
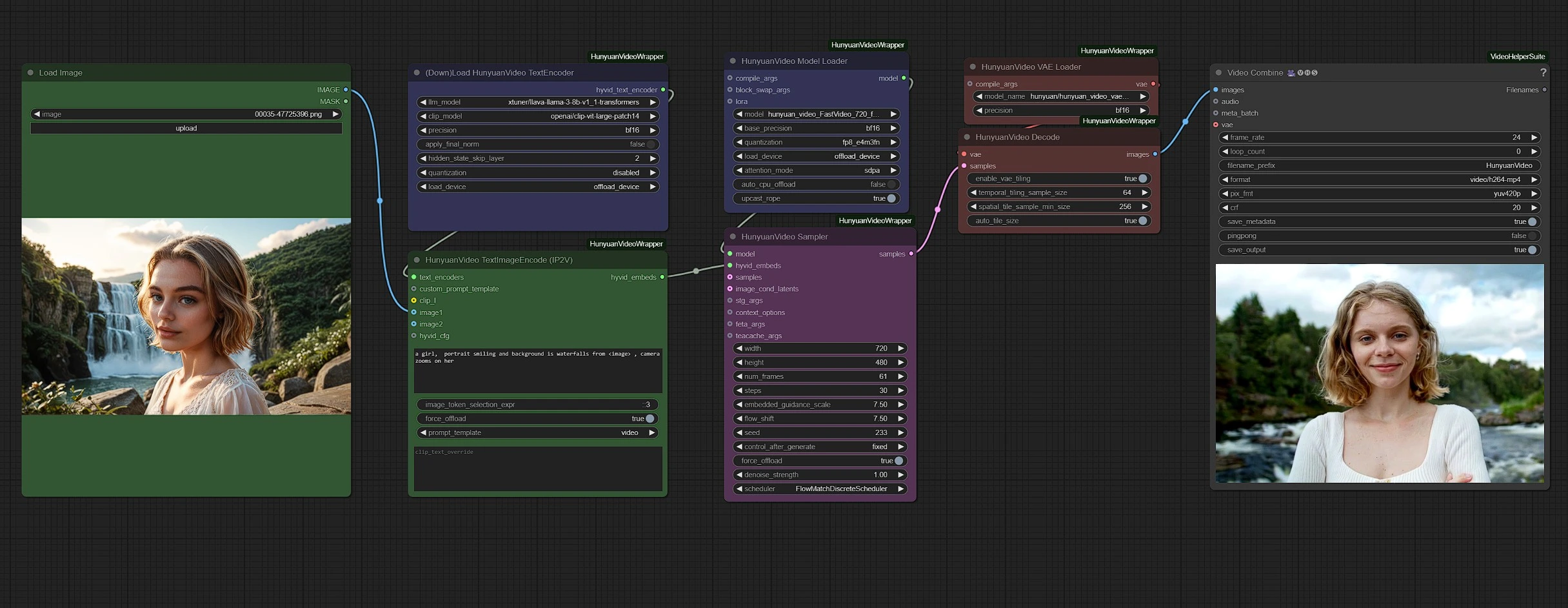
Hunyuan Video es un modelo de código abierto que desafía el dominio de los sistemas de código cerrado al ofrecer capacidades de generación de texto a video de vanguardia. Basado en innovaciones en la curación de datos a gran escala, diseño arquitectónico adaptativo e infraestructura optimizada, Hunyuan Video establece nuevos estándares en calidad visual.
Aunque Hunyuan Video se centra principalmente en la generación de texto a video, el flujo de trabajo Hunyuan IP2V extiende esta capacidad convirtiendo imagen y aviso de texto en video dinámico a través del mismo modelo. Este enfoque permite a los usuarios dirigir la creación de contenido utilizando referencias visuales, ofreciendo un método alternativo para la producción de contenido impulsado por IA.
