
LTX 2.3 LoRA ComfyUI Inferencia: salida de LoRA de AI Toolkit coincidente con el entrenamiento con el pipeline LTX 2.3#
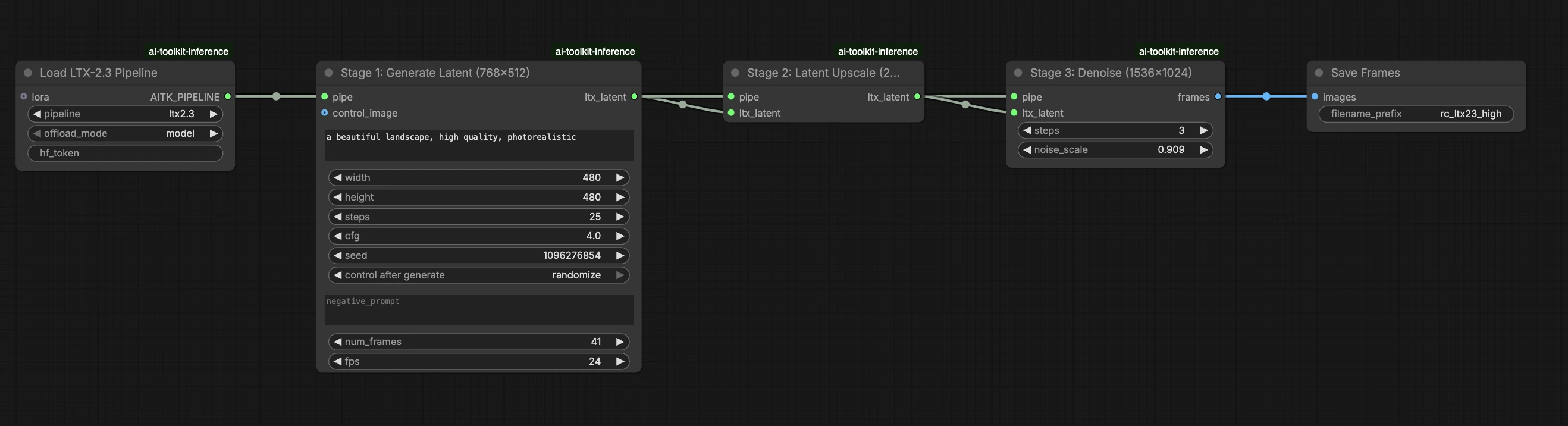
Este flujo de trabajo listo para producción RunComfy ejecuta la inferencia de LTX 2.3 LoRA en ComfyUI a través de RC LTX 2.3 (LTX2Pipeline) (alineación a nivel de pipeline, no un grafo muestreador genérico). RunComfy construyó y liberó este nodo personalizado—vea los repositorios runcomfy-com—y usted controla la aplicación del adaptador con lora_path y lora_scale.
Nota: Este flujo de trabajo requiere una máquina 2X Grande o más para ejecutarse.
Por qué LTX 2.3 LoRA ComfyUI Inferencia a menudo se ve diferente en ComfyUI#
Las previsualizaciones de entrenamiento de AI Toolkit se renderizan a través de un pipeline LTX 2.3 específico del modelo, donde la codificación de texto, la programación y la inyección de LoRA están diseñadas para trabajar juntas. En ComfyUI, reconstruir LTX 2.3 con un grafo diferente (o una ruta de cargador LoRA diferente) puede cambiar esas interacciones, por lo que copiar el mismo prompt, pasos, CFG y semilla aún produce una desviación visible. Los nodos de pipeline RC de RunComfy cierran esa brecha ejecutando LTX 2.3 de principio a fin en LTX2Pipeline y aplicando su LoRA dentro de ese pipeline, manteniendo la inferencia alineada con el comportamiento de previsualización. Fuente: Repositorios de código abierto de RunComfy.
