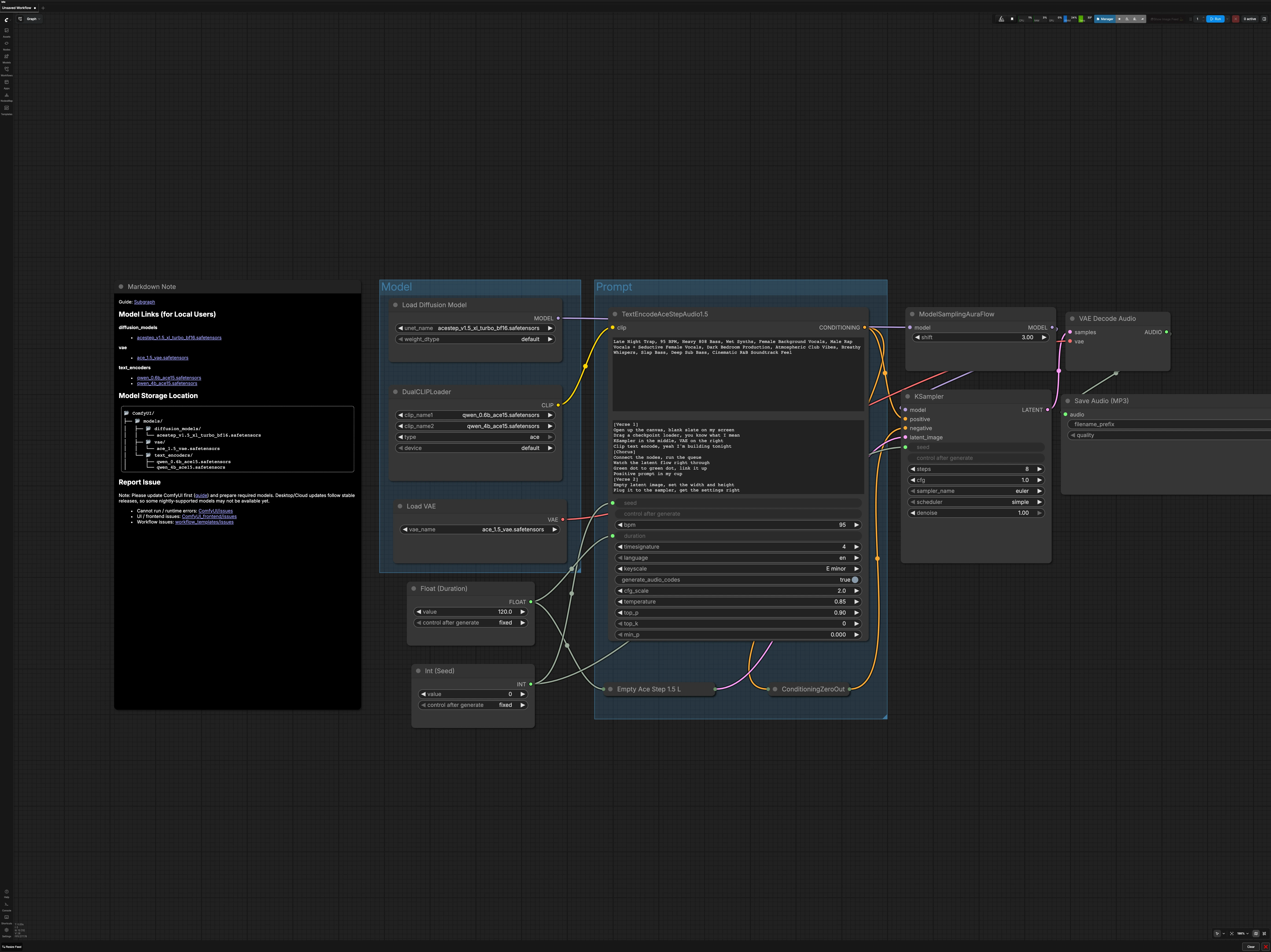
Le graphe est organisé en deux groupes principaux plus des contrôles globaux. Vous chargez la pile de modèles ACE-Step, décrivez la musique souhaitée, définissez la durée de la chanson et la graine, puis échantillonnez, décodez et exportez en MP3.
Groupe de modèles#
Cette section initialise la pile de modèles attendue par le générateur. UNETLoader (#104) charge ACE-Step 1.5XL Turbo, et VAELoader (#106) apporte le VAE ACE-Step 1.5 correspondant pour que le décodage reste fidèle. DualCLIPLoader (#105) associe les encodeurs de texte Qwen 0.6B et 4B pour préparer les embeddings d'invite. Le UNet est acheminé à travers ModelSamplingAuraFlow (#78), qui applique la configuration de l'échantillonneur requise par le modèle avant que le débruitage ne commence.
Groupe d'invites#
Écrivez une description concise du genre, de l'humeur, des instruments, des voix, du tempo et du style de production dans TextEncodeAceStepAudio1.5 (#94). Si vous utilisez des paroles ou des notes structurelles, fournissez-les dans la boîte de texte secondaire afin que les encodeurs puissent conditionner la phraséologie et la dynamique. Le conditionnement négatif est intentionnellement désactivé via ConditioningZeroOut (#47) pour garder les sorties ciblées et simplifier les premières itérations. Le nœud accepte également la durée globale et la graine, garantissant que le conditionnement reste aligné avec la longueur de la piste et vos paramètres de reproductibilité.
