
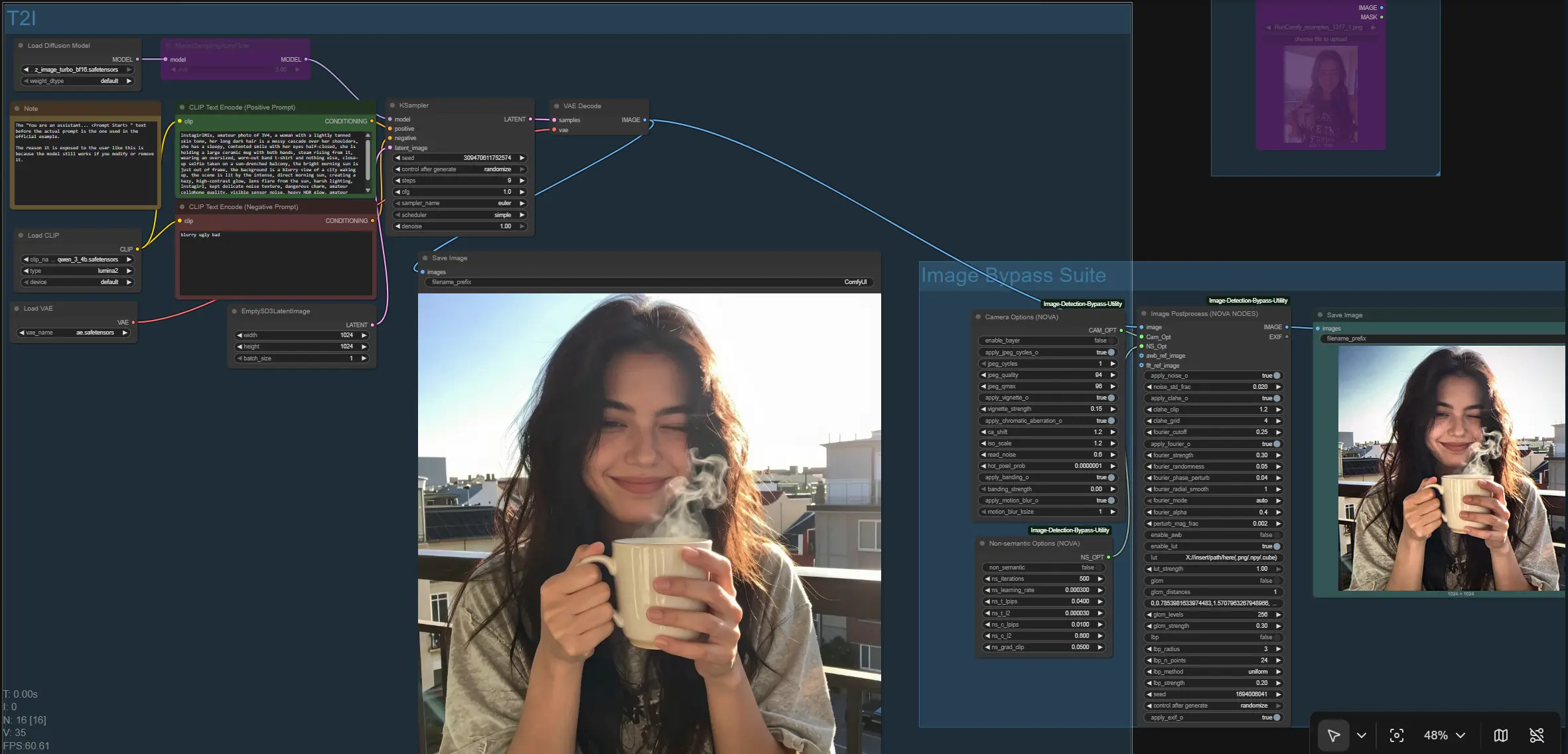







Flujo de Trabajo Bypass de Imagen ComfyUI#
Este flujo de trabajo ofrece una tubería modular de Bypass de Imagen para ComfyUI que combina normalización no semántica, controles en el dominio FFT y simulación de tubería de cámara. Está diseñado para creadores e investigadores que necesitan una forma confiable de procesar imágenes a través de una etapa de Bypass de Imagen manteniendo el control total sobre el enrutamiento de entradas, el comportamiento de preprocesamiento y la consistencia de salidas.