Al combinar una imagen con un aviso, Hunyuan IP2V genera movimiento mientras preserva las características clave de la entrada, convirtiéndolo en una herramienta útil para la animación por IA, la visualización de conceptos y la narración artística. Ya sea creando escenas dinámicas, movimientos estilizados o extendiendo visuales estáticos en secuencias animadas, el marco de Hunyuan Video ofrece rutas eficientes para obtener resultados de alta calidad.
¿Cómo usar el flujo de trabajo Hunyuan Video - IP2V?#
Los grupos están codificados por colores para mayor claridad:
- Verde - Entradas
- Morado - Modelos
- Rosa - Muestreador Hunyuan
- Rojo - VAE + Decodificación
- Gris - Salida
Sube tus entradas (imagen y texto) en los nodos verdes y ajusta la configuración del video, como duración y resolución, en el nodo de muestreador rosa.
Entrada 1 - Imagen#
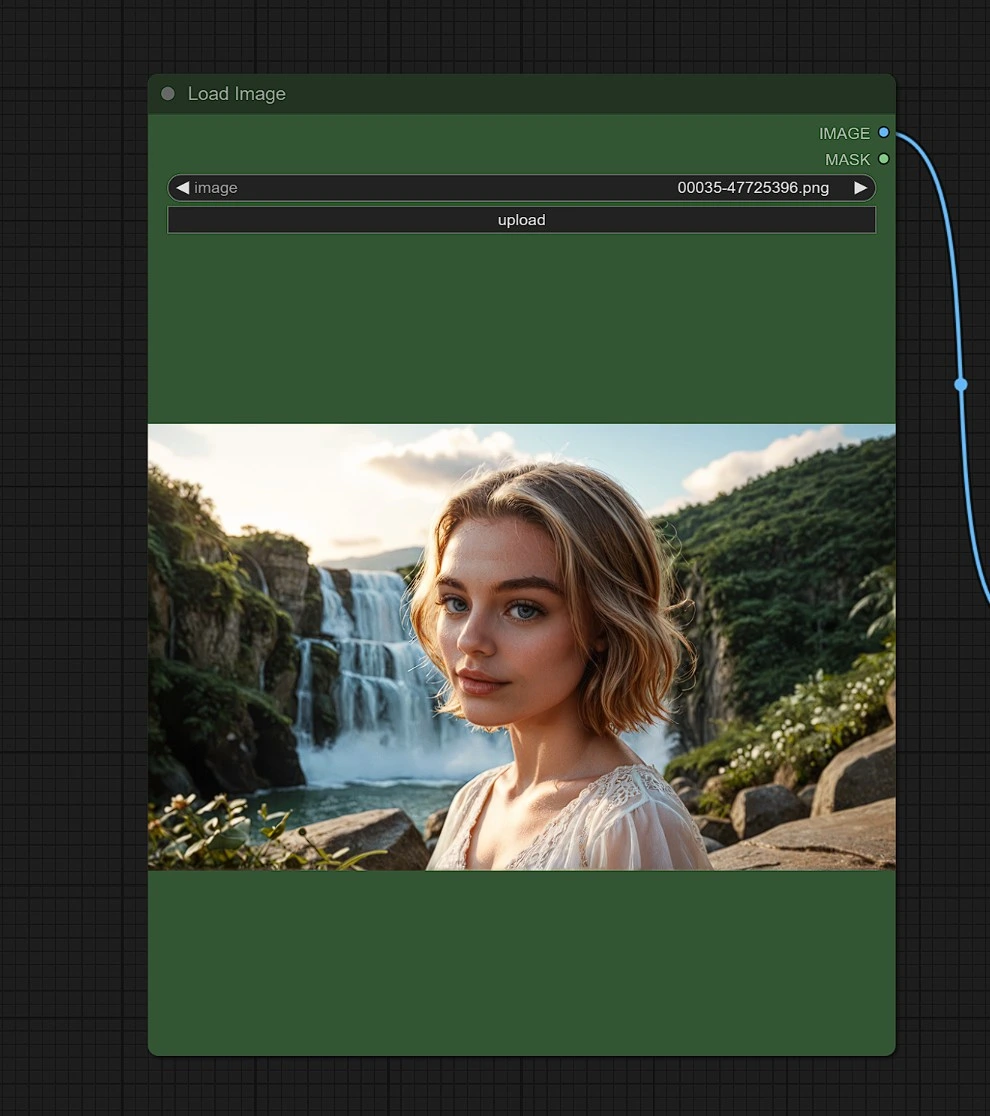
Sube una imagen como referencia del lugar, persona u objeto para el que buscas resultados similares.