Cómo usar el flujo de trabajo LTX 2.3 LoRA ComfyUI Inferencia#
Paso 1: Obtenga la ruta de LoRA y cárguela en el flujo de trabajo (2 opciones)#
Opción A — Resultado de entrenamiento RunComfy → descarga a ComfyUI local:
- Vaya a Trainer → LoRA Assets
- Encuentre el LoRA que desea usar
- Haga clic en el menú ⋮ (tres puntos) a la derecha → seleccione Copiar enlace de LoRA
- En la página de flujo de trabajo de ComfyUI, pegue el enlace copiado en el campo de entrada Descargar en la esquina superior derecha de la interfaz de usuario
- Antes de hacer clic en Descargar, asegúrese de que la carpeta de destino esté configurada en ComfyUI > models > loras (esta carpeta debe ser seleccionada como el destino de descarga)
- Haga clic en Descargar — esto asegura que el archivo LoRA se guarde en el directorio correcto
models/loras - Después de que la descarga termine, actualice la página
- El LoRA ahora aparece en el desplegable de selección de LoRA en el flujo de trabajo — selecciónelo
Opción B — URL directa de LoRA (anula la Opción A):
- Pegue el URL directo de descarga
.safetensorsen el campo de entradapath / urldel nodo LoRA - Cuando se proporciona un URL aquí, anula la Opción A — el flujo de trabajo carga el LoRA directamente desde el URL en tiempo de ejecución
- No se requiere descarga local o colocación de archivos
Consejo: confirme que el URL resuelve al archivo real .safetensors (no a una página de destino o redirección).
Paso 2: Igualar los parámetros de inferencia con la configuración de muestra de entrenamiento#
En el nodo LoRA, seleccione su adaptador en lora_path (Opción A), o pegue un enlace directo .safetensors en path / url (la Opción B anula el desplegable). Luego configure lora_scale a la misma fuerza que usó durante las previsualizaciones de entrenamiento y ajuste desde allí.
Los parámetros restantes están en el nodo Generate (y, dependiendo del grafo, el nodo Load Pipeline):
prompt: su prompt de texto (incluya palabras de activación si entrenó con ellas)width/height: resolución de salida; iguale el tamaño de su previsualización de entrenamiento para la comparación más limpia (se recomiendan múltiplos de 32 para LTX 2.3)num_frames: número de fotogramas de video de salidasample_steps: número de pasos de inferencia (30 es un valor predeterminado común)guidance_scale: valor de CFG/guía (5.5 es un valor predeterminado común; no exceda 7)seed: semilla fija para reproducir; cámbiela para explorar variacionesseed_mode(solo si está presente): elijafixedorandomizeframe_rate: FPS de salida; mantenga coherente con la configuración de entrenamiento para la alineación de movimiento
Consejo de alineación de entrenamiento: si personalizó los valores de muestreo durante el entrenamiento (seed, guidance_scale, sample_steps, palabras de activación, resolución), refleje esos valores exactos aquí. Si entrenó en RunComfy, abra Trainer → LoRA Assets > Config para ver el YAML resuelto y copiar la configuración de previsualización/muestra en los nodos del flujo de trabajo.
Paso 3: Ejecute LTX 2.3 LoRA ComfyUI Inferencia#
Haga clic en Queue/Run — el nodo SaveVideo escribe los resultados en su carpeta de salida de ComfyUI.
Lista de verificación rápida:
- ✓ LoRA está: descargado en
ComfyUI/models/loras(Opción A), o cargado a través de un URL directo.safetensors(Opción B) - ✓ Página actualizada después de la descarga local (solo Opción A)
- ✓ Los parámetros de inferencia coinciden con la configuración de
samplede entrenamiento (si se personalizó)
Si todo lo anterior es correcto, los resultados de inferencia aquí deberían coincidir estrechamente con sus previsualizaciones de entrenamiento.
Solución de problemas de LTX 2.3 LoRA ComfyUI Inferencia#
La mayoría de las brechas de "previsualización de entrenamiento vs inferencia de ComfyUI" de LTX 2.3 provienen de diferencias a nivel de pipeline (cómo se carga el modelo, se programa y cómo se fusiona el LoRA), no de un solo control incorrecto. Este flujo de trabajo de RunComfy restaura la línea base más cercana "coincidente con el entrenamiento" ejecutando la inferencia a través de RC LTX 2.3 (LTX2Pipeline) de principio a fin y aplicando su LoRA dentro de ese pipeline a través de lora_path / lora_scale (en lugar de apilar nodos de cargador/muestreador genéricos).