En su núcleo, el gráfico genera o ingiere una imagen, luego la dirige a través de un Conjunto de Bypass de Imagen que puede aplicar artefactos similares a sensores, modelado de frecuencias, coincidencia de texturas y un optimizador perceptual. El resultado es un camino limpio y configurable que se adapta al trabajo por lotes, la automatización y la iteración rápida en GPUs de consumo. La lógica de Bypass de Imagen está impulsada por la utilidad de código abierto de este repositorio: PurinNyova/Image-Detection-Bypass-Utility.
Modelos clave en el flujo de trabajo Bypass de Imagen Comfyui#
- z_image_turbo_bf16 (punto de control UNet). Un núcleo de difusión de texto a imagen rápido utilizado en la rama T2I para prototipado rápido y generación de imágenes base. Se puede reemplazar con tu punto de control preferido. Referencia: Comfy-Org/z_image_turbo en Hugging Face.
- VAE (ae.safetensors). Maneja la decodificación latente de vuelta a píxeles para que la salida del muestreo pueda visualizarse y procesarse más por la etapa de Bypass de Imagen. Cualquier VAE compatible puede intercambiarse si prefieres un perfil de reconstrucción diferente.
- Codificador de Prompts (cargado a través de CLIPLoader). Codifica tus prompts positivos y negativos en vectores de acondicionamiento para el muestreador. El gráfico es agnóstico al archivo de codificador de texto específico que cargas, por lo que puedes sustituir modelos según sea necesario para tu generador base.
Cómo usar el flujo de trabajo Bypass de Imagen Comfyui#
A un alto nivel, el flujo de trabajo ofrece dos formas de producir la imagen que entra en el Conjunto de Bypass de Imagen: una rama de Texto a Imagen (T2I) y una rama de Imagen a Imagen (I2I). Ambas convergen en un solo nodo de procesamiento que aplica la lógica de Bypass de Imagen y escribe el resultado final en el disco. El gráfico también guarda la línea base previa al bypass para que puedas comparar salidas.
Grupo: T2I#
Usa esta ruta cuando quieras sintetizar una imagen nueva a partir de prompts. Tu codificador de prompts se carga con CLIPLoader (#164) y es leído por CLIP Text Encode (Positive Prompt) (#168) y CLIP Text Encode (Negative Prompt) (#163). El UNet se carga con UNETLoader (#165), opcionalmente parcheado por ModelSamplingAuraFlow (#166) para ajustar el comportamiento de muestreo del modelo, y luego muestreado con KSampler (#167) comenzando desde EmptySD3LatentImage (#162). La imagen decodificada sale de VAEDecode (#158) y se guarda como línea base a través de SaveImage (#159) antes de entrar en el Conjunto de Bypass de Imagen. Para esta rama, tus entradas principales son los prompts positivos/negativos y, si se desea, la estrategia de semillas en KSampler (#167).
Grupo: I2I#
Elige esta ruta cuando ya tengas una imagen para procesar. Cárgala vía LoadImage (#157) y dirige la salida IMAGE a la entrada del Conjunto de Bypass de Imagen en NovaNodes (#146). Esto evita por completo el acondicionamiento de texto y el muestreo. Es ideal para el postprocesamiento por lotes, experimentos en conjuntos de datos existentes o la estandarización de salidas de otros flujos de trabajo. Puedes cambiar libremente entre T2I y I2I dependiendo de si quieres generar o simplemente transformar.
Grupo: Conjunto de Bypass de Imagen#
Este es el corazón del gráfico. El procesador central NovaNodes (#146) recibe la imagen entrante y dos bloques de opción: CameraOptionsNode (#145) y NSOptionsNode (#144). El nodo puede operar en un modo automático simplificado o un modo manual que expone controles para modelado de frecuencias (suavizado/coincidencia FFT), perturbaciones de píxeles y fase, manejo de contraste local y tono, LUTs 3D opcionales y ajuste de estadísticas de textura. Dos entradas opcionales te permiten conectar una referencia de balance de blancos automático y una imagen de referencia FFT/texture para guiar la normalización. El resultado final del Bypass de Imagen es escrito por SaveImage (#147), dándote tanto la línea base como la salida procesada para evaluación lado a lado.
