
ACE-Step 1.5XL Base texte en musique: Flux de travail prompt-à-chanson pour ComfyUI#
Ce flux de travail transforme des descriptions en langage naturel en audio fini en utilisant la famille de diffusion ACE-Step 1.5XL Base. Il associe le modèle de base à son VAE ACE Step et ses doubles encodeurs de texte Qwen pour maintenir les résultats fermement dans le domaine musical plutôt que dans la synthèse vocale ou la parole. Si vous souhaitez de la musique AI pilotée par des invites avec une structure, des tempos et une instrumentation prévisibles, ce pipeline ACE-Step 1.5XL Base texte en musique est une configuration minimale et ciblée qui vous amène de l'idée au MP3 rapidement.
Conçu pour les producteurs, concepteurs sonores et créateurs, le graphique met l'accent sur la clarté: choisissez les modèles, définissez une durée, écrivez une invite musicale, puis générez et enregistrez. Le flux de travail ACE-Step 1.5XL Base texte en musique est suffisamment compact pour des itérations rapides tout en restant expressif pour des arrangements détaillés, des tonalités et des tempos.
Modèles clés dans le flux de travail Comfyui ACE-Step 1.5XL Base texte en musique#
- Modèle de diffusion ACE-Step 1.5 XL Base (bf16). L'épine dorsale générative qui débruite les latents audio en phrases musicales cohérentes et textures. Fichier modèle
- VAE ACE Step 1.5. L'autoencodeur variationnel couplé qui encode/décode entre l'espace latent et le domaine de forme d'onde, préservant le timbre et les équilibres de mixage. Fichier modèle
- Encodeur de texte Qwen 4B ACE15. Un grand encodeur de texte adapté pour ACE qui capture des sémantiques musicales riches, des structures et des indices d'arrangement à partir de l'invite. Fichier modèle
- Encodeur de texte Qwen 0.6B ACE15. Un encodeur adapté ACE plus léger qui privilégie la vitesse et l'efficacité des ressources tout en conservant une forte compréhension des invites. Fichier modèle
Comment utiliser le flux de travail Comfyui ACE-Step 1.5XL Base texte en musique#
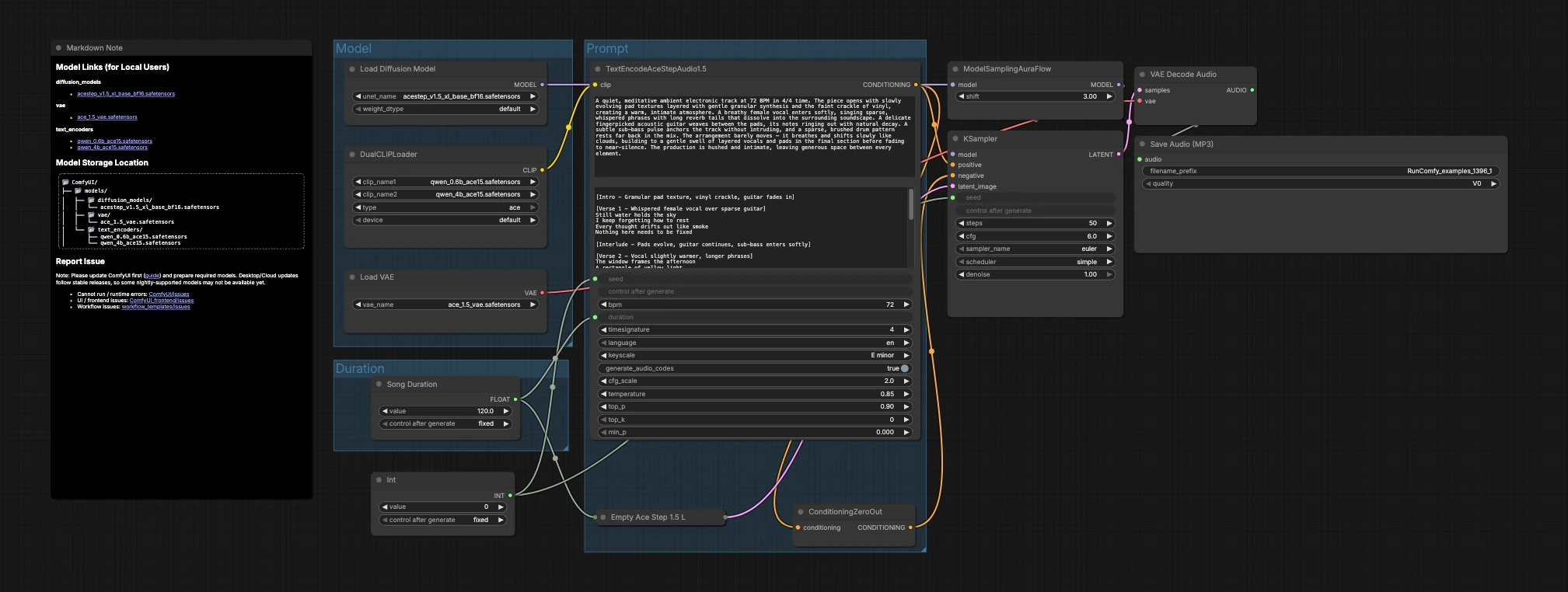
Le graphique est organisé en trois groupes qui s'écoulent vers la génération et l'exportation : Modèle, Durée et Invite. Vous chargez les modèles, choisissez une longueur cible, décrivez la musique, puis l'échantillonneur crée des latents que le VAE décode en audio.
