
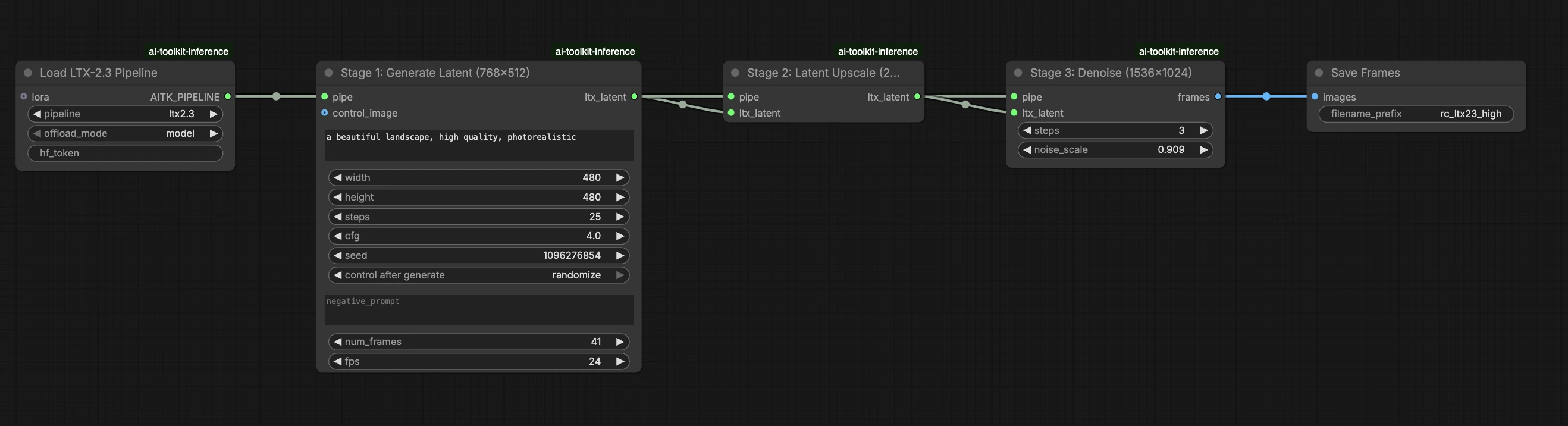
LTX 2.3 LoRA ComfyUI Inferenz: trainingsabgestimmte AI Toolkit LoRA-Ausgabe mit der LTX 2.3-Pipeline#
Dieser produktionsbereite RunComfy-Workflow führt LTX 2.3 LoRA-Inferenz in ComfyUI durch RC LTX 2.3 (LTX2Pipeline) (Pipeline-Ebenenausrichtung, kein generischer Sampler-Graph) aus. RunComfy hat diesen benutzerdefinierten Knoten erstellt und als Open Source bereitgestellt – siehe die runcomfy-com Repositories – und Sie steuern die Adapteranwendung mit lora_path und lora_scale.
Hinweis: Dieser Workflow erfordert eine 2X Large oder größere Maschine zum Ausführen.
Warum LTX 2.3 LoRA ComfyUI Inferenz oft anders aussieht in ComfyUI#
AI Toolkit-Training-Previews werden durch eine modellspezifische LTX 2.3-Pipeline gerendert, bei der Textkodierung, Zeitplanung und LoRA-Injektion darauf ausgelegt sind, zusammenzuarbeiten. In ComfyUI kann der Neuaufbau von LTX 2.3 mit einem anderen Graph (oder einem anderen LoRA-Ladepfad) diese Interaktionen ändern, sodass das Kopieren derselben Eingabeaufforderung, Schritte, CFG und Seed immer noch sichtbare Abweichungen hervorruft. Die RunComfy RC-Pipeline-Knoten schließen diese Lücke, indem sie LTX 2.3 durchgehend in LTX2Pipeline ausführen und Ihre LoRA innerhalb dieser Pipeline anwenden, um die Inferenz mit dem Vorschauverhalten abzustimmen. Quelle: RunComfy Open-Source-Repositories.
