
⚠️ Nota importante: Esta implementación de ComfyUI MultiTalk actualmente solo soporta generación de UNA SOLA PERSONA. Las funciones de conversación multi-persona estarán disponibles próximamente.
1. ¿Qué es MultiTalk?#
MultiTalk es un framework revolucionario para la generación de videos conversacionales multi-persona basados en audio, desarrollado por MeiGen-AI. A diferencia de los métodos tradicionales de generación de cabezas hablantes que solo animan movimientos faciales, la tecnología MultiTalk puede generar videos realistas de personas hablando, cantando e interactuando mientras mantiene una sincronización labial perfecta con la entrada de audio. MultiTalk transforma fotos estáticas en videos hablantes dinámicos haciendo que la persona hable o cante exactamente lo que deseas.
2. Cómo funciona MultiTalk#
MultiTalk aprovecha tecnología avanzada de IA para comprender tanto señales de audio como información visual. La implementación de ComfyUI MultiTalk combina MultiTalk + Wan2.1 + Uni3C para resultados óptimos:
Análisis de audio: MultiTalk utiliza un potente codificador de audio (Wav2Vec) para comprender los matices del habla, incluyendo ritmo, tono y patrones de pronunciación.
Comprensión visual: Construido sobre el robusto modelo de difusión de video Wan2.1, MultiTalk comprende la anatomía humana, expresiones faciales y movimientos corporales (puedes visitar nuestro workflow Wan2.1 para generación t2v/i2v).
Control de cámara: MultiTalk con Uni3C controlnet permite movimientos sutiles de cámara y control de escena, haciendo el video más dinámico y profesional. Consulta nuestro workflow Uni3C para crear hermosas transferencias de movimiento de cámara.
Sincronización perfecta: A través de mecanismos de atención sofisticados, MultiTalk aprende a alinear perfectamente los movimientos labiales con el audio manteniendo expresiones faciales y lenguaje corporal naturales.
Seguimiento de instrucciones: A diferencia de métodos más simples, MultiTalk puede seguir prompts de texto para controlar la escena, pose y comportamiento general mientras mantiene la sincronización de audio.
3. Beneficios de ComfyUI MultiTalk#
- Sincronización labial de alta calidad: MultiTalk logra precisión de milisegundos en la sincronización labial, especialmente impresionante para escenarios de canto
- Creación de contenido versátil: MultiTalk soporta generación tanto de habla como de canto con varios tipos de personajes incluyendo personajes de dibujos animados
- Resolución flexible: MultiTalk genera videos en 480P o 720P con proporciones arbitrarias
- Soporte de videos largos: MultiTalk crea videos de hasta 15 segundos de duración
- Seguimiento de instrucciones: MultiTalk controla las acciones de personajes y configuraciones de escena a través de prompts de texto
