








Flujo de trabajo de Z Image ControlNet para generación de imágenes guiada por la estructura en ComfyUI#
Este flujo de trabajo lleva Z Image ControlNet a ComfyUI para que puedas dirigir Z‑Image Turbo con estructura precisa a partir de imágenes de referencia. Agrupa tres modos de guía en un gráfico: profundidad, bordes canny y pose humana, y te permite cambiar entre ellos para adaptarse a tu tarea. El resultado es una generación rápida y de alta calidad de texto o imagen a imagen donde la disposición, pose y composición permanecen bajo control mientras iteras.
Diseñado para artistas, diseñadores conceptuales y planificadores de disposiciones, el gráfico admite indicaciones bilingües y estilización opcional con LoRA. Obtienes una vista previa limpia de la señal de control elegida, además de una tira de comparación automática para evaluar la profundidad, canny o pose frente al resultado final.
Modelos clave en el flujo de trabajo Comfyui Z Image ControlNet#
- Modelo de difusión Z‑Image Turbo con 6B parámetros. Generador principal que produce imágenes fotorrealistas rápidamente a partir de indicaciones y señales de control. alibaba-pai/Z-Image-Turbo
- Parche de Unión Z Image ControlNet. Añade control de múltiples condiciones a Z‑Image Turbo y permite la guía de profundidad, borde y pose en un modelo de parche. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. Produce mapas de profundidad densos usados para la guía de estructura en modo profundidad. LiheYoung/Depth-Anything-V2 en GitHub
- DWPose. Estima puntos clave humanos y pose corporal para generación guiada por pose. IDEA-Research/DWPose
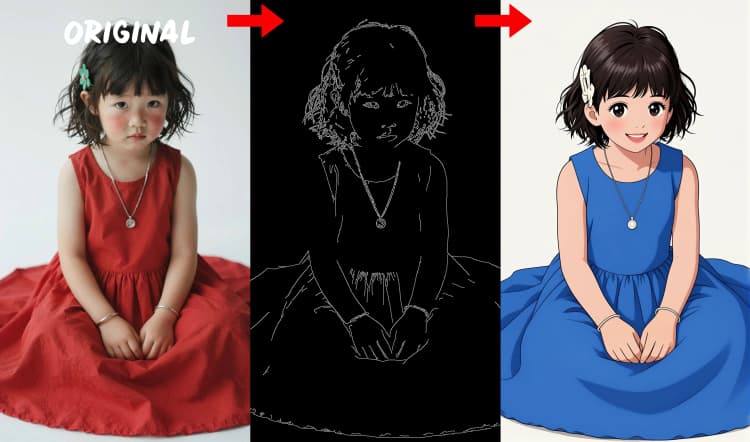
- Detector de bordes Canny. Extrae arte lineal limpio y límites para control dirigido por disposición.