Modèle#
Ce groupe charge les actifs principaux. UNETLoader (#104) sélectionne le point de contrôle de diffusion ACE-Step 1.5 XL Base, et VAELoader (#106) charge le VAE ACE Step 1.5 correspondant afin que la qualité du décodage soit alignée avec la formation. DualCLIPLoader (#105) intègre les deux encodeurs Qwen ACE15 ; le flux de travail les utilise conjointement pour que les invites textuelles riches se traduisent par un conditionnement musical fort.
Durée#
Ici, vous décidez de la durée de la pièce. Song Duration (#99) définit la longueur cible en secondes et la transmet pour que la toile latente et le conditionnement textuel s'accordent. PrimitiveInt (#109) fournit une graine, vous permettant de verrouiller des résultats exacts pour la reproductibilité ou de la varier pour explorer des alternatives.
Invite#
C'est ici que le langage devient musique. Écrivez votre description dans TextEncodeAceStepAudio1.5 (#94), incluant des métadonnées musicales utiles telles que le tempo (BPM), la mesure, la tonalité, l'arrangement, la présence vocale et les notes de mixage. Le nœud émet le conditionnement positif ; ConditioningZeroOut (#47) fournit un chemin négatif neutre pour que la génération reste concentrée sur votre description. EmptyAceStep1.5LatentAudio (#98) initialise une chronologie audio latente pour la durée choisie. ModelSamplingAuraFlow (#78) adapte le modèle de base à un planificateur adapté à l'audio ACE-Step. KSampler (#3) combine le modèle, le conditionnement, le latent et la graine pour générer le latent musical. VAEDecodeAudio (#18) convertit le latent en forme d'onde, et SaveAudioMP3 (#107) écrit le résultat dans un fichier MP3 prêt à être partagé.
Nœuds clés dans le flux de travail Comfyui ACE-Step 1.5XL Base texte en musique#
TextEncodeAceStepAudio1.5 (#94)#
Transforme votre invite en conditionnement que le modèle de diffusion peut suivre. Il accepte des détails musicaux comme le tempo, la signature temporelle, la tonalité, les notes d'arrangement, l'instrumentation, le langage et l'intention vocale optionnelle. Pour de meilleurs résultats, soyez concret sur le genre, l'ambiance et le placement du mix, et gardez les indices structurels concis pour que le modèle puisse maintenir la cohérence sur la durée demandée.
