
Stable Audio Open 1.0 Text-zu-Musik-Workflow#
Dieser Workflow verwandelt einfachen Text in Originalmusik und Klanglandschaften mit Stable Audio Open 1.0. Er ist für Komponisten, Sounddesigner und Kreative konzipiert, die schnelle, kontrollierbare Audiogenerierung wünschen, ohne ComfyUI zu verlassen. Sie schreiben eine Vorgabe, setzen eine Zieldauer, und der Graph rendert eine MP3, die Ihren Stil, Ihre Stimmung, Ihr Tempo und Ihre Instrumentierung widerspiegelt.
Unter der Haube kodiert der Workflow Ihren Text mit einem T5-basierten Text-Encoder, führt Stable Audio’s Diffusionsprozess im latenten Audiobereich durch, dekodiert dann zu einer Wellenform und speichert das Ergebnis. Mit klaren Vorgabenanleitungen und einer einfachen Längensteuerung wird die Stable Audio-Generierung vorhersehbar und wiederholbar für filmische, ambientale oder experimentelle Tracks.
Schlüsselmodelle im ComfyUI Stable Audio-Workflow#
- Stable Audio Open 1.0. Open-weights latentes Diffusionsmodell für Text-zu-Musik und Sounddesign von Stability AI. Es ordnet Textabsichten Audiolatenten zu und unterstützt verschiedene musikalische Stile und Strukturen. Repository • Weights
- T5-Base Text Encoder. Allgemein verwendetes Textmodell, das hier verwendet wird, um Vorgaben für die Konditionierung der Stable Audio-Generierung einzubetten. Klare, beschreibende Eingaben führen zu konsistenterer Musik. Model card
So verwenden Sie den ComfyUI Stable Audio-Workflow#
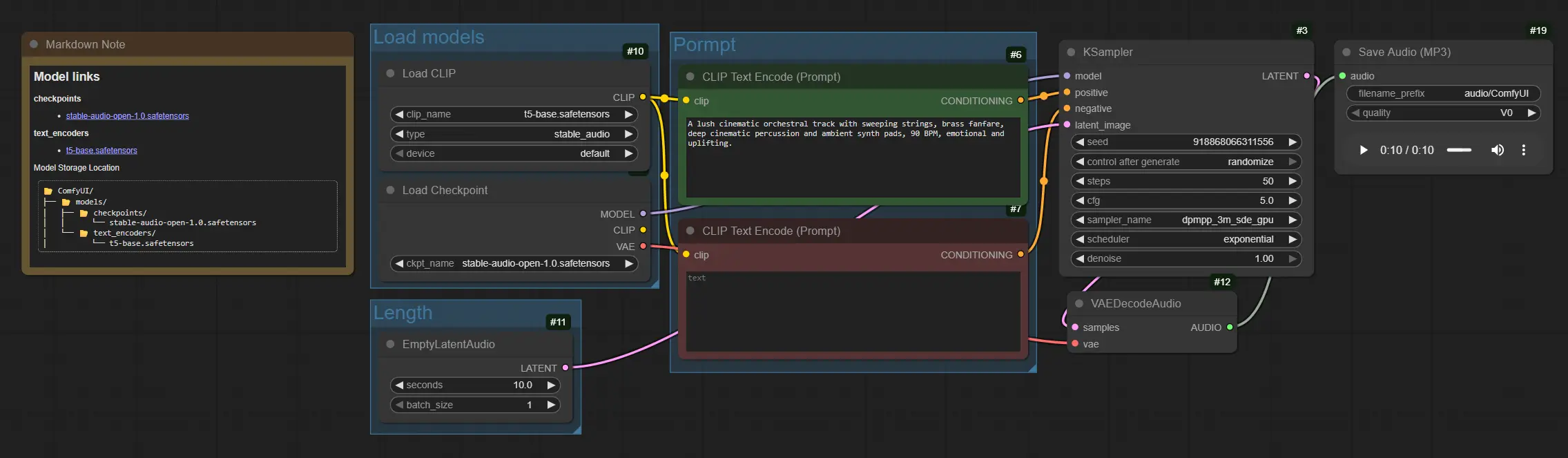
Der Graph fließt vom Modellladen zur Vorgabenkonditionierung, dann zum Sampling, Dekodieren und Speichern. Gruppen sind organisiert, sodass Sie Modelle einmal festlegen, die Länge anpassen, Ihre Vorgabe schreiben und rendern können.
Modelle laden#
Diese Gruppe initialisiert die Kernassets. CheckpointLoaderSimple (#4) lädt den Stable Audio Open 1.0 Checkpoint, der das Diffusionsmodell und sein Audio VAE enthält. CLIPLoader (#10) lädt den T5-basierten Text-Encoder, der für die Konditionierung verwendet wird. Sobald geladen, bieten diese Modelle das Rückgrat für die Stable Audio-Generierung und bleiben für nachfolgende Durchläufe im Speicher.
Länge#
Diese Gruppe definiert, wie lange Ihr Audio sein wird. EmptyLatentAudio (#11) erstellt eine leere latente Spur mit Ihrer gewählten Dauer, sodass der Sampler weiß, wie viele Frames er generieren muss. Längere Clips verbrauchen mehr Zeit und Speicher, daher beginnen Sie bescheiden und skalieren dann. Sie können auch mehrere Variationen erzeugen, indem Sie die Batch-Dimension erhöhen, wenn Sie Ideen erkunden.