(1) Desajustes de forma de LoRA o advertencias de "clave no cargada"#
Por qué sucede esto El LoRA fue entrenado para una familia de modelos diferente o una variante diferente de LTX. Verá muchas líneas de lora key not loaded y potencialmente errores de desajuste de forma.
Cómo solucionarlo (recomendado)
- Asegúrese de que el LoRA fue entrenado específicamente para LTX 2.3 con AI Toolkit (Los LoRAs de LTX 2.0 / 2.1 / 2.2 no son intercambiables).
- Mantenga el grafo "de un solo camino" para LoRA: cargue el adaptador solo a través de la entrada
lora_pathdel flujo de trabajo y deje que LTX2Pipeline maneje la fusión. No apile un cargador de LoRA genérico adicional en paralelo. - Si ya encontró un desajuste y ComfyUI comienza a producir errores CUDA/OOM no relacionados después, reinicie el proceso de ComfyUI para restablecer completamente el estado de la GPU + modelo, luego intente de nuevo con un LoRA compatible.
(2) Los resultados de inferencia no coinciden con las previsualizaciones de entrenamiento#
Por qué sucede esto Incluso cuando el LoRA se carga, los resultados aún pueden desviarse si su grafo de ComfyUI no coincide con el pipeline de previsualización de entrenamiento (diferentes valores predeterminados, diferente ruta de inyección de LoRA, diferente programación).
Cómo solucionarlo (recomendado)
- Use este flujo de trabajo y pegue su enlace directo
.safetensorsenlora_path. - Copie los valores de muestreo de su configuración de entrenamiento de AI Toolkit (o RunComfy Trainer → LoRA Assets Config):
width,height,num_frames,sample_steps,guidance_scale,seed,frame_rate. - Mantenga "pilas de velocidad extra" fuera de la comparación a menos que haya entrenado/muestreado con ellas.
(3) Usar LoRAs aumenta significativamente el tiempo de inferencia#
Por qué sucede esto Un LoRA puede hacer que LTX 2.3 sea mucho más lento cuando la ruta de LoRA obliga a un trabajo extra de parcheo/descuantización o aplica pesos en una ruta de código más lenta que el modelo base solo.
Cómo solucionarlo (recomendado)
- Use la ruta RC LTX 2.3 (LTX2Pipeline) de este flujo de trabajo y pase su adaptador a través de
lora_path/lora_scale. En esta configuración, el LoRA se fusiona una vez durante la carga del pipeline (estilo AI Toolkit), por lo que el costo de muestreo por paso se mantiene cerca del modelo base. - Cuando esté persiguiendo un comportamiento coincidente con la previsualización, evite apilar múltiples cargadores de LoRA o mezclar rutas de cargador. Manténgalo en un
lora_path+ unlora_scalehasta que la línea base coincida.
(4) Errores OOM en grandes resoluciones o videos largos#
Por qué sucede esto LTX 2.3 es un modelo de 22B parámetros y la generación de video es intensiva en VRAM. Altas resoluciones o muchos fotogramas pueden exceder la memoria de la GPU, especialmente con la sobrecarga de LoRA.
Cómo solucionarlo (recomendado)
- Use una máquina 2X Grande (80 GB VRAM) o más grande. Este flujo de trabajo no es compatible con máquinas Medianas, Grandes, o X Grandes.
- Reduzca la resolución o el conteo de fotogramas si necesita iterar rápidamente, luego escale para los renders finales.
- Habilite el mosaico VAE si está disponible — puede ahorrar ~3 GB VRAM con una pérdida mínima de calidad.
Ejecute LTX 2.3 LoRA ComfyUI Inferencia ahora#
Abra el flujo de trabajo, configure lora_path, y haga clic en Queue/Run para obtener resultados de LTX 2.3 LoRA que se mantengan cerca de sus previsualizaciones de entrenamiento de AI Toolkit.