
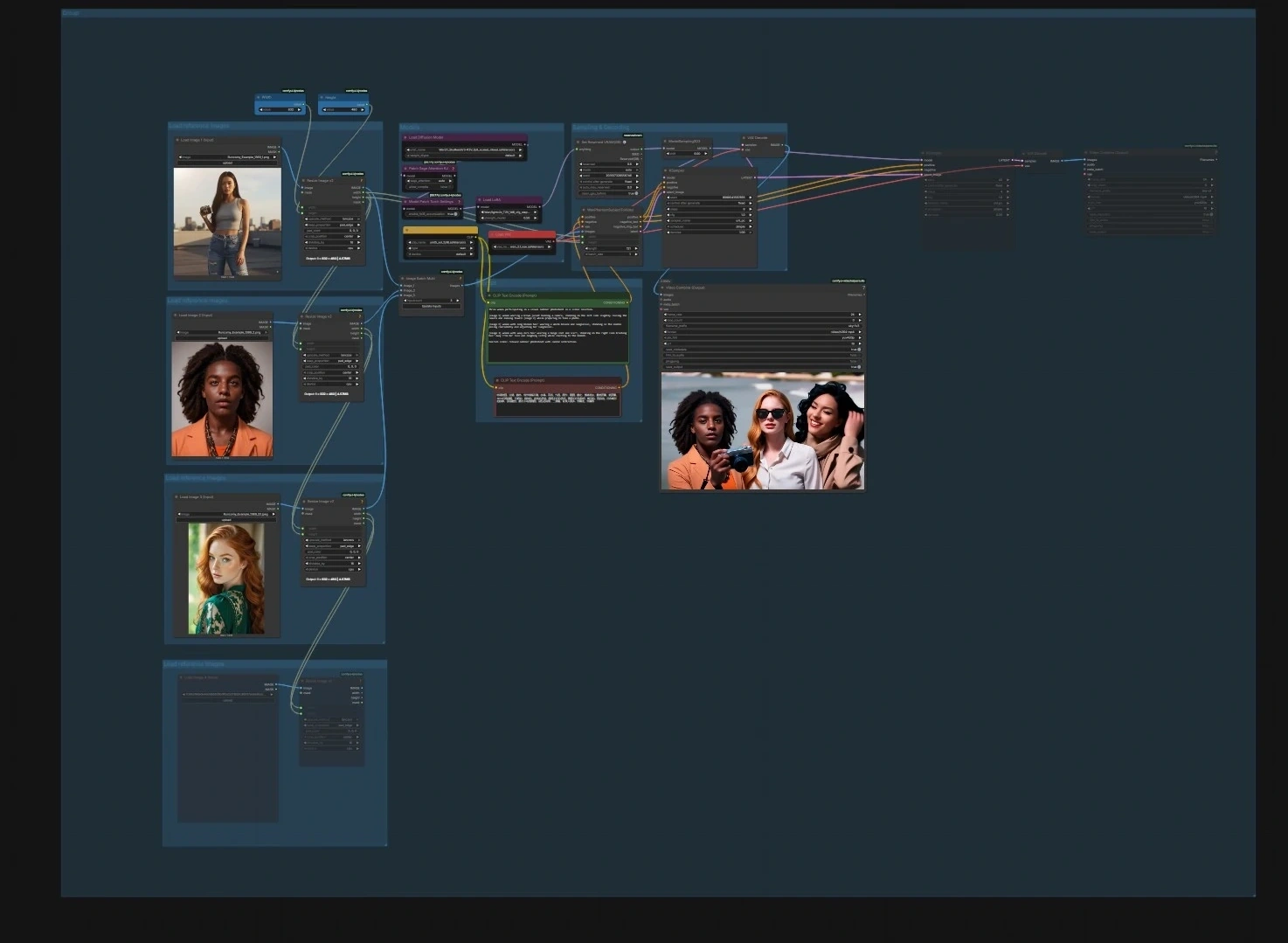
SkyReels V3 ComfyUI: creación de video fiel a la identidad a partir de imagen, video y audio#
SkyReels V3 ComfyUI es un flujo de trabajo listo para producción que lleva el modelo de video multimodal SkyReels V3 a ComfyUI para que puedas animar imágenes fijas, extender tomas existentes y construir avatares parlantes impulsados por audio con sincronización labial precisa. Está diseñado para creadores que desean movimiento cinematográfico, una identidad de sujeto fuerte y coherencia temporal mientras permanecen dentro de un gráfico de nodos flexible.