Entrada 2 - Texto#
En el primer cuadro de texto, ingresa tus avisos e incluye la imagen utilizando la palabra clave "<image>".
Por ejemplo, si tu entrada es "calle vacía" y quieres añadir una mujer, el aviso sería: "Un retrato de una mujer, el fondo es <image>."
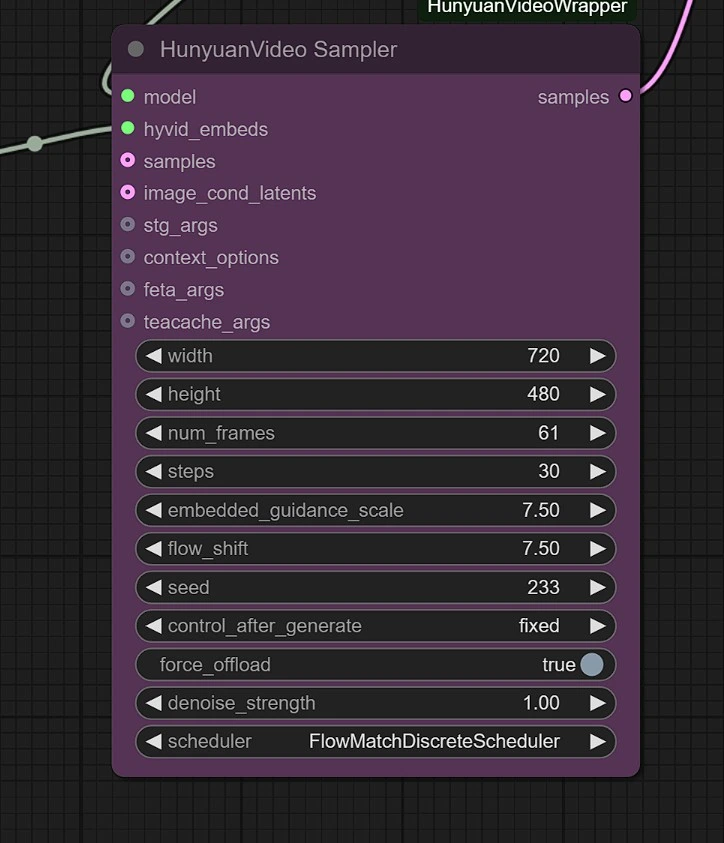
Muestreador#
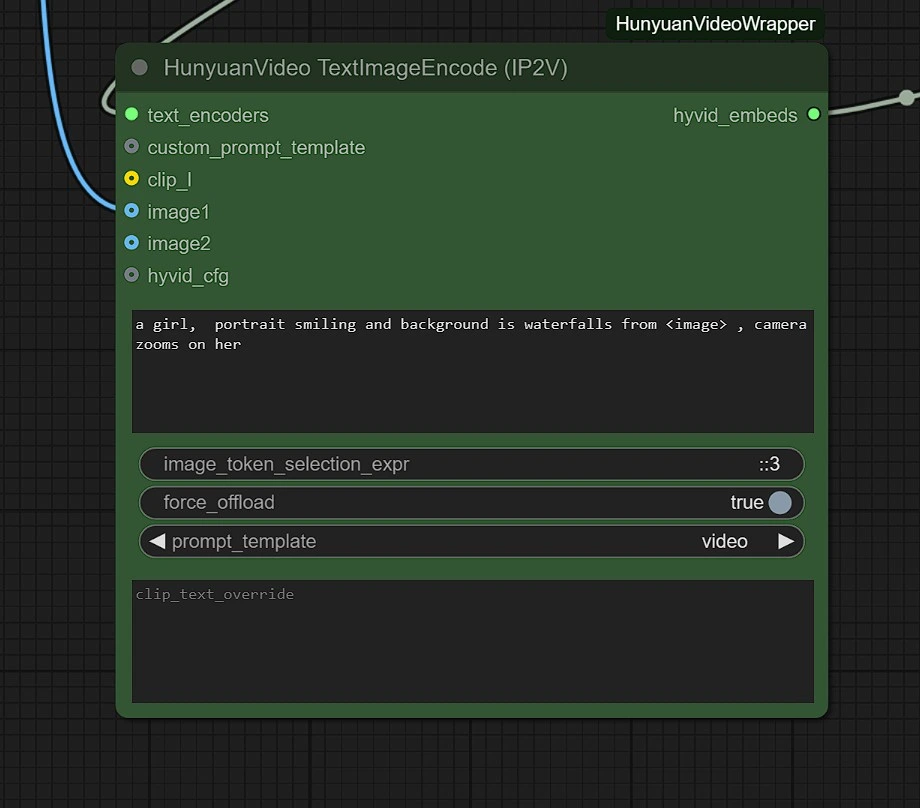
Puedes ajustar lo siguiente:
