
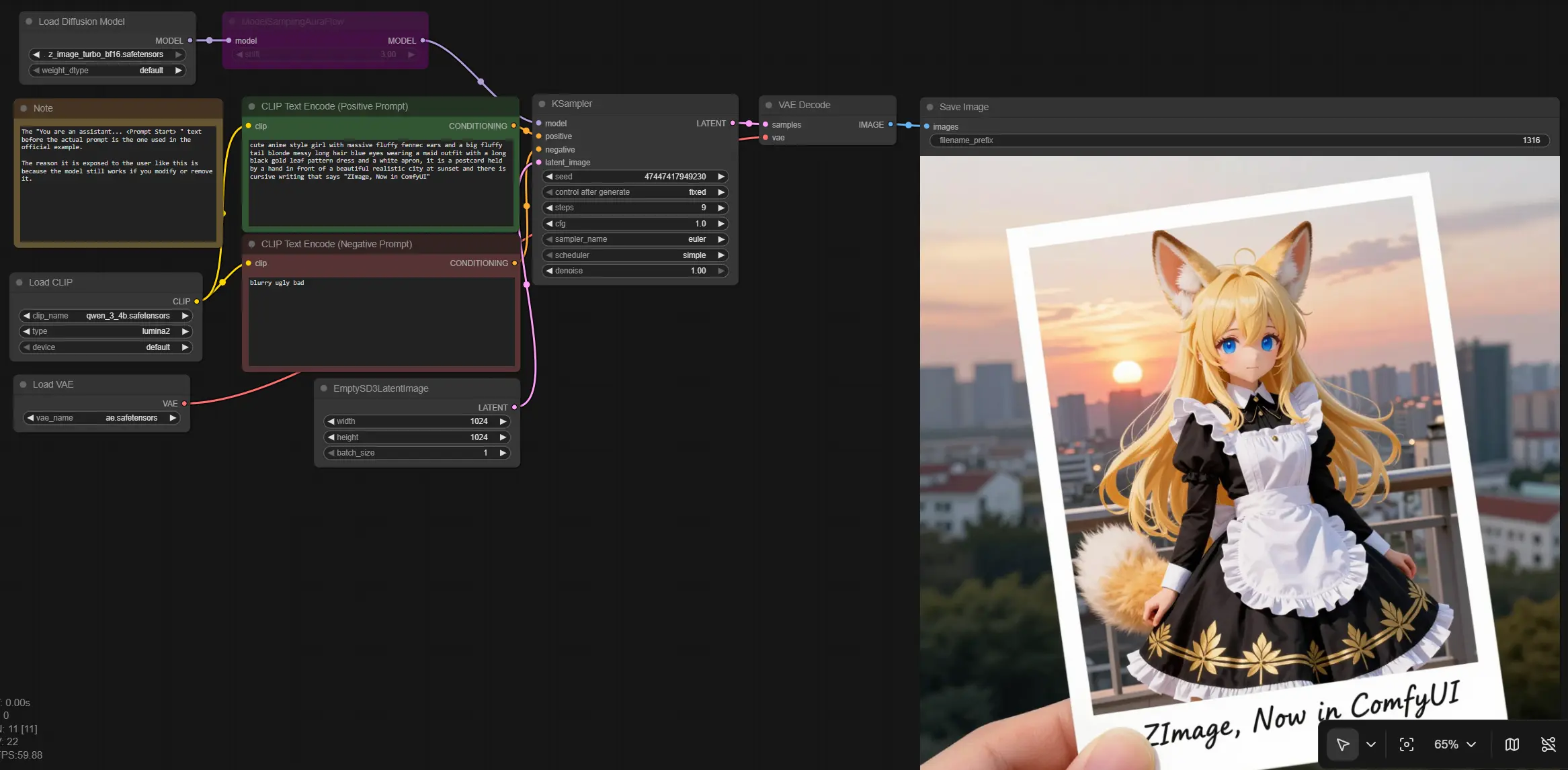







Z Image Turbo para ComfyUI: texto a imagen rápido con iteración casi en tiempo real#
Este flujo de trabajo lleva Z Image Turbo a ComfyUI para que puedas generar visuales de alta resolución y fotorrealistas con muy pocos pasos y una estricta adherencia al prompt. Está diseñado para creadores que necesitan renders rápidos y consistentes para arte conceptual, composiciones publicitarias, medios interactivos y pruebas A/B rápidas.
El gráfico sigue un camino limpio desde los prompts de texto hasta una imagen: carga el modelo Z Image y los componentes de soporte, codifica prompts positivos y negativos, crea un lienzo latente, realiza muestras con una programación AuraFlow, y luego decodifica a RGB para guardar. El resultado es una canalización de Z Image optimizada que favorece la velocidad sin sacrificar el detalle.
Modelos clave en el flujo de trabajo Z Image de ComfyUI#
- Tongyi-MAI Z Image Turbo. El generador principal que realiza la reducción de ruido de manera destilada y eficiente en pasos. Apunta al fotorrealismo, texturas nítidas y composición fiel mientras mantiene baja la latencia. Model card
- Codificador de texto Qwen 4B (qwen_3_4b.safetensors). Proporciona condicionamiento lingüístico para el modelo de modo que el estilo, el sujeto y la composición en tu prompt guíen la trayectoria de reducción de ruido.
- Autoencoder AE (ae.safetensors). Traduce entre el espacio latente y los píxeles para que el resultado final de Z Image pueda ser visto y exportado.
