
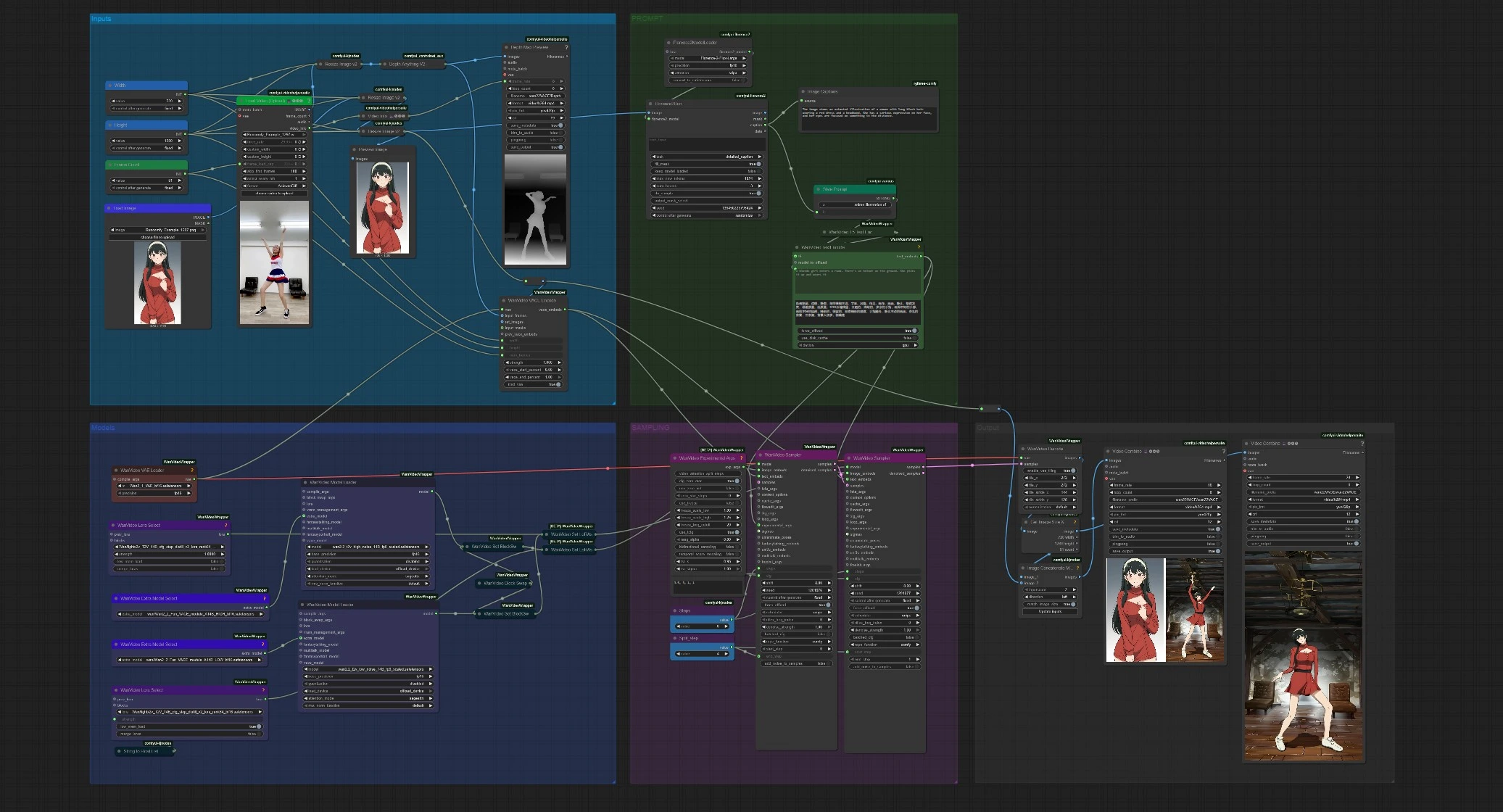
Generación de video impulsada por pose Wan 2.2 VACE para ComfyUI#
Este flujo de trabajo de ComfyUI Wan 2.2 VACE convierte una sola imagen de referencia en un video que sigue la pose, el ritmo y el movimiento de cámara de un clip fuente. Usa Wan 2.2 VACE para preservar la identidad mientras traduce el movimiento corporal complejo en animación suave y realista.
