
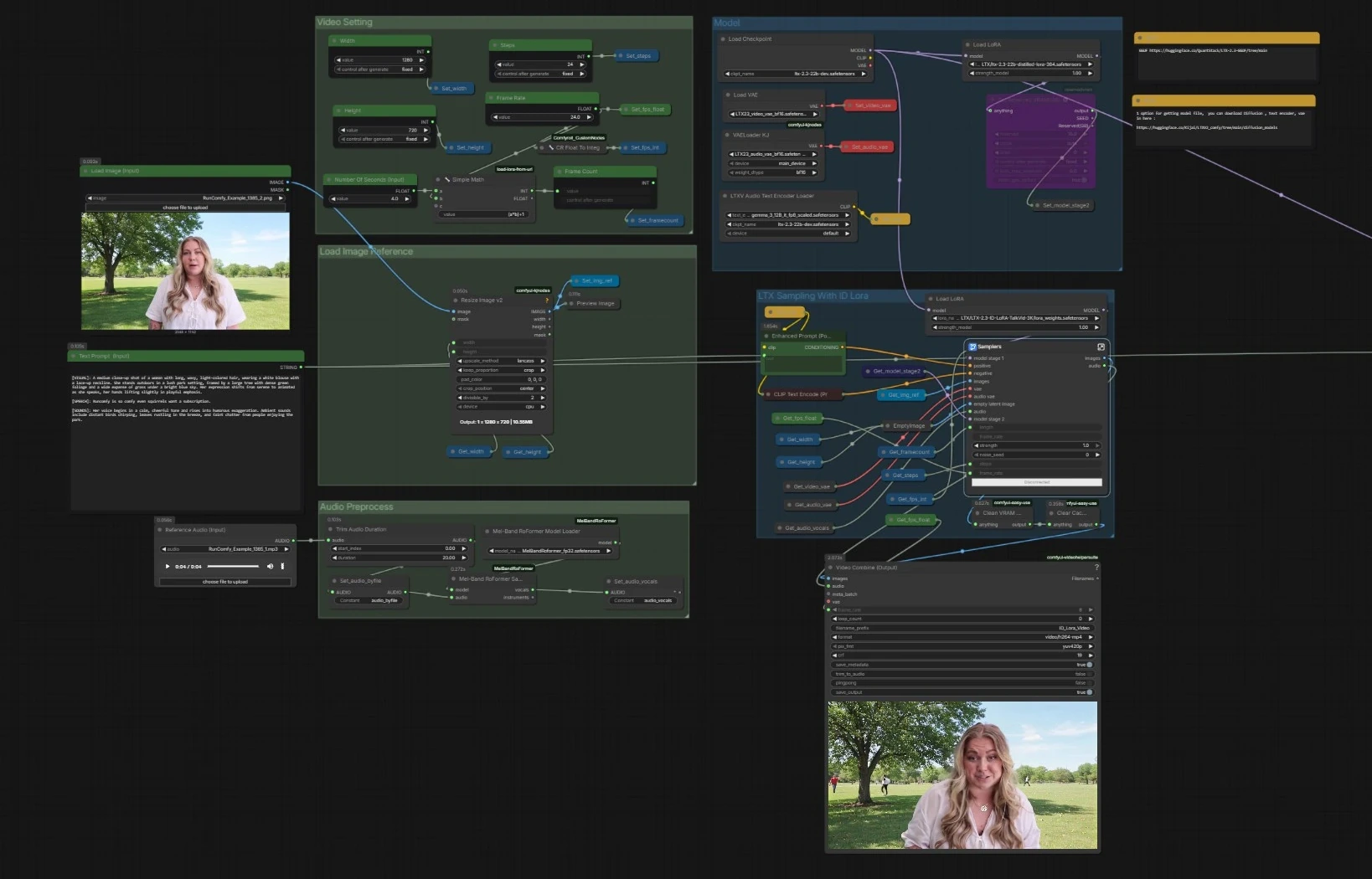
Flujo de trabajo de video parlante LTX 2.3 ID-LoRA para ComfyUI#
Este flujo de trabajo convierte una sola imagen facial, un breve clip de voz y un aviso en un video parlante totalmente sincronizado. Construido sobre LTX‑2.3, fusiona audio y visuales en un solo proceso de difusión y agrega un adaptador de identidad LoRA en contexto para que la persona en tu imagen de referencia se mantenga consistente en todos los fotogramas. LTX 2.3 ID-LoRA es ideal para avatares, anfitriones virtuales y cualquier escenario donde la sincronización labial, la semejanza y el control del aviso deben alinearse en una sola pasada.
