
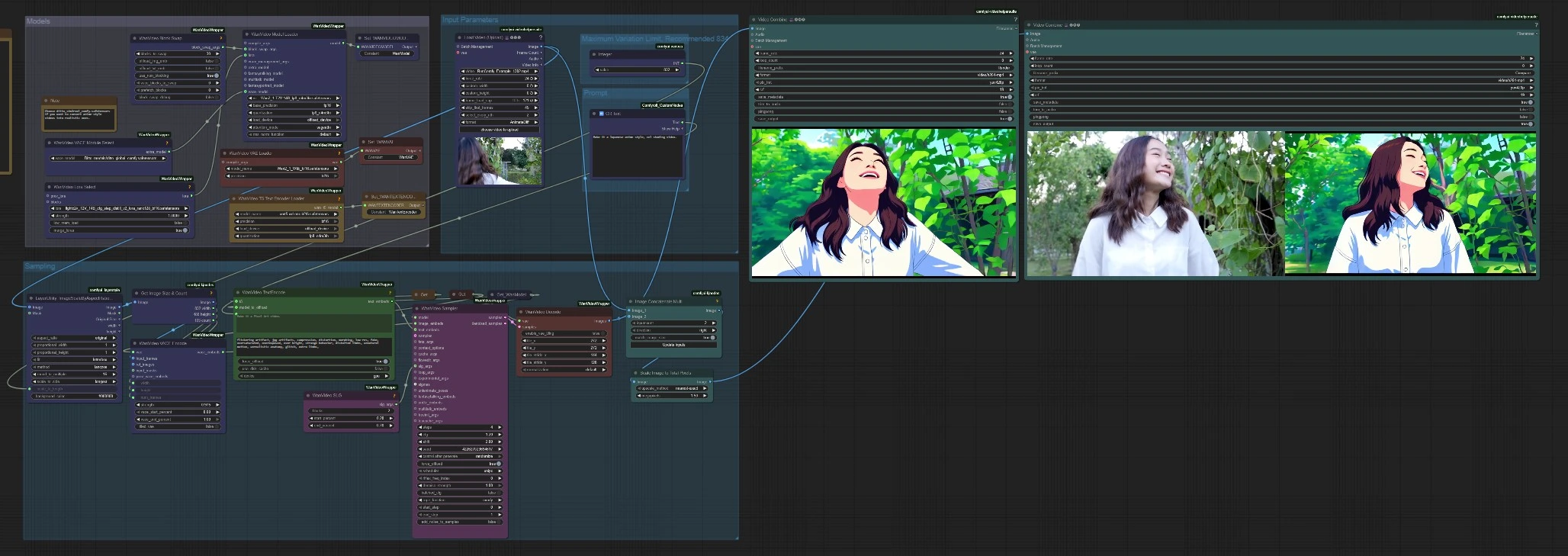
Wan 2.1 Ditto-Video-Umgestaltungs-Workflow für ComfyUI#
Dieser Workflow wendet Wan 2.1 Ditto an, um jedes Eingabevideo neu zu gestalten, während die Szenenstruktur und Bewegung beibehalten wird. Er ist für Editoren und Kreative gedacht, die filmische, künstlerische oder experimentelle Looks mit starker zeitlicher Konsistenz wünschen. Sie laden einen Clip, beschreiben das Zielbild, und Wan 2.1 Ditto erzeugt ein sauberes stilisiertes Render plus einen optionalen Vergleich nebeneinander für eine schnelle Überprüfung.
Der Graph kombiniert das Wan 2.1 Text-zu-Video-Backbone mit Dittos Stiltransfer auf Modellebene, sodass Änderungen kohärent über die Frames hinweg erfolgen, anstatt als Frame-für-Frame-Filter. Häufige Anwendungsfälle umfassen Anime-Konvertierungen, Pixelkunst, Knetanimation, Aquarell, Steampunk oder Sim-zu-Real-Bearbeitungen. Wenn Sie bereits Inhalte mit Wan generieren, fügt sich dieser Wan 2.1 Ditto-Workflow direkt in Ihre Pipeline ein und sorgt für zuverlässige, flimmerfreie Video-Stilistik.
