
LTX-2.3 ICLoRA LipDub für ComfyUI#
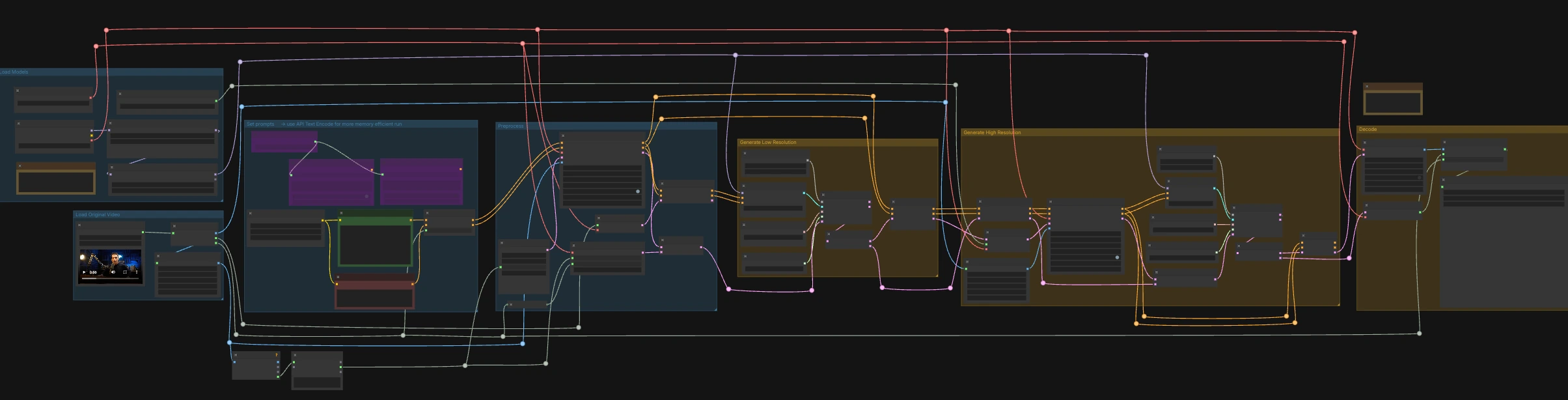
LTX-2.3 ICLoRA LipDub ist ein zweistufiger, video- und audiogesteuerter ComfyUI-Workflow, der eine sprechende Person synchronisiert, während Identität und Bewegung konsistent bleiben. Er kombiniert Lightricks LTX-2.3 Text- und Videokonditionierung mit dem LipDub IC-LoRA, um die Mundbewegung präzise zur bereitgestellten Sprache auszurichten und das Ergebnis dann mit höherer Auflösung für gestochen scharfe Details zu verfeinern. Der Graph ist für RunComfy mit standardisierten Eingabe-/Ausgabebezeichnungen vorbereitet, sodass Sie Medien austauschen und Läufe zuverlässig wiederholen können.
Dieser ComfyUI LTX-2.3 ICLoRA LipDub-Workflow ist ideal für Kreative, die mehrsprachige Synchronisation, Umformulierungen oder ADR-ähnliche Korrekturen benötigen, während die ursprüngliche Darbietung erhalten bleibt. Stellen Sie ein Quellvideo bereit, das die Zielsprache bereits enthält, beschreiben Sie die Szene und was die Person sagen soll, und der Workflow wird synchronisierte visuelle und akustische Inhalte in einen fertigen Clip umwandeln.
Schlüsselmodelle im Comfyui LTX-2.3 ICLoRA LipDub-Workflow#
- LTX-2.3 22B Basismodell. Das grundlegende Diffusionsmodell, das das Video generiert und steuert, wie Eingaben Aussehen, Bewegung und Stil beeinflussen.
- LTX-2.3 IC-LoRA LipDub. Eine LoRA, die speziell für LipDub entwickelt wurde und das Modell dazu bringt, der bereitgestellten Sprache zu folgen und Mundformen an Phoneme anzupassen, während Identität und Kopfbewegungen erhalten bleiben. Model card
- LTX-2.3 Audio VAE. Kodiert die Eingabesprache in ein Audio-Latent, das in die Textkonditionierung eingespeist und später wieder in Wellenform dekodiert werden kann, um sicherzustellen, dass das Timing mit den Frames synchron bleibt.
- LTX-2.3 Spatial Upscaler x2. Skaliert Videolatente auf höhere räumliche Auflösung, bevor der Hochauflösungs-Verfeinerungsschritt durchgeführt wird, um die Textur zu verbessern, ohne die Bewegung zu verändern.
- LTX-2.3 Distilled LoRA (384). Eine verstärkende LoRA, die zusammen mit dem Basismodell verwendet wird, um Details und zeitliche Stabilität zu verbessern, ohne sich zu stark an den Referenzrahmen anzupassen.