EmptyAceStep1.5LatentAudio (#98)#
Crée la "toile" audio latente pour la pièce. Faites correspondre ses secondes à ce que vous avez défini dans Song Duration (#99) et référencé dans l'encodeur de texte pour éviter les troncations ou les remplissages involontaires. Les toiles plus longues invitent à un développement plus progressif, tandis que les toiles plus courtes conviennent aux boucles, signaux et jingles.
ModelSamplingAuraFlow (#78)#
Configure la stratégie d'échantillonnage adaptée à l'audio ACE-Step. Utilisez-le tel quel pour des résultats stables ; ajustez uniquement si vous avez une préférence de planificateur spécifique, car il interagit avec le nombre d'étapes et le guidage dans KSampler (#3).
KSampler (#3)#
Effectue le débruitage qui transforme le conditionnement en latents audio. Les leviers clés ici sont le type d'échantillonneur, le nombre d'étapes et la graine. Augmentez les étapes pour affiner les détails au détriment du temps, et gardez la graine fixe lors de la comparaison des invites pour pouvoir attribuer les changements au texte plutôt qu'au hasard.
DualCLIPLoader (#105)#
Charge les deux encodeurs de texte Qwen ACE15. Si vous avez accès aux deux, commencez avec l'encodeur 4B actif pour une compréhension linguistique plus riche ; passez à la variante 0.6B lorsque vous avez besoin de cycles plus rapides ou d'une utilisation de mémoire réduite. Gardez le choix de l'encodeur constant entre les prises lors de l'évaluation des modifications d'invite subtiles.
ConditioningZeroOut (#47)#
Fournit un chemin négatif neutre. Si vous souhaitez supprimer des artefacts spécifiques ou vous éloigner du contenu parlé, vous pouvez remplacer cela par un nœud d'invite négative réel ; sinon, le négatif mis à zéro garde la génération ACE-Step 1.5XL Base texte en musique concentrée sur votre description positive.
Extras optionnels#
- Commencez les invites avec une recette compacte : genre + ambiance + tempo + mesure + tonalité + instrumentation + arrangement + notes de mixage.
- Utilisez des verbes et des rôles musicaux explicites (lead, pad, basse, percussion) pour que le modèle alloue de l'espace dans le mix et évite le contenu de type parole.
- Fixez la graine lors des tests A/B des invites, puis variez la graine pour explorer des performances alternatives d'une idée gagnante.
- Gardez la durée alignée entre
Song Duration(#99),TextEncodeAceStepAudio1.5(#94) etEmptyAceStep1.5LatentAudio(#98) pour un phrasé prévisible. - Choisissez Qwen 4B pour une compréhension plus riche des invites ou 0.6B pour la vitesse ; gardez votre choix constant pendant que vous itérez pour que les comparaisons soient équitables.
Remerciements#
Ce flux de travail implémente et s'appuie sur les travaux et ressources suivants. Nous remercions chaleureusement Comfy.org pour le flux de travail audio_ace_step1_5_xl_base, Comfy-Org pour le modèle de diffusion ACE Step 1.5 XL Base et le VAE ACE Step 1.5, et l'équipe Qwen pour les encodeurs de texte 0.6B et 4B ACE15 pour leurs contributions et leur maintenance. Pour des détails authentiques, veuillez vous référer à la documentation et aux dépôts originaux liés ci-dessous.
Ressources#
- Comfy.org/Page source du flux de travail
- Docs / Notes de version : page du flux de travail audio_ace_step1_5_xl_base
- Comfy-Org/Modèle de diffusion ACE Step 1.5 XL Base
- Hugging Face : acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/VAE ACE Step 1.5
- Hugging Face : ace_1.5_vae.safetensors
- Comfy-Org/Encodeur de texte Qwen 0.6B ACE15
- Hugging Face : qwen_0.6b_ace15.safetensors
- Comfy-Org/Encodeur de texte Qwen 4B ACE15
- Hugging Face : qwen_4b_ace15.safetensors
Note : L'utilisation des modèles, ensembles de données et codes référencés est soumise aux licences et conditions respectives fournies par leurs auteurs et mainteneurs.