El flujo de trabajo viene con cuatro líneas de producción enfocadas que pueden ejecutarse de manera independiente o encadenadas: animación de personajes de imagen a video, continuación de video a video, avatares parlantes de audio a video y generación de la siguiente toma para el flujo de la historia. Cada camino incluye puntos de entrada claros y valores predeterminados sensatos para que puedas insertar tus activos y renderizar rápidamente salidas de alta calidad de SkyReels V3.
Nota para máquinas 2X Large y más grandes (flujo de trabajo R2V): Establecer
Patch Sage Attention KJ(#240)sage_attentionendisabledantes de ejecutar. Dejarlo habilitado puede desencadenar erroresSM90 kernel is not available.
Modelos clave en el flujo de trabajo Comfyui SkyReels V3 ComfyUI#
- Núcleos de video SkyReels V3 (R2V, V2V Shot, A2V) del paquete WanVideo FP8. Estos son los generadores principales que manejan el movimiento consciente de la identidad, la continuación de video y la sincronización labial condicionada por audio. Ver los pesos de SkyReels V3 en el paquete WanVideo en Hugging Face aquí.
- Modelos OpenCLIP Vision ViT para guía de imagen y embebido de referencia. Proporcionan características visuales robustas que ayudan a preservar el aspecto y estilo a través de los fotogramas. Página del proyecto: open_clip.
- Codificador de texto UMT5 para comprensión de indicaciones. Proporciona un condicionamiento de lenguaje rico para dirigir estilo, escena y acciones. Repositorio: umt5.
- Características de voz Wav2Vec2 para sincronización labial y análisis de audio. La variante base en chino está soportada de forma predeterminada y variantes similares en inglés también funcionan. Tarjeta del modelo: TencentGameMate/chinese-wav2vec2-base.
- Qwen3‑ASR‑1.7B para conversión de voz a texto. Se utiliza para transcribir audio de referencia y generar indicaciones TTS clonadas de voz. Tarjeta del modelo: Qwen/Qwen3-ASR-1.7B.
- MelBandRoFormer para separación vocal. Útil cuando necesitas pistas de voz limpias antes de embebido de sincronización labial. Tarjeta del modelo: Kijai/MelBandRoFormer_comfy.
- MiniCPM‑V para generación de indicaciones conscientes de la toma. Analiza metraje previo y propone la siguiente toma para la continuidad de la historia. Centro de modelos: OpenBMB/MiniCPM-V.
Cómo usar el flujo de trabajo Comfyui SkyReels V3 ComfyUI#
El gráfico está organizado en cuatro líneas de producción. Puedes ejecutar cualquiera por su cuenta o en secuencia para construir ediciones más largas.
Animación de personaje de imagen a video#
- Modelos. Carga el UNet, CLIP y VAE en el grupo de Modelos usando
UNETLoader(#241),CLIPLoader(#242) yVAELoader(#194). Los nodos de parche del modeloPathchSageAttentionKJ(#240) yModelPatchTorchSettings(#239) optimizan la atención y configuraciones matemáticas, mientras queLoraLoaderModelOnly(#250) te permite mezclar opcionalmente un LoRA de estilo o movimiento en el modelo SkyReels. - Cargar imágenes de referencia. Usa los tres grupos “Cargar imágenes de referencia” para importar 1–3 retratos o poses. Los ayudantes de redimensionamiento
ImageResizeKJv2(#291, #298, #299, #304) alinean la relación de aspecto y los agrupan; fotos de identidad más limpias producen resultados más estables. - Indicaciones. Ingresa texto de escena y acción en el grupo de Indicaciones con
CLIPTextEncode(#6) y un codificador de texto negativo opcionalCLIPTextEncode(#7) para alejar características no deseadas. Mantén el lenguaje conciso y específico para el movimiento y el encuadre. - Muestreo y decodificación.
WanPhantomSubjectToVideo(#249) fusiona tus referencias e indicaciones en un latente consciente de la identidad que alimentaKSampler(#149) a través deModelSamplingSD3(#48). Los fotogramas decodificados deVAEDecode(#264) se empaquetan en una película conVHS_VideoCombine(#280); establece tu tasa de fotogramas y formato de archivo allí.