Proporcionas tres cosas: una imagen de referencia, una o dos frases de audio y un aviso de texto que describe apariencia y rendimiento. La ruta LTX 2.3 ID-LoRA maneja la identidad mientras un preprocesador de audio ligero mejora la claridad de la voz para indicaciones de boca más fuertes. El resultado es un video coherente, que preserva la identidad, con habla sincronizada que no requiere entrenamiento por sujeto.
Modelos clave en el flujo de trabajo Comfyui LTX 2.3 ID-LoRA#
- Lightricks LTX‑2.3 22B base checkpoint. El modelo base de audio‑video conjunto que genera fotogramas y sonido sincronizados a partir de texto, imagen y condicionamiento de audio. Es el generador principal utilizado por esta pipeline de ComfyUI. Model card
- LTX‑2.3 distilled LoRA 384. Adaptador LoRA oficial que aplica orientación destilada al modelo base para estabilizar y acelerar el muestreo sin sacrificar calidad. Está conectado como el modelo de segunda etapa en este flujo de trabajo. Ver la tabla de checkpoints en la página LTX‑2.3. Model card
- LTX‑2.3 spatial upscaler x2. Ampliador espacial de espacio latente utilizado dentro del subgrafo del muestreador para elevar el detalle espacial antes de la decodificación, mejorando la fidelidad de rostros y bordes en el video final. Model card
- Gemma 3 12B Instruct text encoder for LTX‑2.3. Proporciona el condicionamiento de texto que impulsa el estilo, la escena y el rendimiento. Este flujo de trabajo utiliza el codificador Gemma 3 empaquetado para LTX‑2 en ComfyUI. Codificadores de texto Comfy‑Org
- LTX‑2.3 VAEs para video y audio. VAEs construidos específicamente decodifican latentes visuales y acústicos producidos por el modelo en imágenes y una forma de onda. Se hacen referencias a compilaciones compatibles bf16 en el gráfico. Fuentes de ejemplo: Video VAE · Audio VAE
- Mel‑Band RoFormer para separación vocal. Preprocesador opcional que extrae voces limpias del audio de referencia para que el modelo pueda rastrear sílabas y formas de boca de manera más confiable. Paper · Nodo ComfyUI
- LTX 2.3 ID‑LoRA (IC‑LoRA). Un LoRA de identidad en contexto entrenado para uso en video parlante que inclina el generador hacia el rostro en tu imagen de referencia mientras respeta las indicaciones y señales de voz. Lightricks documenta el uso de LoRA y IC‑LoRA con LTX‑2.3 en la página del modelo. Model card
Cómo usar el flujo de trabajo Comfyui LTX 2.3 ID-LoRA#
Flujo general. La pipeline carga la base LTX‑2.3 con codificadores de texto y VAEs, prepara tu imagen y audio, luego ejecuta un muestreador LTX de dos etapas que combina texto, la referencia facial y una pista vocal para generar fotogramas y habla sincronizados. Se incluye un muestreador paralelo sin ID‑LoRA para comparaciones rápidas. Los fotogramas finales y el audio se combinan en un MP4.
- Modelo
- El gráfico carga el checkpoint base con
CheckpointLoaderSimple(#5493), los codificadores de texto basados en Gemma a través deLTXAVTextEncoderLoader(#5494), y los VAEs dedicados para videoVAELoader(#5651) y audioVAELoaderKJ(#5649). Luego aplica dos adaptadores: el LoRA destilado oficial para formar un modelo de etapa 2 y el LTX 2.3 ID-LoRA para el condicionamiento de identidad a través deLoraLoaderModelOnly(#5573). - Esta etapa asegura que el generador entienda tu aviso, tenga las pilas de decodificación correctas y esté preparado con orientación de eficiencia y sesgo de identidad.