Schlüsselmodelle im Comfyui Wan 2.1 Ditto-Workflow#
- Wan2.1-T2V-14B Text-zu-Video-Modell. Dient als generatives Rückgrat, das zeitlich konsistente Bewegungen aus Text und visueller Konditionierung synthetisiert.
- Wan 2.1 VAE. Kodiert und dekodiert Video-Latents, sodass der Sampler in einem kompakten Raum arbeiten kann und dann zuverlässig Vollauflösungs-Frames rekonstruiert.
- mT5-XXL-Textencoder. Wandelt Eingabeaufforderungen in reichhaltige Sprach-Einbettungen um, die den Szeneninhalt und Stil steuern. Für Hintergrundinformationen zu mT5 siehe das Papier von Xue et al. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer.
- Ditto-Stilisierungsmodell für Wan 2.1. Bietet robuste, globale Umgestaltung mit starker zeitlicher Kohärenz. Der Ditto-Ansatz und die Modelfiles sind hier dokumentiert: EzioBy/Ditto.
- Optionales LoRA für Wan 2.1 14B. Fügt leichte Stil- oder Verhaltensänderungen hinzu, ohne das Basismodell neu zu trainieren, gemäß der LoRA-Methode beschrieben in Hu et al., 2021.
So verwenden Sie den Comfyui Wan 2.1 Ditto-Workflow#
Der Workflow läuft in vier Phasen: Modelle laden, das Eingabevideo vorbereiten, Text und Visuals kodieren, dann sampeln und exportieren. Gruppen arbeiten in Sequenz, um sowohl ein stilisiertes Render als auch einen optionalen Vergleich nebeneinander zu erzeugen.
Modelle#
Diese Gruppe bereitet alles vor, was Wan 2.1 Ditto benötigt. Das Basis-Backbone wird mit WanVideoModelLoader (#130) geladen und mit dem WanVideoVAELoader (#60) und LoadWanVideoT5TextEncoder (#80) kombiniert. Die Ditto-Komponente wird mit WanVideoVACEModelSelect (#128) ausgewählt, das das Backbone auf die dedizierten Ditto-Stilisierungsgewichte verweist. Wenn Sie eine stärkere Transformation benötigen, können Sie ein LoRA mit WanVideoLoraSelect (#122) anhängen. WanVideoBlockSwap (#68) ist für das Speicher-Management verfügbar, damit größere Modelle reibungslos auf begrenztem VRAM laufen können.
Eingabeparameter#
Laden Sie Ihren Quellclip mit VHS_LoadVideo (#101). Die Frames werden dann mit LayerUtility: ImageScaleByAspectRatio V2 (#76) für konsistente Geometrie skaliert, wobei das Seitenverhältnis beibehalten wird, während eine Auflösung der langen Seite durch eine einfache Ganzzahleingabe JWInteger (#89) gesteuert wird. GetImageSizeAndCount (#65) liest die vorbereiteten Frames und leitet Breite, Höhe und Frameanzahl an nachgelagerte Knoten weiter, sodass Wan 2.1 Ditto die richtige räumliche Größe und Dauer sampelt. Ein kleiner Eingabeaufforderungs-Helfer CR Text (#104) ist enthalten, wenn Sie die Eingabeaufforderung lieber in einem eigenen Feld verfassen möchten. Die Gruppe mit dem Titel „Maximum Variation Limit“ erinnert Sie daran, das Pixelziel der langen Seite in einem praktischen Bereich zu halten, um konsistente Ergebnisse und eine stabile Speichernutzung zu gewährleisten.