Diseñado para generación de danza, transferencia de movimiento y animación creativa de personajes, el flujo de trabajo automatiza la sugerencia de estilo desde la imagen de referencia, extrae señales de movimiento del video fuente y ejecuta un muestreador Wan 2.2 de dos etapas que equilibra la coherencia del movimiento y el detalle fino.
Modelos clave en el flujo de trabajo ComfyUI Wan 2.2 VACE#
- Modelos de texto a video Wan 2.2 14B (variantes de alto ruido y bajo ruido). Las dos etapas utilizan un modelo base de alto ruido para dar forma robusta al movimiento, seguido por un modelo base de bajo ruido para el refinamiento de detalles.
- Wan 2.1 VAE (bf16). Decodifica y codifica fotogramas de video latentes para Wan 2.2 VACE.
- Google UMT5-XXL Encoder. Proporciona características de texto de alta capacidad utilizadas por Wan 2.2 para el acondicionamiento. Model card
- Microsoft Florence-2 (Flux Large). Genera una rica leyenda de la imagen de referencia para iniciar y estilizar el prompt. Repo
- Depth Anything v2 (ViT-L). Produce mapas de profundidad por fotograma del video fuente de movimiento para guiar la estructura y el movimiento. Repo
Cómo usar el flujo de trabajo ComfyUI Wan 2.2 VACE#
El flujo de trabajo tiene cinco etapas agrupadas: Entradas, PROMPT, Modelos, MUESTREO y Salida. Proporcionas una imagen de referencia y un corto video de movimiento. El gráfico luego calcula la guía de movimiento, codifica las características de identidad VACE, ejecuta un muestreador Wan 2.2 de dos pasos y guarda tanto la animación final como una vista previa opcional lado a lado.
Entradas#
Carga un clip fuente de movimiento en VHS_LoadVideo (#141). Puedes recortar con controles simples y limitar fotogramas para memoria. Los fotogramas se redimensionan para consistencia, luego DepthAnythingV2Preprocessor (#135) calcula una secuencia de profundidad densa que captura pose, distribución y movimiento de cámara. Carga tu imagen de identidad con LoadImage (#113); se redimensiona automáticamente y se previsualiza para que puedas verificar el encuadre antes del muestreo.
PROMPT#
Florence2Run (#137) analiza la imagen de referencia y devuelve una leyenda detallada. Style Prompt (#138) concatena esa leyenda con una breve frase de estilo, luego WanVideoTextEncode (#16) codifica los prompts positivos y negativos finales usando UMT5-XXL. Puedes editar libremente la frase de estilo o reemplazar el prompt positivo por completo si deseas una dirección creativa más fuerte. Este embedding de prompt condiciona ambas etapas del muestreador para que el video generado sea fiel a tu referencia.
Modelos#
WanVideoVAELoader (#38) carga el Wan VAE usado en toda la codificación/decodificación. Dos nodos WanVideoModelLoader preparan los modelos Wan 2.2 14B: uno de alto ruido y uno de bajo ruido, cada uno aumentado con un módulo VACE seleccionado en WanVideoExtraModelSelect (#99, #107). La refinación opcional LoRA se adjunta a través de WanVideoLoraSelect (#56, #97), permitiéndote ajustar nitidez o estilo sin cambiar los modelos base. La configuración está diseñada para que puedas intercambiar pesos VACE, LoRA o la variante de ruido sin tocar el resto del gráfico.