- Generalmente no modificas nada aquí más allá de cambiar checkpoints o LoRAs si tienes alternativas.
- El gráfico carga el checkpoint base con
- Configuración de Video
- Controla dimensiones de salida, tasa de fotogramas, pasos y duración.
Width(#5284),Height(#5286), yFrame Rate(#5289) alimentan una pequeña utilidad que calcula el total de fotogramas a partir de segundos, manteniendo la sincronización consistente entre audio y video. - Las configuraciones se almacenan una vez y son leídas por todos los nodos posteriores para que los dos muestreadores y el combinador se mantengan alineados.
- Ajusta estos valores primero cuando quieras un aspecto, suavidad o duración diferentes.
- Controla dimensiones de salida, tasa de fotogramas, pasos y duración.
- Cargar Referencia de Imagen
- Proporciona una imagen facial clara a través de
Load Image (Input)(#5525). La imagen se redimensiona conImageResizeKJv2(#5280) para coincidir con tu salida elegida. - Esta imagen preprocesada se convierte en el ancla para la identidad en la etapa LTX 2.3 ID-LoRA, guiando la semejanza y la composición de la toma.
- Usa una foto bien iluminada, frontal, con mínimo desenfoque de movimiento para obtener los mejores resultados.
- Proporciona una imagen facial clara a través de
- Preprocesamiento de Audio
- Coloca un breve WAV o MP3 usando
Reference Audio (Input)(#5652). El clip se recorta si es necesario y luego se pasa aMelBandRoFormerSampler(#5473) para aislar las vocales. - Las vocales limpias ayudan al modelo a inferir fonemas y temporización para movimientos labiales precisos y ritmo de habla.
- Si tu audio ya es solo de voz, puedes omitir la separación y alimentarlo directamente.
- Coloca un breve WAV o MP3 usando
- Muestreo LTX con ID Lora
- Este es el camino principal. El subgrafo del muestreador (
Samplers(#5278)) mezcla tu aviso positivo deEnhanced Prompt (Positive)(#5174), la lista negativa, la referencia facial, y la pista vocal a través de la tubería latente AV de LTX‑2.3. LTXVReferenceAudioalinea el movimiento con el discurso mientrasLTXVImgToVideoInplaceinyecta la imagen facial en el latente como un ancla. El adaptador LTX 2.3 ID-LoRA dirige el generador hacia la identidad de tu sujeto.- La etapa incluye un ampliador latente interno para elevar el detalle antes de la decodificación. Produce fotogramas más una secuencia de audio sincronizada.
- Este es el camino principal. El subgrafo del muestreador (
- Muestreo LTX sin ID Lora
- Un muestreador reflejado (
Samplers(#5643)) ejecuta el mismo condicionamiento pero sin el adaptador ID‑LoRA. Úsalo para comprobaciones A/B o cuando quieras más libertad alejándote de la identidad de referencia. - Todo lo demás permanece idéntico, por lo que las diferencias que notes se deben únicamente al condicionamiento de identidad.
- Este camino puede ser útil para borradores rápidos o desviaciones creativas.
- Un muestreador reflejado (
- Combinación de Video y Salida
- Los fotogramas y el audio generado se combinan en MP4 con
Video Combine (Output)(#5218). La tasa de fotogramas proviene de tu configuración global, por lo que el movimiento y la sincronización labial coinciden con la temporización del muestreador. - El
Video Combine(#5645) secundario previsualiza la rama sin ID‑LoRA si la habilitaste, lo cual es útil para comparaciones. - El flujo de trabajo limpia la caché entre ejecuciones para mantener estable la VRAM en sesiones largas.