- Resolución de Imagen - Máximo es 1280px 720px, requiriendo más VRAM.
- Fotogramas - Esto establece el número de fotogramas (24 fotogramas = 1 segundo).
Modelos#
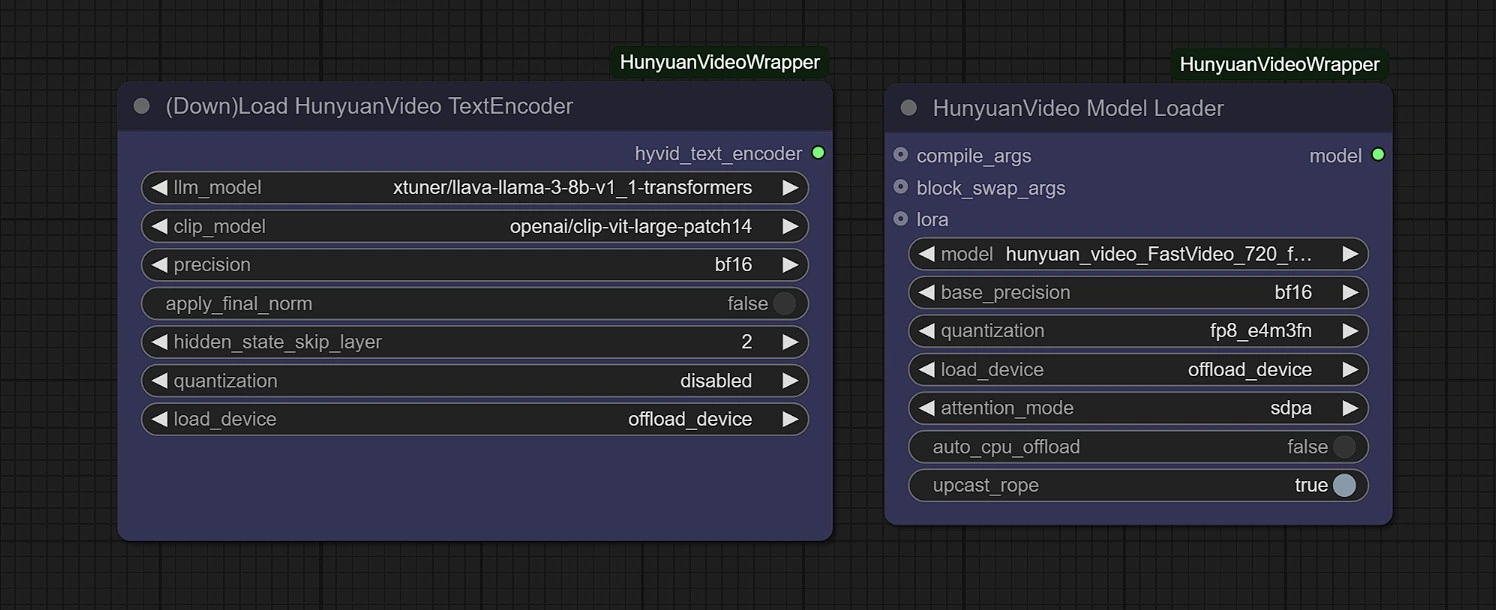
En este grupo, los modelos se descargarán automáticamente en la primera ejecución. Por favor, permita de 3 a 5 minutos para que la descarga se complete en su almacenamiento temporal.