- Preprocesadores Aux de ControlNet para ComfyUI. Proporciona envoltorios unificados para profundidad, bordes y pose usados por este gráfico. comfyui_controlnet_aux
Cómo usar el flujo de trabajo Comfyui Z Image ControlNet#
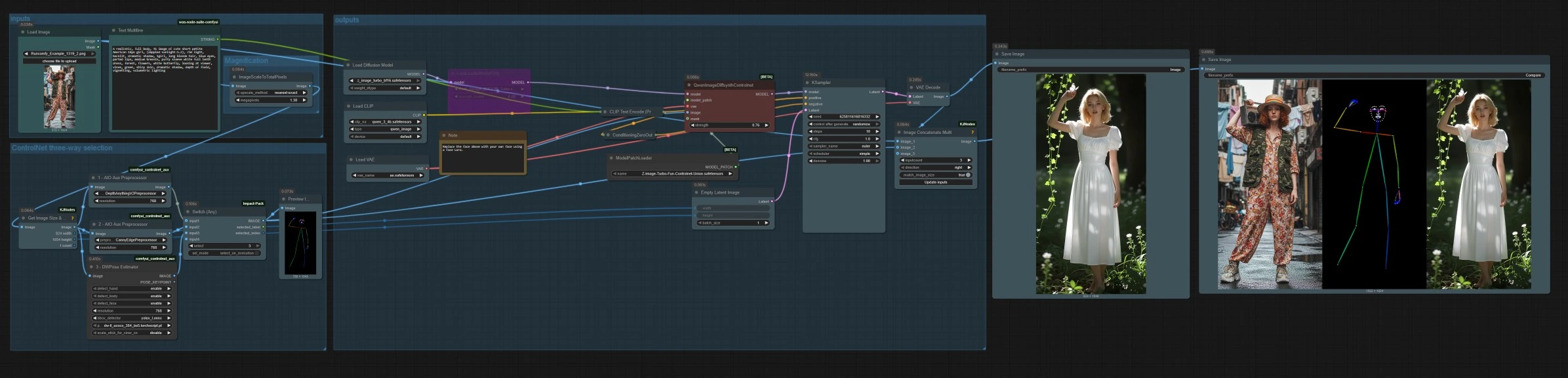
A un nivel alto, cargas o subes una imagen de referencia, seleccionas un modo de control entre profundidad, canny o pose, luego generas con una indicación de texto. El gráfico escala la referencia para un muestreo eficiente, construye un latente a la relación de aspecto coincidente, y guarda tanto la imagen final como una tira de comparación lado a lado.
entradas#
Usa LoadImage (#14) para elegir una imagen de referencia. Ingresa tu indicación textual en Text Multiline (#17), el conjunto Z‑Image admite indicaciones bilingües. La indicación es codificada por CLIPLoader (#2) y CLIPTextEncode (#4). Si prefieres una imagen-a-imagen puramente guiada por estructura, puedes dejar la indicación mínima y depender de la señal de control seleccionada.
Selección de tres vías de ControlNet#
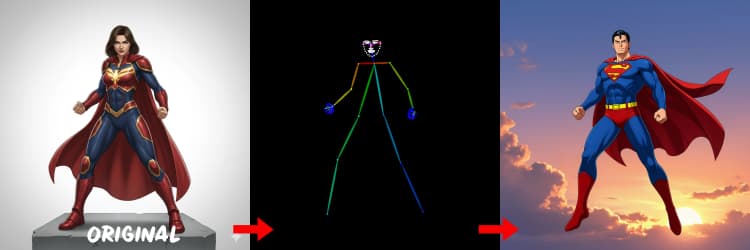
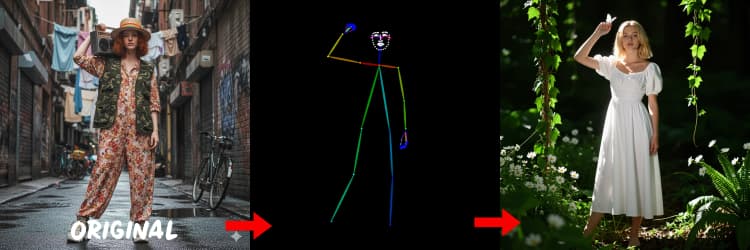
Tres preprocesadores convierten tu referencia en señales de control. AIO_Preprocessor (#45) produce profundidad con Depth Anything v2, AIO_Preprocessor (#46) extrae bordes canny, y DWPreprocessor (#56) estima pose corporal completa. Usa ImpactSwitch (#58) para seleccionar qué señal impulsa Z Image ControlNet, y verifica PreviewImage (#43) para confirmar el mapa de control elegido. Elige profundidad cuando desees geometría de escena, canny para una disposición nítida o tomas de productos, y pose para trabajos de personajes.
Consejos para OpenPose: 1. Mejor para Cuerpo Completo: OpenPose funciona mejor (~70-90% de precisión) cuando incluyes "cuerpo completo" en tu indicación. 2. Evitar para Primeros Planos: La precisión cae significativamente en rostros. Usa Profundidad o Canny (baja/media fuerza) para primeros planos en su lugar. 3. Las Indicaciones Importan: Las indicaciones influyen fuertemente en ControlNet. Evita indicaciones vacías para prevenir resultados confusos.