Sampling#
Die Konditionierung erfolgt in zwei parallelen Spuren. WanVideoTextEncode (#111) verwandelt Ihre Eingabeaufforderung in Texteingebettungen, die die Absicht und den Stil definieren. WanVideoVACEEncode (#126) kodiert das vorbereitete Video in visuelle Einbettungen, die Struktur und Bewegung für die Bearbeitung bewahren. Ein optionales Leitmodul WanVideoSLG (#129) steuert, wie das Modell Stil und Inhalt durch die Rauschtrajektorie ausbalanciert. WanVideoSampler (#119) fusioniert dann das Wan 2.1-Backbone mit Ditto, den Texteingebettungen und den visuellen Einbettungen, um stilisierte Latents zu erzeugen. Schließlich rekonstruiert WanVideoDecode (#87) Frames aus Latents, um die stilisierte Sequenz mit der zeitlichen Konsistenz zu produzieren, für die Wan 2.1 Ditto bekannt ist.
Ausgaben und Vergleiche#
Der primäre Export verwendet VHS_VideoCombine (#95), um das Wan 2.1 Ditto-Render bei Ihrer ausgewählten Bildrate zu speichern. Für eine schnelle Überprüfung verbindet der Graph Original- und stilisierte Frames mit ImageConcatMulti (#94), dimensioniert den Vergleich mit ImageScaleToTotalPixels (#133) und schreibt einen Vergleichsfilm nebeneinander über VHS_VideoCombine (#100). In der Regel erhalten Sie zwei Videos im Ausgabeverzeichnis: ein sauberes stilisiertes Render und einen Vergleichsclip, der den Stakeholdern hilft, schneller zu genehmigen oder zu iterieren.
Eingabeaufforderungsideen#
Sie können mit kurzen, klaren Eingabeaufforderungen beginnen und iterieren. Beispiele, die gut mit Wan 2.1 Ditto funktionieren:
- Machen Sie es im japanischen Anime-Stil, Cel Shading-Video.
- Machen Sie es zu einem Pixel-Art-Video.
- Machen Sie es zu einem Bleistiftskizzen-Video.
- Machen Sie es zu einem Knetanimations-Video.
- Machen Sie es zu einem Aquarell-Zeichenstil-Video.
- Machen Sie es im Steampunk-Stil mit Zahnrädern, Rohren und Messingdetails.
- Machen Sie es im Cyberpunk-Stil mit Neon und futuristischen Implantaten.
- Machen Sie es im Ukiyo-e-Stil-Video.
- Machen Sie es im Renaissance-Kunststil-Video.
- Machen Sie es zu einer Zeichnung von Van Gogh.
- Verwandeln Sie es in den LEGO-Stil.
- Verwandeln Sie es in den Ghibli-Stil.
- Verwandeln Sie es in den 3D-Chibi-Stil.
- Verwandeln Sie es in den Papierschneide-Stil.
Schlüsselnoten im Comfyui Wan 2.1 Ditto-Workflow#
WanVideoVACEModelSelect (#128) Wählen Sie, welche Ditto-Gewichte für die Stilisierung verwendet werden sollen. Das Standard-Globale Ditto-Modell ist eine ausgewogene Wahl für die meisten Aufnahmen. Wenn Ihr Ziel eine Anime-zu-Real-Konvertierung ist, wählen Sie die Sim-zu-Real-Ditto-Variante, die in der Knoten-Notiz referenziert wird. Das Wechseln von Ditto-Varianten ändert den Charakter der Umgestaltung, ohne andere Einstellungen zu berühren.
WanVideoVACEEncode (#126) Erstellt die visuelle Konditionierung aus Ihren Eingabeframes. Die wichtigsten Steuerungen sind width, height und num_frames, die mit dem vorbereiteten Video übereinstimmen sollten, um die besten Ergebnisse zu erzielen. Verwenden Sie strength, um zu adjustieren, wie stark Dittos Stil die Bearbeitung beeinflusst, und vace_start_percent und vace_end_percent, um einzuschränken, wann die Konditionierung über die Diffusionstrajektorie angewendet wird. Aktivieren Sie tiled_vae bei sehr großen Auflösungen, um den Speicherbedarf zu reduzieren.