Enlaces:
- Diffusion: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
- ComfyUI > models > diffusion_models
- Vae: https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_vae_bf16.safetensors
- ComfyUI > models > vae
Salidas#
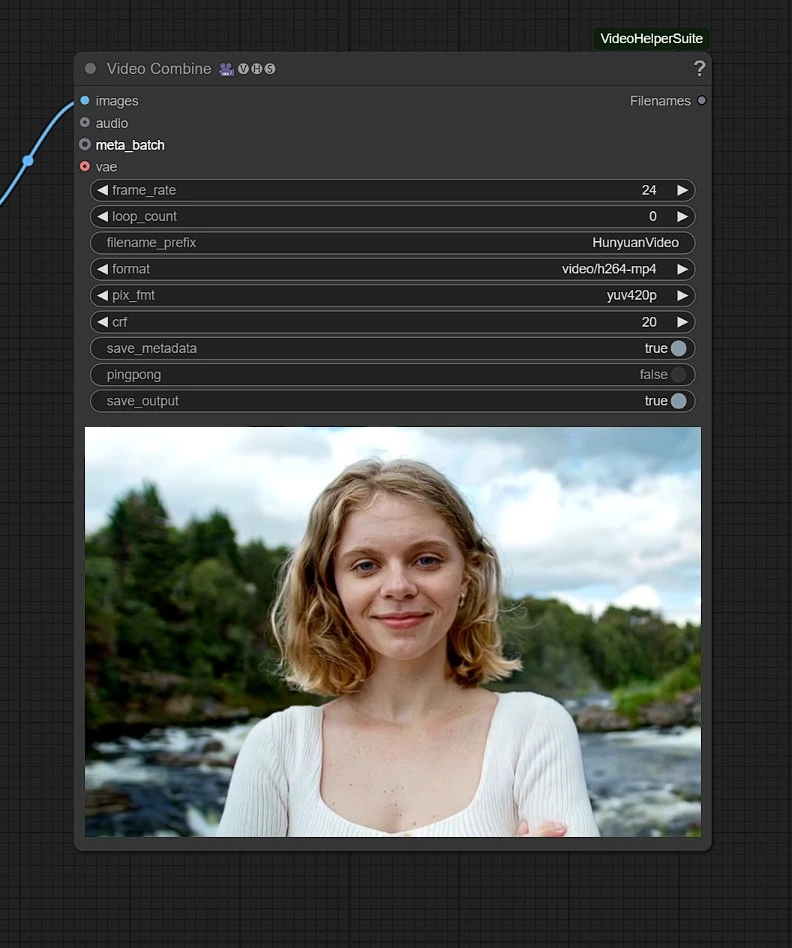
El video renderizado se guardará en la carpeta de Salidas en Comfyui.
Con el flujo de trabajo Hunyuan IP2V, ya no estás limitado a la generación de video basada en texto ahora, puedes dar vida a tus imágenes con movimiento y estilo. Ya sea para cine con IA, arte digital o narración creativa, este flujo de trabajo te da el poder de moldear tu visión con más control que nunca.