So verwenden Sie den LTX 2.3 LoRA ComfyUI Inferenz-Workflow#
Schritt 1: Holen Sie sich den LoRA-Pfad und laden Sie ihn in den Workflow (2 Optionen)#
Option A — RunComfy-Trainingsergebnis → Download zu lokalem ComfyUI:
- Gehen Sie zu Trainer → LoRA Assets
- Finden Sie die LoRA, die Sie verwenden möchten
- Klicken Sie auf das ⋮ (Drei-Punkte) Menü rechts → wählen Sie LoRA-Link kopieren
- Auf der ComfyUI-Workflow-Seite fügen Sie den kopierten Link in das Download-Eingabefeld in der oberen rechten Ecke der Benutzeroberfläche ein
- Bevor Sie auf Download klicken, stellen Sie sicher, dass der Zielordner auf ComfyUI > models > loras gesetzt ist (dieser Ordner muss als Downloadziel ausgewählt sein)
- Klicken Sie auf Download — dies stellt sicher, dass die LoRA-Datei im richtigen
models/lorasVerzeichnis gespeichert wird - Nachdem der Download abgeschlossen ist, aktualisieren Sie die Seite
- Die LoRA erscheint jetzt im LoRA-Auswahl-Dropdown im Workflow — wählen Sie sie aus
Option B — Direkte LoRA URL (überschreibt Option A):
- Fügen Sie die direkte
.safetensorsDownload-URL in daspath / urlEingabefeld des LoRA-Knotens ein - Wenn hier eine URL angegeben wird, überschreibt sie Option A — der Workflow lädt die LoRA direkt von der URL zur Laufzeit
- Kein lokaler Download oder Dateiablage ist erforderlich
Tipp: Bestätigen Sie, dass die URL zur tatsächlichen .safetensors Datei auflöst (nicht zu einer Zielseite oder Umleitung).
Schritt 2: Abgleich der Inferenzparameter mit Ihren Trainingsmuster-Einstellungen#
Im LoRA-Knoten wählen Sie Ihren Adapter in lora_path (Option A), oder fügen Sie einen direkten .safetensors Link in path / url ein (Option B überschreibt das Dropdown). Dann setzen Sie lora_scale auf die gleiche Stärke, die Sie während der Trainings-Previews verwendet haben, und passen Sie von dort an.
Die verbleibenden Parameter befinden sich auf dem Generieren-Knoten (und je nach Graph auf dem Pipeline Laden-Knoten):
prompt: Ihre Texteingabeaufforderung (einschließlich Triggerwörter, wenn Sie damit trainiert haben)width/height: Ausgabeauflösung; passen Sie die Größe Ihrer Trainingsvorschau für den saubersten Vergleich an (Vielfache von 32 werden für LTX 2.3 empfohlen)num_frames: Anzahl der Ausgabevideoframessample_steps: Anzahl der Inferenzschritte (30 ist ein häufiger Standard)guidance_scale: CFG/Leitwert (5.5 ist ein häufiger Standard; nicht über 7 hinausgehen)seed: fester Seed zur Reproduktion; ändern Sie ihn, um Variationen zu erkundenseed_mode(nur wenn vorhanden): wählen Siefixedoderrandomizeframe_rate: Ausgabe-FPS; bleiben Sie konsistent mit den Trainingseinstellungen für Bewegungsabgleich
Trainingstipp: Wenn Sie während des Trainings Sampling-Werte angepasst haben (seed, guidance_scale, sample_steps, Triggerwörter, Auflösung), spiegeln Sie diese genauen Werte hier wider. Wenn Sie auf RunComfy trainiert haben, öffnen Sie Trainer → LoRA Assets > Konfiguration, um das aufgelöste YAML anzuzeigen und Vorschau-/Muster-Einstellungen in die Workflow-Knoten zu kopieren.
Schritt 3: Führen Sie die LTX 2.3 LoRA ComfyUI Inferenz aus#
Klicken Sie auf Warteschlange/Ausführen — der SaveVideo Knoten schreibt Ergebnisse in Ihr ComfyUI-Ausgabeverzeichnis.
Schnell-Checkliste:
- ✓ LoRA ist entweder: heruntergeladen in
ComfyUI/models/loras(Option A), oder geladen über eine direkte.safetensorsURL (Option B) - ✓ Seite nach lokalem Download aktualisiert (nur Option A)
- ✓ Inferenzparameter stimmen mit der Trainings-
sample-Konfiguration überein (falls angepasst)
Wenn alles oben korrekt ist, sollten die Inferenz-Ergebnisse hier eng mit Ihren Trainings-Previews übereinstimmen.
Fehlerbehebung bei LTX 2.3 LoRA ComfyUI Inferenz#
Die meisten LTX 2.3 "Training Preview vs ComfyUI Inference"-Lücken entstehen durch Pipeline-Ebenenunterschiede (wie das Modell geladen, geplant und wie die LoRA integriert wird), nicht durch einen einzigen falschen Knopf. Dieser RunComfy-Workflow stellt die nächstgelegene "training-abgestimmte" Basislinie wieder her, indem die Inferenz durch RC LTX 2.3 (LTX2Pipeline) von Anfang bis Ende ausgeführt wird und Ihre LoRA innerhalb dieser Pipeline über lora_path / lora_scale angewendet wird (anstatt generische Loader/Sampler-Knoten zu stapeln).