WanVideoTextEncode (#111) Kodiert positive und negative Eingabeaufforderungen über den mT5-XXL-Encoder, um Stil und Inhalt zu leiten. Halten Sie positive Eingabeaufforderungen prägnant und beschreibend, und verwenden Sie negative, um Artefakte wie Flimmern oder Übersättigung zu unterdrücken. Die Optionen force_offload und device ermöglichen es Ihnen, Geschwindigkeit gegen Speicher zu tauschen, wenn Sie große Modelle ausführen.
WanVideoSampler (#119) Führt das Wan 2.1-Backbone mit Ditto-Stilisierung aus, um die endgültigen Latents zu erzeugen. Die einflussreichsten Einstellungen sind steps, cfg, scheduler und seed. Verwenden Sie denoise_strength, wenn Sie mehr von der ursprünglichen Struktur erhalten möchten, und halten Sie slg_args verbunden, um die Inhaltsfidelity gegen die Stilstärke auszugleichen. Eine Erhöhung der Schritte oder der Anleitung kann Details verbessern, auf Kosten der Zeit.
ImageScaleByAspectRatio V2 (#76) Setzt eine stabile Zielgröße für alle Frames vor der Konditionierung. Treiben Sie das Ziel der langen Seite mit der eigenständigen Ganzzahl, damit Sie kleine, schnelle Vorschauen testen können und dann die Auflösung für endgültige Render erhöhen. Halten Sie die Skalierung zwischen den Iterationen konsistent, um A/B-Vergleiche sinnvoll zu machen.
VHS_LoadVideo (#101) und VHS_VideoCombine (#95, #100) Diese Knoten bearbeiten das Dekodieren und Kodieren. Stimmen Sie die Bildraten mit der Quelle ab, wenn Ihnen das Timing wichtig ist. Der Vergleichsschreiber ist während der Erkundung nützlich und kann für endgültige Exporte deaktiviert werden, wenn Sie nur das stilisierte Ergebnis wünschen.
Optionale Extras#
- Für Anime-zu-Real-Bearbeitungen wählen Sie die Sim-zu-Real-Ditto-Variante in
WanVideoVACEModelSelect, bevor Sie sampeln. - Beginnen Sie mit kurzen Eingabeaufforderungen wie „Machen Sie es im Aquarell-Zeichenstil“ und verfeinern Sie mit 1 oder 2 Beschreibungen. Lange Listen neigen dazu, die Stilstärke zu verwässern.
- Verwenden Sie negative Eingabeaufforderungen, um Flimmern, Kompressionsartefakte und überhelle Highlights zu reduzieren, wenn Sie starke Looks anstreben.
- Halten Sie Ihre Auflösung der langen Seite konsistent über Iterationen hinweg, um Ergebnisse zu stabilisieren und Seeds reproduzierbar zu machen.
- Wenn der VRAM knapp ist, aktivieren Sie Modell-Offloading und Tiling-Optionen oder erstellen Sie eine Vorschau mit einem kleineren Wert der langen Seite, bevor Sie in voller Größe rendern.
Dieser Wan 2.1 Ditto-Workflow macht hochwertige Video-Umgestaltung vorhersehbar und schnell, mit klaren Eingabeaufforderungen, kohärenter Bewegung und Ausgaben, die sofort zur Überprüfung oder Lieferung bereit sind.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken EzioBy für Wan 2.1 Ditto Source für ihre Beiträge und Wartung. Für autoritative Details beziehen Sie sich bitte auf die unten verlinkte Originaldokumentation und Repositories.
Ressourcen#
- EzioBy/Wan 2.1 Ditto Source
- GitHub: EzioBy/Ditto
Hinweis: Die Verwendung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.