Extensión de bucle de video a video#
- Video de entrada y configuraciones. Introduce tu clip de origen con
VHS_LoadVideo(#329). Establece cuántos segmentos adicionales generar y cuánta superposición entre segmentos usando los ayudantes de enteros “Número de Extensiones” (#342) y “Fotogramas Superpuestos” (#341).ImageResizeKJv2(#327) estandariza la resolución para el muestreador. - Extensión de muestreo de bucle de video. El par de bucles
easy forLoopStart(#331) yeasy forLoopEnd(#332) recorre el clip en ventanas para estabilizar transiciones. Cada ventana se codifica conWanVideoEncode(#326), recibe embebidos neutrales o de control a través deWanVideoEmptyEmbeds(#328), y se desruida porWanVideoSampler(#320) deWanVideoModelLoader(#319). Los fotogramas se decodifican conWanVideoDecode(#321) y se previsualizan o guardan conVHS_VideoCombine(#322, #335). - Ayudantes de rendimiento.
WanVideoTorchCompileSettings(#323) yWanVideoBlockSwap(#325) habilitan trucos de compilación y memoria para ejecuciones más largas o de mayor resolución.
Avatar parlante de audio a video#
- 1 – Crear audio. Puedes generar una pista de voz clonada con
FB_Qwen3TTSVoiceClonePrompt(#416) yFB_Qwen3TTSVoiceClone(#412), o cargar cualquier voz pregrabada conLoadAudio(#417).Qwen3ASRLoader(#414) másQwen3ASRTranscribe(#413) te ayudan a extraer texto de un clip de referencia para sembrar la indicación TTS si lo deseas. - 2 – Características de audio.
DownloadAndLoadWav2VecModel(#348) alimentaMultiTalkWav2VecEmbeds(#350) para crear embebidos de movimiento labial a partir de tu discurso; la longitud está alineada con el audio y previsualizable conPreviewAudio(#422). UsaAny Switch (rgthree)(#435) para elegir la salida TTS o tu archivo importado como la pista de conducción. - 3 – Imagen de entrada. Carga la cara parlante en el grupo “3 - Imagen de entrada” y ajústala con
ImageResizeKJv2(#370). Retratos limpios y frontales con iluminación consistente funcionan mejor. - Generación de video de referencia. Primero, crea un ancla visual corta a partir de la imagen fija usando
WanVideoImageToVideoEncode(#392). Las características de CLIP-Vision deCLIPVisionLoader(#352) yWanVideoClipVisionEncode(#351) estabilizan la identidad en la siguiente etapa; un programadorWanVideoSchedulerv2(#385) está preparado en el grupo de Configuración de Muestreo. - Generar sincronización labial de audio.
WanVideoImageToVideoSkyreelsv3_audio(#383) combina la imagen inicial, fotogramas de referencia opcionales y embebidos de CLIP-Vision en una condicionamiento de imagen.WanVideoSamplerv2(#384) luego desruida con el modelo SkyReels A2V mientrasWanVideoSamplerExtraArgs(#386) inyecta los embebidos de sincronización labialMultiTalkpara formas de boca precisas.WanVideoPassImagesFromSamples(#381) transmite fotogramas decodificados aVHS_VideoCombine(#346) donde el video final se multiplica con tu audio.
Generación de la siguiente toma de video a video#
- Preprocesamiento de fotogramas de video. Importa la toma anterior con
VHS_LoadVideo(#443) y redimensiónala a través deImageResizeKJv2(#441).GetImageRangeFromBatch(#445) selecciona un fragmento de contexto queWanVideoEncode(#440) convierte en latentes;WanVideoEmptyEmbeds(#442) prepara la ventana de condicionamiento. - Indicaciones automáticas de video.
CreateVideo(#450) ensambla un clip proxy compacto a partir de los fotogramas de contexto queAILab_MiniCPM_V_Advanced(#449) analiza para redactar una indicación de la siguiente toma. Inspecciona o refina el borrador enShowText|pysssss(#447) y embébelo conWanVideoTextEncodeCached(#444) antes de muestrear. - Modelos y muestreo. Carga el modelo V2V Shot con
WanVideoModelLoader(#436) yWanVideoVAELoader(#438);WanVideoBlockSwapopcional (#439) maneja VRAM. ElWanVideoSampler(#451) genera la continuación,WanVideoDecode(#437) renderiza los fotogramas, yVHS_VideoCombine(#446) produce la toma final. Esta ruta de SkyReels V3 ComfyUI es ideal para storyboards y previz donde cada nuevo corte debe respetar al anterior.