Magnificación#
ImageScaleToTotalPixels (#34) redimensiona la referencia a una resolución de trabajo práctica para equilibrar calidad y velocidad. GetImageSizeAndCount (#35) lee el tamaño escalado y pasa el ancho y la altura hacia adelante. EmptyLatentImage (#6) crea un lienzo latente que coincide con el aspecto de tu entrada redimensionada para que la composición se mantenga consistente.
salidas#
QwenImageDiffsynthControlnet (#39) fusiona el modelo base con el parche de unión Z Image ControlNet y la imagen de control seleccionada, luego KSampler (#7) genera el resultado guiado por tu condicionamiento positivo y negativo. VAEDecode (#8) convierte el latente a una imagen. El flujo de trabajo guarda dos salidas SaveImage (#31) escribe la imagen final, y SaveImage (#42) escribe una tira de comparación a través de ImageConcatMulti (#38) que incluye la fuente, el mapa de control y el resultado para QA rápido.
Nodos clave en el flujo de trabajo Comfyui Z Image ControlNet#
ImpactSwitch (#58)#
Elige qué imagen de control impulsa la generación: profundidad, canny o pose. Cambia modos para comparar cómo cada restricción da forma a la composición y detalle. Úsalo al iterar disposiciones para probar rápidamente qué guía se adapta mejor a tu objetivo.
QwenImageDiffsynthControlnet (#39)#
Conecta el modelo base, el parche de unión Z Image ControlNet, el VAE y la señal de control seleccionada. El parámetro strength determina qué tan estrictamente el modelo sigue la entrada de control frente a la indicación. Para una coincidencia de disposición estricta, aumenta la fuerza para más variación creativa, redúcela.
AIO_Preprocessor (#45)#
Ejecuta la canalización Depth Anything v2 para crear mapas de profundidad densos. Aumenta la resolución para una estructura más detallada o reduce para previsualizaciones más rápidas. Se complementa bien con escenas arquitectónicas, tomas de productos y paisajes donde la geometría importa.
DWPreprocessor (#56)#
Genera mapas de pose adecuados para personas y personajes. Funciona mejor cuando las extremidades son visibles y no están fuertemente ocultas. Si faltan manos o piernas, intenta una referencia más clara o un marco diferente con más visibilidad corporal completa.
LoraLoaderModelOnly (#54)#
Aplica un LoRA opcional al modelo base para pistas de estilo o identidad. Ajusta strength_model para mezclar el LoRA suavemente o con fuerza. Puedes intercambiar un LoRA de rostro para personalizar sujetos o usar un LoRA de estilo para fijar un aspecto específico.
KSampler (#7)#
Realiza muestreo de difusión usando tu indicación y control. Ajusta seed para reproducibilidad, steps para presupuesto de refinamiento, cfg para adherencia a la indicación, y denoise para cuánto puede desviarse el resultado del latente inicial. Para ediciones de imagen a imagen, baja denoise para preservar la estructura; valores más altos permiten cambios mayores.
Extras opcionales#
- Para apretar la composición, usa el modo de profundidad con una referencia limpia e iluminada uniformemente; canny favorece un contraste fuerte, y pose favorece tomas de cuerpo completo.
- Para ediciones sutiles a partir de una imagen fuente, mantén
denoisemodesto y aumenta la fuerza de ControlNet para una estructura fiel. - Aumenta los píxeles objetivo en el grupo de Magnificación cuando necesites más detalle, luego reduce de nuevo para borradores rápidos.
- Usa la salida de comparación para probar rápidamente A/B profundidad vs canny vs pose y elige el control más confiable para tu sujeto.
- Reemplaza el LoRA de ejemplo con tu propio LoRA de rostro o estilo para incorporar identidad o dirección artística sin reentrenamiento.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a Alibaba PAI por Z Image ControlNet por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación y repositorios originales enlazados a continuación.
Recursos#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