Verwendung des Comfyui LTX-2.3 ICLoRA LipDub-Workflows#
Dieser Workflow läuft in zwei koordinierten Stufen: Ein Durchgang mit niedriger Auflösung, um Timing und Lippenformen an das Audio anzupassen, gefolgt von einem hochauflösenden Durchgang, der Details aufwertet und verfeinert, während die Synchronisation erhalten bleibt. Beginnen Sie mit dem Laden eines Quellvideos, das die gewünschte Sprache bereits enthält, und schreiben Sie die Textzeile, die die Person sagen soll.
Originalvideo laden#
Der LoadVideo (#5002) Knoten importiert Ihren Quellclip mit eingebettetem Audio. GetVideoComponents (#5010) extrahiert Frames, Audio und die Bildrate; die Bildrate wird im gesamten Graph geteilt, sodass Video und Audio synchron bleiben. Zwei Resizer, Resize Image/Mask (s1 size) (#5009) und Resize Image/Mask (s2 size) (#5003), bereiten Arbeitsbildströme für die Durchgänge mit niedriger und hoher Auflösung vor. Die Frameanzahl wird gemessen und für samplerfreundliche Längen gerundet, damit das Decodieren stabil bleibt.
Modelle laden#
CheckpointLoaderSimple (#5017) lädt das LTX-2.3 22B Basismodell und VAE, die im gesamten Graph verwendet werden. Zwei Loader, LoraLoaderModelOnly (#5018) und LTXICLoRALoaderModelOnly (#5012), fügen die distilled LoRA und die IC-LoRA LipDub dem Basismodell hinzu, damit der Generator der Sprache folgt, während die Identität erhalten bleibt. LTXVAudioVAELoader (#4010) stellt das Audio VAE für die Kodierung/Dekodierung des Soundtracks bereit. Die latent_downscale_factor Ausgabe des IC-LoRA Loaders wird hier absichtlich nicht verwendet, da das LipDub-Training vollauflösende Referenzrahmen voraussetzt, was der beigefügten Notiz entspricht.
Eingaben setzen#
Schreiben Sie Ihre Szenenbeschreibung und die genaue gesprochene Zeile in CLIP Text Encode (Positive Prompt) (#2483). Verwenden Sie CLIP Text Encode (Negative Prompt) (#2612), um unerwünschte Merkmale oder Artefakte zu minimieren. Diese fließen in LTXVConditioning (#1241) ein, das die Konditionierung an die Videodomäne anpasst und den Kontext der Bildrate weiterträgt. Für Low-VRAM-Läufe enthält der Graph auch API-basierte Encoder (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) und ... - NEGATIVE (#4981)), die durch die LTX API KEY Zeichenfolge (#4979) gesteuert werden; die Standardverdrahtung verwendet lokale Encoder.
Vorverarbeitung#
LTXVAudioVAEEncode (#5005) wandelt die Quellsprache in ein Audio-Latent um, und LTXVSetAudioRefTokens (#5006) injiziert dieses Latent in die Textkonditionierung, sodass der Generator das Timing und die Phoneme "hört". EmptyLTXVLatentVideo (#3059) bereitet ein Platzhalter-Videolatent mit der richtigen räumlichen Größe und einer Frameanzahl vor, die auf die Eingabe abgestimmt ist. LTXAddVideoICLoRAGuide (#5004) fügt die IC-LoRA-Referenzführung mit den s1-Frames hinzu, um Identität und Mundbereichsaufmerksamkeit vor dem Sampling zu etablieren.
Niedrige Auflösung erzeugen#
Eine Standard-Diffusionsschleife wird durch CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984) und SamplerCustomAdvanced (#4829) gebildet. Der Sampler arbeitet an einem Audio+Video-Latenten, das durch LTXVConcatAVLatent (#4528) zusammengesetzt wird, sodass die Audiokonditionierung in jedem Schritt beteiligt ist. Nach dem Sampling trennt LTXVSeparateAVLatent (#4845) das Latent, sodass LTXVSetAudioRefTokens (#5013) dieselbe Sprachdarstellung für den hochauflösenden Durchgang einfrieren kann. Diese Stufe fixiert Lippenformen zur Sprache und setzt die Bewegungsbasis bei s1-Größe.
Hohe Auflösung erzeugen#
LTXVLatentUpsampler (#4975) hebt das Videolatent mit dem Spatial Upscaler x2 an und bewahrt die Bewegung, während es Platz für räumliche Details schafft. LTXAddVideoICLoRAGuide (#5014) wendet IC-LoRA bei s2-Größe mit den hochauflösenden Frames erneut an, sodass Identität, Mundbereich und feine Merkmale verstärkt werden. Eine zweite Diffusionsschleife (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971)) verfeinert das hochskalierte Latent, während LTXVConcatAVLatent (#4969) das eingefrorene Sprachlatent im Gleichschritt hält. LTXVCropGuides (#5011, #5015) verwaltet sichere Zuschnitte und Bereichsführungen, sodass das Gesicht über beide Durchgänge hinweg richtig gerahmt bleibt.