Vorgabe#
Diese Gruppe verwandelt Text in die Leitsignale für den Diffusionsprozess. Verwenden Sie CLIPTextEncode (#6), um eine positive Vorgabe mit Instrumenten, Genre, Stimmung, Tempo und Produktionshinweisen zu schreiben, zum Beispiel: "üppiges filmisches Orchester, schwingende Streicher und Blechbläser, tiefe Percussion, ambient Pads, 90 BPM, erhebend." Verwenden Sie CLIPTextEncode (#7) für eine negative Vorgabe, um Artefakte wie "raues Rauschen, Clipping, Verzerrung" zu unterdrücken. Gemeinsam lenken sie Stable Audio in die gewünschten Texturen und Strukturen.
Generieren und exportieren#
KSampler (#3) führt die Diffusionsschritte aus, die das leere Latente in ein musikalisches Latente verwandeln, das von Ihren Textkodierungen geleitet wird. VAEDecodeAudio (#12) wandelt das latente Audio zurück in eine Wellenform um. Schließlich schreibt SaveAudioMP3 (#19) eine MP3-Datei, sodass Sie sie überprüfen oder direkt in Ihre Timeline einfügen können. Für iterative Arbeiten passen Sie das Dateinamenpräfix an, um Takes organisiert zu halten.
Schlüssel-Knoten im ComfyUI Stable Audio-Workflow#
CLIPTextEncode(#6) Dieser Knoten kodiert Ihre positive Vorgabe in eine Konditionierung, der Stable Audio folgt. Priorisieren Sie klare Instrumentenlisten, Genre, Stimmung, Tempo oder BPM und Produktionsbegriffe wie "warm," "lo-fi," "cinematic," oder "ambient." Subtile Wortänderungen können die Komposition bedeutend verschieben. Siehe ComfyUI-Kernknoten für allgemeines Verhalten. ComfyUICLIPTextEncode(#7) Die negative Vorgabe hilft, unerwünschte Klangfarben oder Mixprobleme zu vermeiden. Fügen Sie Begriffe hinzu, die beschreiben, was entfernt werden soll, zum Beispiel "kreischend, metallisches Klingeln, Glitch-Pops, Radio-Rauschen." Diese prägnant zu halten, führt oft zu saubereren Stable Audio-Renderings. ComfyUIEmptyLatentAudio(#11) Steuert die Clip-Dauer in Sekunden und optional die Batch-Anzahl für mehrere Variationen. Erhöhen Sie die Sekunden für längere Stücke, beachten Sie, dass die Berechnung mit der Länge skaliert. Verwenden Sie die Batch-Generierung, um mehrere Stable Audio-Takes aus einer einzigen Vorgabe zu hören. ComfyUIKSampler(#3) Treibt den Diffusionsprozess für Audio-Latente an. Die einflussreichsten Steuerungen sindsteps,sampler,cfgundseed. Erhöhen Siestepsfür mehr verfeinerte Details, passen Siecfgan, um die Vorgabentreue mit Kreativität auszubalancieren, und setzen Sie einen festenseed, um einen Take zu reproduzieren oder ihn für neue Ideen zu variieren. Siehe ComfyUI’s Sampler-Hinweise für allgemeine Anleitung. ComfyUISaveAudioMP3(#19) Exportiert die finale Wellenform in eine MP3. Verwenden Sie dasfilename_prefix, um Versionen zu kennzeichnen und Iterationen ordentlich zu halten. Beim Vergleich von Vorgaben oder Seeds beschleunigt das Speichern mehrerer Takes nebeneinander die Auswahl von Stable Audio. ComfyUI
Optionale Extras#
- Schreiben Sie Vorgaben wie ein Session-Briefing: Instrumente, Genre, Stimmung, Tempo oder BPM und Mix-Adjektive.
- Verwenden Sie kurze, fokussierte negative Vorgaben, um Rauschen, Härte oder unerwünschte Instrumente zu reduzieren.
- Sperren Sie
seed, während Sie Text iterieren, und ändern Sieseed, um neue Stable Audio-Variationen zu erkunden. - Beginnen Sie mit kürzeren Dauern, um den Stil einzustellen, und verlängern Sie dann, wenn der Klang stimmt.
- Halten Sie ein konsistentes Dateinamenpräfix pro Konzept, damit Sie später Stable Audio-Takes A/B testen können.
Ressourcen für tiefere Lektüre: Stable Audio-Modell-Details und Beispiele hier, ComfyUI-Kern und Knotenverhalten hier, und die T5-Base Modellkarte hier.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Stability AI für Stable Audio Open, comfyanonymous (ComfyUI) für die ComfyUI-Knoten und Workflow-Referenzen, und Comfy-Org und ComfyUI-Wiki für den Stable Audio Open 1.0 Checkpoint und den T5-Base Text-Encoder für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die unten verlinkte Originaldokumentation und Repositories.
Ressourcen#
- Comfy-Org/Stable Audio Open 1.0 Workflow
- GitHub: Stability-AI/stable-audio-open
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.