Durée et graine#
Réglez la longueur de la piste en secondes en utilisant Float (Duration) (#99). Choisissez une graine dans Int (Seed) (#109) pour rendre les exécutions reproductibles à la fois pour l'encodeur et l'échantillonneur. Garder la même graine tout en changeant uniquement l'invite est un moyen fiable de tester A/B les directions créatives. Pour une exploration large, variez la graine après être satisfait de l'invite.
Configuration audio latente#
EmptyAceStep1.5LatentAudio (#98) construit un audio latent vide qui correspond à la durée choisie. Cela sert de toile que l'échantillonneur remplira pendant le débruitage. Les durées plus longues nécessitent plus de calculs, alors envisagez de commencer plus court pour valider une invite avant d'augmenter. Le workflow connecte la durée globalement pour que votre latent et votre conditionnement restent toujours synchronisés.
Débruitage et échantillonnage#
KSampler (#3) effectue le processus de diffusion en utilisant le modèle ACE-Step 1.5XL Turbo et votre conditionnement d'invite. Le chemin de l'échantillonneur passe par ModelSamplingAuraFlow (#78) pour correspondre aux paramètres du planificateur attendus par le modèle pour une convergence stable et rapide. Utilisez la même graine pour comparer les changements de formulation ou de style, et ajustez les paramètres de l'échantillonneur uniquement une fois que votre invite est ajustée. Lorsque l'échantillonneur termine, vous aurez un audio latent prêt pour le décodage.
Décodage et exportation#
VAEDecodeAudio (#18) convertit le latent en une forme d'onde avec le VAE ACE-Step 1.5 pour préserver le timbre prévu. SaveAudioMP3 (#107) écrit un MP3 avec un nom de fichier de base et une étiquette de version optionnelle pour que vous puissiez garder les prises organisées. Le MP3 est idéal pour une révision rapide et un partage, et vous pouvez toujours re-render ou ré-exporter dans un format différent plus tard. Le résultat apparaît dans votre emplacement de sortie ComfyUI standard.
Nœuds clés dans ce workflow comfyui#
TextEncodeAceStepAudio1.5 (#94)#
Ce nœud traduit votre description musicale et les paroles optionnelles en conditionnement pour le générateur en utilisant les encodeurs Qwen appariés. Gardez les invites spécifiques au genre, à l'instrumentation, à la présence vocale, au tempo, à l'humeur et au caractère du mix. Assurez-vous que la durée du nœud correspond à la longueur globale de la chanson pour que la structure et la phraséologie soient alignées. Utilisez une graine fixe tout en itérant sur la formulation pour comprendre comment les termes influencent l'arrangement et le timbre.
EmptyAceStep1.5LatentAudio (#98)#
Contrôle la toile temporelle que le modèle remplira. Augmenter la durée augmente la mémoire et le temps de rendu, alors itérez sur des brouillons plus courts avant de vous engager sur des pièces plus longues. Gardez les changements de durée délibérés car ils peuvent modifier le tempo perçu et le rythme des sections, même avec la même invite et graine.
KSampler (#3)#
Conduit la qualité, la vitesse et la texture globale en contrôlant comment le bruit est supprimé du latent. Commencez par le chemin du planificateur fourni et ajustez les paramètres de l'échantillonneur uniquement après que l'invite semble correcte. Pour des ébauches rapides, réduisez l'effort d'échantillonnage; pour une plus haute fidélité, augmentez-le progressivement tout en gardant la graine constante pour que les différences soient faciles à entendre. Consultez le comportement principal de l'échantillonneur dans le dépôt ComfyUI pour des conseils généraux. ComfyUI sur GitHub
SaveAudioMP3 (#107)#
Gère l'exportation et le nommage des fichiers pour que vous puissiez cataloguer les prises. Définissez un nom de base clair et une étiquette de version pour suivre les itérations. Si vous prévoyez de masteriser ou de modifier davantage, conservez la graine du projet et l'invite dans vos notes pour pouvoir re-render avec des paramètres d'exportation alternatifs si nécessaire.
Extras optionnels#
- Écrivez les invites sous forme de phrases courtes et ordonnées : genre, humeur, ressenti clé, tempo, instruments, type de voix, style de production.
- Gardez les paroles concises et alignées sur la durée choisie pour éviter une phraséologie précipitée vers la fin.
- Verrouillez la graine tout en affinant l'invite, puis variez la graine pour explorer des arrangements alternatifs avec le même brief.
- Commencez par des durées plus courtes pour valider la direction, puis augmentez une fois que le son de base fonctionne.
- Le conditionnement négatif est désactivé par conception; activez et ajustez une véritable invite négative uniquement si vous avez besoin d'exclusions strictes après une exploration initiale.
Remerciements#
Ce workflow met en œuvre et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy.org pour le workflow Audio ACE Step 1.5 XL Turbo, et Comfy-Org pour le modèle de diffusion ACE-Step 1.5XL Turbo, le VAE ACE-Step 1.5, l'encodeur de texte ACE-Step 1.5 0.6B, et l'encodeur de texte ACE-Step 1.5 4B pour leurs contributions et leur maintenance. Pour des détails autoritaires, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- Comfy.org/Audio ACE Step 1.5 XL Turbo workflow
- Docs / Notes de version : Page du workflow
- Comfy-Org/ACE-Step 1.5XL Turbo diffusion model
- Hugging Face : acestep_v1.5_xl_turbo_bf16.safetensors
- Comfy-Org/ACE-Step 1.5 VAE
- Hugging Face : ace_1.5_vae.safetensors
- Comfy-Org/ACE-Step 1.5 text encoder 0.6B
- Hugging Face : qwen_0.6b_ace15.safetensors
- Comfy-Org/ACE-Step 1.5 text encoder 4B
- Hugging Face : qwen_4b_ace15.safetensors
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.