Dekodieren#
LTXVTiledVAEDecode (#4995) wandelt das finale Videolatent in Bilder um, indem es Kacheln für VRAM-Effizienz verwendet, und LTXVAudioVAEDecode (#4848) gibt das synchronisierte Audio zurück. CreateVideo (#4849) setzt die Frames und das Audio mit der ursprünglichen Bildrate zusammen, und SaveVideo (#4852) schreibt die Datei mit dem vorgefüllten RunComfy-Namen; ändern Sie diesen Wert, um Ihre Ausgaben zu kennzeichnen. Das Ergebnis ist ein vollständig synchronisierter LTX-2.3 ICLoRA LipDub-Clip, bereit zur Überprüfung oder Lieferung.
Schlüsselnoten im Comfyui LTX-2.3 ICLoRA LipDub-Workflow#
LTXICLoRALoaderModelOnly (#5012)#
Lädt das LipDub IC-LoRA und fügt es dem Basismodell hinzu, sodass die Lippenbewegung der Eingabesprache folgt, ohne die Identität zu überschreiben. Wenn Sie eine stärkere oder subtilere Lippensteuerung benötigen, passen Sie das LoRA-Gewicht hier an; halten Sie es koordiniert mit jedem zusätzlichen LoRA, das Sie im Stack anwenden, um eine Überkonditionierung zu vermeiden.
LTXAddVideoICLoRAGuide (#5004)#
Wendet die IC-LoRA-Führung in der Stufe mit niedriger Auflösung mit den herunterskalierten Referenzrahmen an. Dies ist der Punkt, an dem der Workflow erstmals Identität und Mundbereichsaufmerksamkeit fixiert; verwenden Sie es für A/B-Tests, indem Sie die Führung umschalten, um den Effekt der Referenzführung auf Timing und Artikulation zu sehen.
LTXAddVideoICLoRAGuide (#5014)#
Wendet die IC-LoRA-Führung bei hoher Auflösung mit den s2-Frames erneut an, sodass der verfeinerte Durchgang dieselbe Sprecheridentität und genaue Lippenformen bewahrt. Wenn Sie die hochauflösende Bildgröße ändern, überprüfen Sie diesen Knoten, um die Referenzführung mit Ihrem Zielausgang konsistent zu halten.
LTXVSetAudioRefTokens (#5006)#
Bindet die kodierte Sprache an Ihre Textkonditionierung, sodass der Sampler Visemen mit Phonemen ausrichtet. Verwenden Sie dasselbe Audio-Latent über beide Durchgänge für stabile Ergebnisse; dieser Graph handhabt das automatisch, aber wenn Sie das Audio während des Laufs austauschen, sollten Sie sowohl die Konditionierung als auch das zusammengefügte Latent aktualisieren.
LTXVLatentUpsampler (#4975)#
Skaliert das Videolatent mit dem LTX-2.3 Spatial Upscaler x2 hoch, um Platz für feine Details vor dem hochauflösenden Sampler zu schaffen. Wenn der VRAM knapp ist, kombinieren Sie dies mit kleineren s2-Dimensionen oder leichterem Tiling im Decoder, um Qualität und Durchsatz auszugleichen.
LTXVTiledVAEDecode (#4995)#
Dekodiert das finale Latent zu Frames, indem es Kacheln verwendet, um große Ausgaben auf begrenzten GPUs zu ermöglichen. Passen Sie die Kachelanzahl und Überlappung hier an, um Geschwindigkeit gegen Speicherbedarf zu tauschen; weniger Kacheln sind schneller, erfordern aber mehr VRAM, während mehr Kacheln den VRAM reduzieren, aber Zeit kosten.
Optionale Extras#
- Eingaben für Synchronisation: Geben Sie die genauen Wörter ein, die gesprochen werden sollen; das Modell übersetzt nicht automatisch. Verwenden Sie das native Skript der Zielsprache, bleiben Sie bei einem einzigen Sprecher und streben Sie eine ähnliche Länge zur ursprünglichen Zeile an, damit das Timing natürlich bleibt.
- Leistungstipps: Wenn Sie an VRAM-Grenzen stoßen, reduzieren Sie die s2-Größe in
Resize Image/Mask (s2 size)(#5003) und erhöhen Sie das Tiling inLTXVTiledVAEDecode(#4995). Für Wiederholbarkeit halten Sie dieRandomNoise-Seeds in beiden Durchgängen fest. - Workflow-Standardeinstellungen: Der Beispiel-Eingabedateiname ist in
LoadVideo(#5002) vorgefüllt, und der Speicher legt einen konsistenten Ausgabename fest. Ersetzen Sie beide, um mehrere LTX-2.3 ICLoRA LipDub-Läufe zu stapeln, ohne Ergebnisse zu überschreiben. - Rahmen: Wenn das Gesicht nahe an den Rändern driftet, passen Sie
LTXVCropGuides(#5011, #5015) an, sodass der Mundbereich über beide Durchgänge hinweg in einem stabilen Zuschnitt bleibt.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Lightricks für das LTX-2.3-22b-IC-LoRA-LipDub-Modell und RunComfy für den geteilten ComfyUI-Workflow (Cloud Save Quelle) für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Code unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Verwalter.