Cómo usar el flujo de trabajo Z Image de ComfyUI#
A un nivel alto, el camino va del prompt al condicionamiento, a través del muestreo de Z Image, luego decodificando a una imagen. Los nodos están agrupados en etapas para mantener la operación simple.
Cargadores de modelo: UNETLoader (#16), CLIPLoader (#18), VAELoader (#17)#
Esta etapa carga el punto de control principal de Z Image Turbo, el codificador de texto y el autoencoder. Elige el punto de control BF16 si lo tienes, ya que equilibra velocidad y calidad para GPUs de consumo. El codificador de estilo CLIP asegura que tu redacción controle la escena y el estilo. El AE es necesario para convertir latentes de nuevo a RGB una vez que finaliza el muestreo.
Prompts: CLIP Text Encode (Positive Prompt) (#6) y CLIP Text Encode (Negative Prompt) (#7)#
Escribe lo que deseas en el prompt positivo usando sustantivos concretos, indicaciones de estilo, pistas de cámara e iluminación. Usa el prompt negativo para suprimir artefactos comunes como el desenfoque u objetos no deseados. Si ves un prefacio de prompt como un encabezado de instrucciones de un ejemplo oficial, puedes mantenerlo, editarlo o eliminarlo y el flujo de trabajo seguirá funcionando. Juntos, estos codificadores producen el condicionamiento que dirige Z Image durante el muestreo.
Latente y programador: EmptySD3LatentImage (#13) y ModelSamplingAuraFlow (#11)#
Elige tu tamaño de salida configurando el lienzo latente. El nodo programador cambia el modelo a una estrategia de muestreo estilo AuraFlow que se alinea bien con modelos destilados eficientes en pasos. Esto mantiene las trayectorias estables a bajas cuentas de pasos mientras preserva el detalle fino. Una vez que se establecen el lienzo y el programa, la canalización está lista para reducir el ruido.
Muestreo: KSampler (#3)#
Este nodo realiza la reducción de ruido real utilizando el modelo Z Image cargado, el programador seleccionado y tu condicionamiento de prompt. Ajusta el tipo de muestreador y la cuenta de pasos para intercambiar velocidad por detalle cuando sea necesario. La escala de guía controla la fuerza del prompt en relación con el anterior; los valores moderados generalmente dan el mejor equilibrio de fidelidad y variación creativa. Aleatoriza la semilla para la exploración o fíjala para obtener resultados repetibles.
Decodificar y guardar: VAEDecode (#8) y SaveImage (#9)#
Después del muestreo, el AE decodifica latentes a una imagen. El nodo de guardado escribe archivos en tu directorio de salida para que puedas comparar iteraciones o alimentar resultados en tareas posteriores. Si planeas escalar o procesar posteriormente, mantén la decodificación en tu resolución de trabajo deseada y exporta formatos sin pérdida para la mejor retención de calidad.
Nodos clave en el flujo de trabajo Z Image de ComfyUI#
UNETLoader (#16)#
Carga el punto de control Z Image Turbo (z_image_turbo_bf16.safetensors). Usa esto para cambiar entre variantes de precisión o pesos actualizados a medida que estén disponibles. Mantén el modelo consistente a lo largo de una sesión si deseas que las semillas y los prompts permanezcan comparables. Cambiar el modelo base cambiará el aspecto, la respuesta de color y la densidad del detalle.
ModelSamplingAuraFlow (#11)#
Establece la estrategia de muestreo a un programa estilo AuraFlow adecuado para una convergencia rápida. Esta es la clave para hacer que Z Image sea eficiente a bajas cuentas de pasos mientras preserva el detalle y la coherencia. Si cambias los programas más tarde, revisa las cuentas de pasos y la guía para mantener características de salida similares.
KSampler (#3)#
Controla el algoritmo de muestreo, pasos, guía y semilla. Usa menos pasos para la ideación rápida y aumenta solo cuando necesites más microdetalle o una adherencia más estricta al prompt. Diferentes muestreadores favorecen diferentes aspectos; prueba un par y mantén el resto de la canalización fija al comparar resultados.
CLIP Text Encode (Positive Prompt) (#6)#
Codifica la intención creativa que impulsa Z Image. Enfócate en el sujeto, medio, lente, iluminación, composición y cualquier restricción de marca o diseño. Combínalo con el nodo de prompt negativo para orientar la imagen hacia tu aspecto objetivo mientras filtras artefactos conocidos.
Extras opcionales#
- Usa resoluciones cuadradas o casi cuadradas para la primera pasada, luego ajusta la relación de aspecto una vez que la composición esté bloqueada.
- Mantén una biblioteca de fragmentos de prompt reutilizables para sujetos, lentes e iluminación para acelerar la iteración en proyectos.
- Para una dirección de arte consistente, fija la semilla y varía solo un factor por iteración como una etiqueta de estilo o una pista de cámara.
- Si las salidas se sienten demasiado controladas, reduce la guía ligeramente o elimina frases excesivamente prescriptivas del prompt positivo.
- Al preparar activos para la edición posterior, exporta PNGs sin pérdida y mantén un registro del prompt, semilla y resolución junto a cada render de Z Image.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Tongyi-MAI por Z-Image-Turbo por sus contribuciones y mantenimiento. Para detalles autorizados, consulta la documentación original y los repositorios enlazados a continuación.
Recursos#
- Tongyi-MAI/Z-Image-Turbo
- Hugging Face: Tongyi-MAI/Z-Image-Turbo
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.