Nodos clave en el flujo de trabajo Bypass de Imagen Comfyui#
NovaNodes (#146)#
El procesador central de Bypass de Imagen. Orquesta el modelado en el dominio de frecuencias, las perturbaciones espaciales, el control de tono local, la aplicación de LUT y la normalización de textura opcional. Si proporcionas una awb_ref_image o fft_ref_image, usará esas referencias temprano en la tubería para guiar la coincidencia de color y espectro. Comienza en modo automático para obtener una línea base razonable, luego cambia a manual para ajustar la fuerza del efecto y mezclar para tu contenido y tareas posteriores. Para comparaciones consistentes, establece y reutiliza una semilla; para exploración, aleatoriza para diversificar micro-variaciones.
NSOptionsNode (#144)#
Controla el optimizador no semántico que empuja los píxeles mientras preserva la similitud perceptual. Expone el conteo de iteración, la tasa de aprendizaje y los pesos de percepción/regularización (LPIPS y L2) junto con el recorte de gradiente. Úsalo cuando necesites cambios sutiles en la distribución con artefactos visibles mínimos; mantén los cambios conservadores para preservar texturas y bordes naturales. Desactívalo por completo para medir cuánto ayuda la tubería de Bypass de Imagen sin un optimizador.
CameraOptionsNode (#145)#
Simula características de sensor y lente como ciclos de demosaico y JPEG, viñeteado, aberración cromática, desenfoque de movimiento, bandas y ruido de lectura. Trátalo como una capa de realismo que puede agregar artefactos de adquisición plausibles a tus imágenes. Habilita solo los componentes que coincidan con tus condiciones de captura objetivo; apilar demasiados puede sobreconstrainar el aspecto. Para salidas reproducibles, mantén las mismas opciones de cámara mientras varías otros parámetros.
ModelSamplingAuraFlow (#166)#
Parchea el comportamiento de muestreo del modelo cargado antes de que alcance KSampler (#167). Esto es útil cuando tu núcleo elegido se beneficia de una trayectoria de pasos alternativos. Ajusta cuando notes una discrepancia entre la intención del prompt y la estructura de la muestra, y trátalo en conjunto con tus elecciones de muestreador y planificador.
KSampler (#167)#
Ejecuta el muestreo de difusión dado el modelo, el acondicionamiento positivo y negativo, y el latente inicial. Las palancas clave son la estrategia de semillas, pasos, tipo de muestreador y fuerza de desruido global. Los pasos más bajos ayudan a la velocidad, mientras que los pasos más altos pueden estabilizar la estructura si tu modelo base lo requiere. Mantén el comportamiento de este nodo estable mientras iteras en la configuración de Bypass de Imagen para que puedas atribuir cambios al postprocesamiento en lugar del generador.
Extras opcionales#
- Cambia modelos libremente. El Conjunto de Bypass de Imagen es agnóstico al modelo; puedes reemplazar
z_image_turbo_bf16y aún dirigir resultados a través de la misma pila de procesamiento. - Usa referencias con cuidado. Proporciona
awb_ref_imageyfft_ref_imageque compartan características de iluminación y contenido con tu dominio objetivo; referencias desajustadas pueden reducir el realismo. - Compara de manera justa. Mantén
SaveImage(#159) como la línea base ySaveImage(#147) como la salida de Bypass de Imagen para que puedas probar configuraciones A/B y rastrear mejoras. - Lotea con cuidado. Aumenta el tamaño del lote de
EmptySD3LatentImage(#162) solo según lo permita la VRAM, y prefiere semillas fijas al medir pequeños cambios de parámetros. - Aprende la utilidad. Para detalles de funciones y actualizaciones continuas de los componentes de Bypass de Imagen, consulta el proyecto en curso: PurinNyova/Image-Detection-Bypass-Utility.
Créditos#
- ComfyUI, el motor gráfico utilizado por este flujo de trabajo: comfyanonymous/ComfyUI.
- Ejemplo de punto de control base: Comfy-Org/z_image_turbo.
Reconocimientos#
Este flujo de trabajo implementa y se construye sobre los siguientes trabajos y recursos. Agradecemos a PurinNyova por Image-Detection-Bypass-Utility por sus contribuciones y mantenimiento. Para detalles autorizados, consulta la documentación original y los repositorios vinculados a continuación.
Recursos#
- PurinNyova/Image-Detection-Bypass-Utility
- GitHub: PurinNyova/Image-Detection-Bypass-Utility
- Documentación / Notas de Lanzamiento: Repositorio (tree/main)
Nota: El uso de los modelos, conjuntos de datos y código referenciados está sujeto a las respectivas licencias y términos proporcionados por sus autores y mantenedores.