MUESTREO#
WanVideoVACEEncode (#100) fusiona tres señales en embeddings VACE: la secuencia de movimiento (fotogramas de profundidad), tu imagen de referencia y la geometría del video objetivo. El primer WanVideoSampler (#27) ejecuta el modelo de alto ruido hasta un paso de división para establecer movimiento, perspectiva y estilo global. El segundo WanVideoSampler (#90) retoma desde ese latente y termina con el modelo de bajo ruido para recuperar texturas, bordes y pequeños detalles mientras mantiene el movimiento bloqueado a la fuente. Un corto programa de CFG y la división de pasos controlan cuánto influye cada etapa en el resultado.
Salida#
WanVideoDecode (#28) convierte el latente final de nuevo en fotogramas. Obtienes dos videos guardados: un render limpio y un concat lado a lado que coloca los fotogramas generados junto a la referencia para una rápida QA. Una "Vista previa del mapa de profundidad" separada muestra la secuencia de profundidad inferida para que puedas diagnosticar la guía de movimiento de un vistazo. Las configuraciones de velocidad de fotogramas y nombre de archivo están disponibles en las salidas VHS_VideoCombine (#139, #60, #144).
Nodos clave en el flujo de trabajo ComfyUI Wan 2.2 VACE#
WanVideoVACEEncode (#100)#
Crea los embeddings de identidad y geometría VACE usados por ambos muestreadores. Proporciona tus fotogramas de movimiento y la imagen de referencia; el nodo maneja ancho, alto y cuenta de fotogramas. Si cambias la duración o el aspecto, mantén este nodo sincronizado para que los embeddings coincidan con la disposición de tu video objetivo.
WanVideoSampler (#27)#
Muestreador de primera etapa usando el modelo de alto ruido Wan 2.2. Ajusta steps, un corto programa cfg, y la división end_step para decidir cuánto de la trayectoria se asigna a la configuración de movimiento. Los cambios de movimiento o cámara más grandes se benefician de una división ligeramente más tardía.
WanVideoSampler (#90)#
Muestreador de segunda etapa usando el modelo de bajo ruido Wan 2.2. Establece start_step en el mismo valor de división para que continúe sin problemas desde la primera etapa. Si ves sobreafilado de textura o deriva, reduce los valores cfg posteriores o baja la fuerza LoRA.
DepthAnythingV2Preprocessor (#135)#
Extrae una secuencia de profundidad estable del video fuente. Usar profundidad como guía de movimiento ayuda a Wan 2.2 VACE a retener la disposición de la escena, la pose de la mano y la oclusión. Para iteración rápida, puedes redimensionar fotogramas de entrada más pequeños; para renders finales, alimenta fotogramas de mayor resolución para mejor fidelidad estructural.
WanVideoTextEncode (#16)#
Codifica los prompts positivos y negativos con UMT5-XXL. El prompt se autoconstruye desde Florence2Run, pero puedes sobrescribirlo para dirección artística. Mantén los prompts concisos; con guía de identidad VACE, menos palabras clave a menudo producen una transferencia de movimiento más limpia y menos restringida.
Extras opcionales#
- Elige clips de movimiento con separación clara de sujetos e iluminación consistente para las transferencias Wan 2.2 VACE más estables.
- Usa la salida lado a lado para verificar la alineación facial y la continuidad del atuendo antes de renderizar un pase final.
- Si el movimiento parece demasiado rígido, mueve la división un poco antes para que la etapa de bajo ruido tenga más espacio para refinar.
- Si la identidad está derivando, aumenta ligeramente la influencia LoRA o simplifica el prompt.
- La vista previa de profundidad es tu amiga: si la profundidad es ruidosa, prueba un clip fuente diferente o ajusta el redimensionamiento de entrada para reducir artefactos.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos profundamente a los creadores de la comunidad ComfyUI de Wan 2.2 VACE Source por el flujo de trabajo, por sus contribuciones y mantenimiento. Para obtener detalles autorizados, consulta la documentación original y los repositorios vinculados a continuación.
Recursos#
- Wan 2.2 VACE Source/Wan 2.2 VACE Source
- Documentos / Notas de Lanzamiento: Wan 2.2 VACE @ComfyUI
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.