4. Cómo usar el workflow ComfyUI MultiTalk#
Guía paso a paso de MultiTalk#
Paso 1: Preparar las entradas de MultiTalk
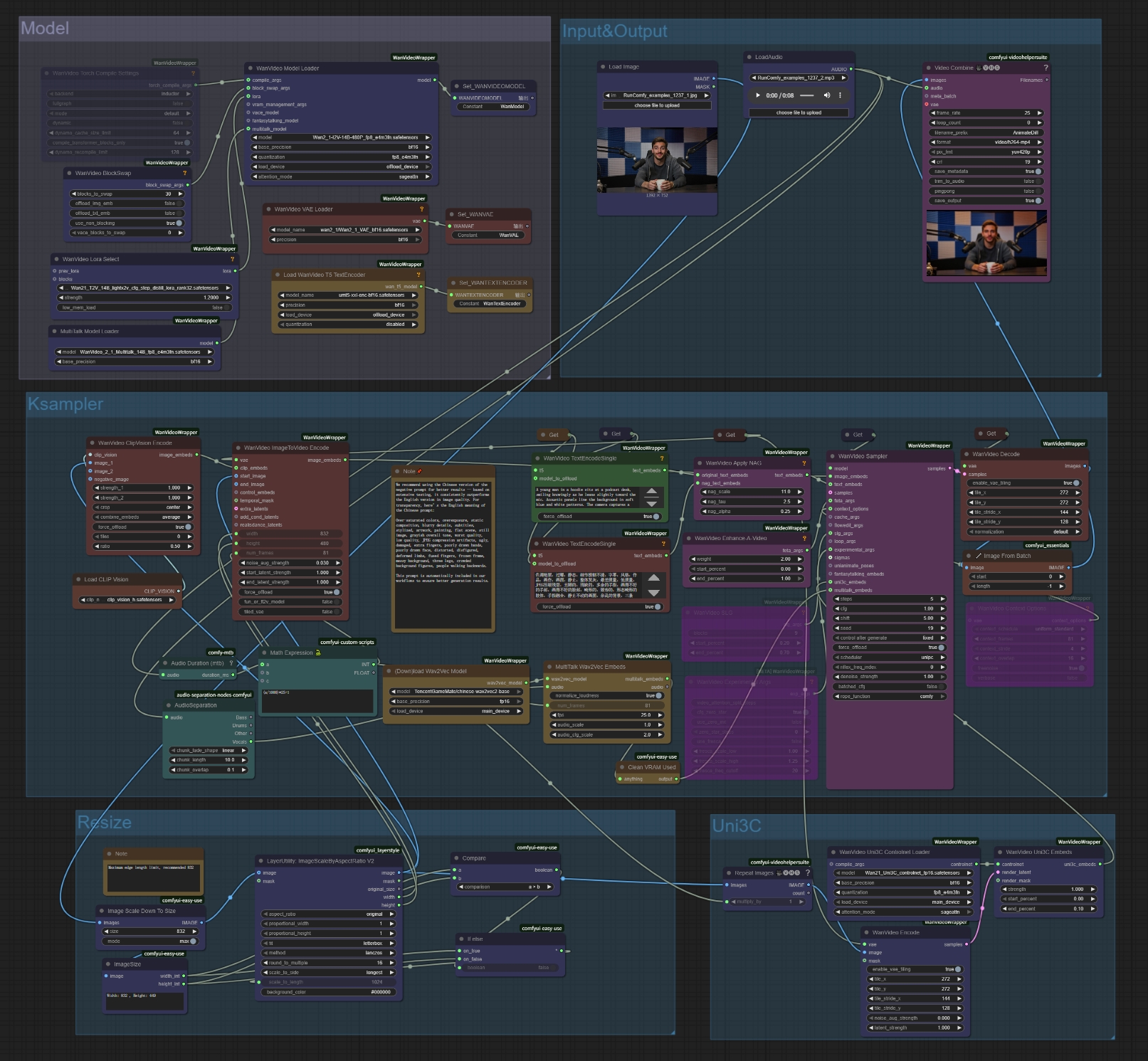
- Subir imagen de referencia: Haz clic en "choose file to upload" en el nodo Load Image
- Usa fotos nítidas y frontales para mejores resultados de MultiTalk
- La imagen se redimensionará automáticamente a dimensiones óptimas (832px recomendado)
- Subir archivo de audio: Haz clic en "choose file to upload" en el nodo LoadAudio
- MultiTalk soporta varios formatos de audio (WAV, MP3, etc.)
- Habla/canto nítido funciona mejor con MultiTalk
- Para crear canciones personalizadas, considera usar nuestro workflow de generación musical Ace-Step, que produce música de alta calidad con letras sincronizadas.
- Escribir prompt de texto: Describe la escena deseada en los nodos de codificación de texto para la generación MultiTalk
Paso 2: Configurar los ajustes de generación MultiTalk
- Pasos de muestreo: 20-40 pasos (mayor = mejor calidad MultiTalk, generación más lenta)
- Audio Scale: Mantener en 1.0 para sincronización labial MultiTalk óptima
- Embed Cond Scale: 2.0 para condicionamiento de audio MultiTalk equilibrado
- Control de cámara: Activar Uni3C para movimientos sutiles, o desactivar para tomas MultiTalk estáticas
Paso 3: Mejoras opcionales de MultiTalk
- Aceleración LoRA: Activar para generación MultiTalk más rápida con pérdida mínima de calidad
- Mejora de video: Usar nodos de mejora para mejoras de post-procesamiento MultiTalk
- Prompts negativos: Agregar elementos no deseados a evitar en la salida MultiTalk (borroso, distorsionado, etc.)
Paso 4: Generar con MultiTalk
- Poner el prompt en cola y esperar la generación MultiTalk
- Monitorear uso de VRAM (48GB recomendado para MultiTalk)
- Tiempo de generación MultiTalk: 7-15 minutos dependiendo de los ajustes y hardware
5. Agradecimientos#
Investigación original: MultiTalk es desarrollado por MeiGen-AI con la colaboración de investigadores líderes en el campo. El artículo original "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" presenta la investigación innovadora detrás de esta tecnología.
Integración ComfyUI: La implementación de ComfyUI es proporcionada por Kijai a través del repositorio ComfyUI-WanVideoWrapper, haciendo esta tecnología avanzada accesible a la comunidad creativa más amplia.
Tecnología base: Construido sobre el modelo de difusión de video Wan2.1 e incorpora técnicas de procesamiento de audio de Wav2Vec, representando una síntesis de investigación de IA de vanguardia.
6. Enlaces y recursos#
- Investigación original: MeiGen-AI MultiTalk Repository
- Página del proyecto: https://meigen-ai.github.io/multi-talk/
- Integración ComfyUI: ComfyUI-WanVideoWrapper