- Los fotogramas y el audio generado se combinan en MP4 con
Nodos clave en el flujo de trabajo Comfyui LTX 2.3 ID-LoRA#
LoraLoaderModelOnly(#5573)- Carga el LTX 2.3 ID-LoRA que preserva la identidad facial. Reduce su peso si deseas más variación creativa o aumentalo para fijar más firmemente la semejanza. Combínalo cuidadosamente con la fuerza del aviso para que identidad y estilo no compitan. Referencia: Uso de LoRA LTX‑2.3 en la página del modelo. Model card
LTXVReferenceAudio(#5589)- Convierte tu audio de referencia en condicionamiento para la temporización de sílabas, prosodia y formas de boca. Alimenta discurso claro para la mejor alineación. Si escuchas bombeo o articulación desfasada, acorta o simplifica el clip en lugar de aumentar la fuerza.
LTXVImgToVideoInplace(#5245, también usado más tarde)- Inyecta la imagen facial en la secuencia de video latente como un prior espacial. El control de fuerza de imagen equilibra la adherencia a la foto versus la libertad de movimiento. Para una identidad fuerte con movimiento natural, mantén la fuerza de imagen moderada y deja que el ID‑LoRA lleve la semejanza.
LTXVConditioning(#5621)- Empaqueta el condicionamiento de texto y las señales de temporización para los muestreadores LTX. Asegúrate de que su entrada de tasa de fotogramas coincida con tu tasa de fotogramas de salida para que los campos de movimiento y la temporización de fonemas se mantengan coherentes.
VHS_VideoCombine(#5218)- Mezcla los fotogramas y el audio en el archivo final. Si tu audio es ligeramente más largo que los fotogramas, habilita el recorte aquí para evitar una cola negra al final. Para compatibilidad con plataformas, mantén la configuración H.264 predeterminada a menos que tengas una razón para cambiarlas. Referencia de nodo: ComfyUI‑VideoHelperSuite
MelBandRoFormerSampler(#5473)- Separa las vocales de la música usando un transformador de banda Mel para que el generador se fije en el discurso. Si las sibilantes se emborronan o las plosivas explotan, prueba con un archivo de modelo diferente de la misma familia o reduce la intensidad de entrada. Lectura de fondo: arXiv
Extras opcionales#
- Para generaciones más estables con LTX‑2.3, usa ancho y alto divisibles por 32 y elige una cuenta de fotogramas de 8n + 1 como documentado por Lightricks. Model card
- Mantén la imagen de referencia consistente con tu aviso. Si describes iluminación exterior pero proporcionas una foto interior, la identidad puede mantenerse mientras el color y el sombreado luchan contra el aviso.
- Dale al audio de 2 a 8 segundos con un ritmo natural. Los clips sobrecomprimidos o reverberantes reducen la fidelidad de sincronización labial incluso después de la separación vocal.
- Cuando los rostros se desvían, reduce ligeramente la fuerza de la imagen y confía más en el LTX 2.3 ID-LoRA. Cuando los rostros vagan demasiado, haz lo contrario.
- Para tomas más largas, genera en segmentos que compartan la misma semilla y configuraciones globales, luego une los clips en edición de video si es necesario.
Referencias y repositorios útiles#
- Pesos abiertos y notas LTX‑2.3: Página del modelo Hugging Face
- Nodos ComfyUI oficiales para LTX Video: Lightricks/ComfyUI‑LTXVideo
- Base de código y paper LTX‑2: Lightricks/LTX‑Video · arXiv
- Codificadores IT Gemma 3 12B para LTX en ComfyUI: Comfy‑Org/ltx‑2 text_encoders
- Antecedentes de Mel‑Band RoFormer: arXiv
Agradecimientos#
Este flujo de trabajo implementa y se basa en los siguientes trabajos y recursos. Agradecemos profundamente a los creadores de LTX 2.3 ID-LoRA Source para el flujo de trabajo LTX 2.3 ID-LoRA Source por sus contribuciones y mantenimiento. Para detalles autoritativos, por favor consulta la documentación original y los repositorios vinculados a continuación.
Recursos#
- LTX 2.3 ID-LoRA Source
- Docs / Notas de lanzamiento: YouTube @Benji’s AI Playground
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.