Nodos clave en el flujo de trabajo Comfyui SkyReels V3 ComfyUI#
WanPhantomSubjectToVideo(#249). Construye un latente consciente de la identidad a partir de tus imágenes de referencia agrupadas más indicaciones de texto, que luego impulsa el muestreador. Ajusta el número y la diversidad de referencias para equilibrar el bloqueo de semejanza frente al movimiento creativo; mantén los nodos de redimensionamiento que lo alimentan consistentes para evitar desviaciones. Referencia: WanVideo Wrapper en GitHub contiene notas de implementación y entradas esperadas ComfyUI‑WanVideoWrapper.WanVideoImageToVideoEncode(#392). Codifica una imagen fija en una semilla de toma estable y opcionalmente mezcla la guía de CLIP-Vision para pose y encuadre. Úsalo para crear fotogramas de anclaje antes de la etapa impulsada por audio para que la identidad y la configuración de la cámara permanezcan consistentes en todas las líneas de producción. Documentos del wrapper: ComfyUI‑WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). Prepara embebidos de imagen adaptados para el muestreador A2V y fusiona fotogramas de video de referencia opcionales. Asegúrate de que su ancho y alto coincidan con la ruta del muestreador; emparejalo conWanVideoSamplerv2yMultiTalkWav2VecEmbedspara una sincronización labial precisa.WanVideoSamplerv2(#384, #387). El desruidor principal para SkyReels V3 que acepta embebidos de imagen y texto más configuraciones de programador. Los nodosWanVideoSamplerExtraArgs(#386, #409) son donde se inyectan características de sincronización labial, bucle o contexto; mantén estos conectados al cambiar entre modelos A2V e I2V. Detalles de implementación: ComfyUI‑WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). Convierte el habla en embebidos alineados temporalmente que impulsan el movimiento de la boca. Hacer coincidir el presupuesto de fotogramas previsto y garantizar voces limpias mejora significativamente la precisión de los fonemas. Modelo de referencia Wav2Vec: TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). Analiza la toma anterior y redacta una indicación estructurada para personaje, fondo, acción, estado de ánimo e iluminación. Úsalo para mantener la continuidad narrativa al usar la ruta V2V de la siguiente toma; el texto resultante fluye haciaWanVideoTextEncodeCached. Familia del modelo: OpenBMB/MiniCPM-V.
Extras opcionales#
- Mantén las resoluciones de imagen, video y muestreador consistentes en los nodos conectados para evitar deformaciones de aspecto y parpadeo de identidad.
- Para extensiones más largas, aumenta la superposición de ventanas en el bucle de extensión V2V para suavizar las transiciones entre segmentos.
- Si la memoria GPU es ajustada, deja habilitados los nodos de VRAM reservada (
ReservedVRAMSetter(#312, #448)) y usa los bloques de configuraciones de compilación antes de muestrear. - Cuando los avatares parlantes se desincronizan, prioriza el habla limpia o separa las voces con MelBandRoFormer antes de crear embebidos
MultiTalk. - Las configuraciones finales de entrega, como la tasa de fotogramas, el formato de píxel y el CRF, se controlan en los nodos de salida
VHS_VideoCombine; iguala la tasa de fotogramas con tu fuente para ediciones sin costuras.
Este README cubre el gráfico completo de SkyReels V3 ComfyUI para que puedas elegir la ruta que se ajuste a tu proyecto, combinarlas cuando sea necesario y renderizar video listo para historias con consistencia y mínimo ensayo y error.
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos a @Benji’s AI Playground y SkyReels por el flujo de trabajo SkyReels V3 ComfyUI por sus contribuciones y mantenimiento. Para detalles autorizados, por favor consulta la documentación y repositorios originales vinculados a continuación.
Recursos#
- SkyReels/V3 ComfyUI Source
- Documentos / Notas de lanzamiento: SkyReels V3 ComfyUI Source from @Benji’s AI Playground
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.