(1) LoRA-Formfehlanpassungen oder "Key nicht geladen"-Warnungen#
Warum das passiert Die LoRA wurde für eine andere Modellfamilie oder eine andere LTX-Variante trainiert. Sie werden viele lora key not loaded Zeilen und möglicherweise Formfehlanpassungsfehler sehen.
Wie man es behebt (empfohlen)
- Stellen Sie sicher, dass die LoRA spezifisch für LTX 2.3 mit AI Toolkit trainiert wurde (LTX 2.0 / 2.1 / 2.2 LoRAs sind nicht austauschbar).
- Halten Sie den Graph "Einweg" für LoRA: Laden Sie den Adapter nur über den
lora_path-Eingang des Workflows und lassen Sie LTX2Pipeline die Integration übernehmen. Stapeln Sie keinen zusätzlichen generischen LoRA-Loader parallel. - Wenn Sie bereits auf eine Fehlanpassung gestoßen sind und ComfyUI danach beginnt, nicht verwandte CUDA/OOM-Fehler zu erzeugen, starten Sie den ComfyUI-Prozess neu, um den GPU + Modellzustand vollständig zurückzusetzen, und versuchen Sie es dann erneut mit einer kompatiblen LoRA.
(2) Inferenz-Ergebnisse stimmen nicht mit den Trainings-Previews überein#
Warum das passiert Selbst wenn die LoRA geladen wird, können die Ergebnisse immer noch abweichen, wenn Ihr ComfyUI-Graph nicht mit der Trainingsvorschau-Pipeline übereinstimmt (unterschiedliche Standards, unterschiedliche LoRA-Injektionspfade, unterschiedliche Zeitplanung).
Wie man es behebt (empfohlen)
- Verwenden Sie diesen Workflow und fügen Sie Ihren direkten
.safetensorsLink inlora_pathein. - Kopieren Sie die Sampling-Werte aus Ihrer AI Toolkit-Training-Konfiguration (oder RunComfy Trainer → LoRA Assets Konfiguration):
width,height,num_frames,sample_steps,guidance_scale,seed,frame_rate. - Halten Sie "extra Geschwindigkeitstapel" aus dem Vergleich heraus, es sei denn, Sie haben mit ihnen trainiert/gesampelt.
(3) Die Verwendung von LoRAs erhöht die Inferenzzeit erheblich#
Warum das passiert Eine LoRA kann LTX 2.3 erheblich verlangsamen, wenn der LoRA-Pfad zusätzliche Patching-/Dequantisierungsarbeit erzwingt oder Gewichte in einem langsameren Codepfad als das Basismodell alleine anwendet.
Wie man es behebt (empfohlen)
- Verwenden Sie den RC LTX 2.3 (LTX2Pipeline) Pfad dieses Workflows und übergeben Sie Ihren Adapter über
lora_path/lora_scale. In dieser Konfiguration wird die LoRA einmal während des Pipeline-Ladevorgangs integriert (AI Toolkit-Stil), sodass die pro-Schritt-Sampling-Kosten nahe am Basismodell bleiben. - Wenn Sie ein verhaltensabgestimmtes Verhalten verfolgen, vermeiden Sie es, mehrere LoRA-Loader zu stapeln oder Ladepfade zu mischen. Halten Sie es bei einem
lora_path+ einemlora_scale, bis die Basislinie übereinstimmt.
(4) OOM-Fehler bei großen Auflösungen oder langen Videos#
Warum das passiert LTX 2.3 ist ein 22B-Parameter-Modell und die Videogenerierung ist VRAM-intensiv. Hohe Auflösungen oder viele Frames können den GPU-Speicher überschreiten, insbesondere mit LoRA-Overhead.
Wie man es behebt (empfohlen)
- Verwenden Sie eine 2X Large (80 GB VRAM) oder größere Maschine. Dieser Workflow ist nicht kompatibel mit Medium, Large oder X Large Maschinen.
- Reduzieren Sie die Auflösung oder die Frameanzahl, wenn Sie schnell iterieren müssen, und skalieren Sie dann für endgültige Renderings.
- Aktivieren Sie VAE-Tiling, wenn verfügbar — es kann ~3 GB VRAM mit minimalem Qualitätsverlust sparen.
Führen Sie jetzt die LTX 2.3 LoRA ComfyUI Inferenz aus#
Öffnen Sie den Workflow, setzen Sie lora_path und klicken Sie auf Warteschlange/Ausführen, um LTX 2.3 LoRA-Ergebnisse zu erhalten, die nahe an Ihren AI Toolkit-Training-Previews bleiben.


