
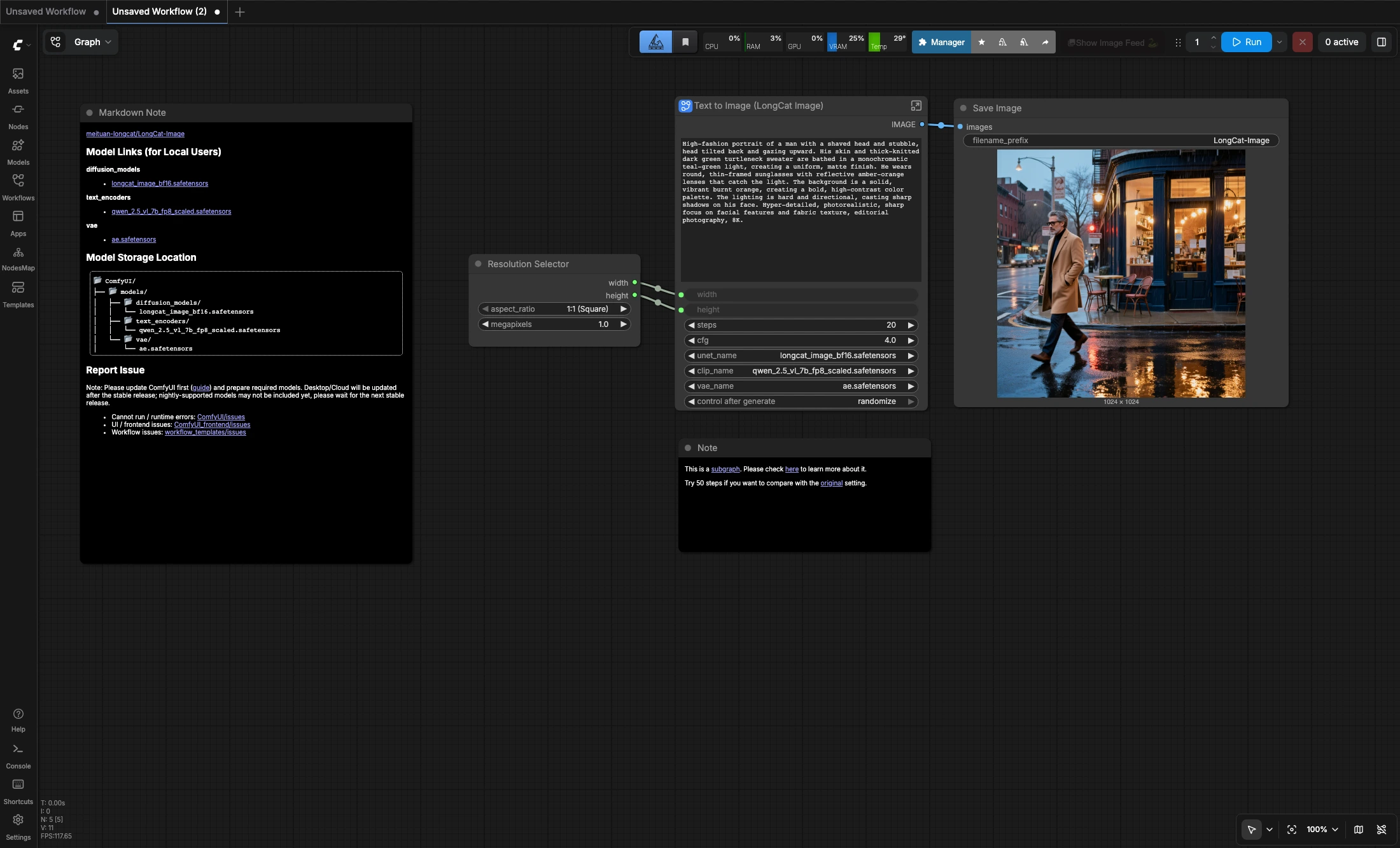



Was ist der LongCat Image Text zu Bild ComfyUI-Workflow?#
LongCat Image Text zu Bild ist ein kompaktes ComfyUI-Workflow zur Erzeugung quadratischer 1024x1024 Bilder aus Textaufforderungen. Es verwendet das LongCat-Image-Diffusionsmodell zusammen mit dem Qwen 2.5 VL-Text-Encoder und dem AE VAE, um Ihnen ein einfaches Aufforderung-zu-Bild-Setup für Porträts, Produktfotos und polierte redaktionelle Visuals zu bieten.
Das Diagramm ist absichtlich einfach: Wählen Sie eine quadratische Auflösung, schreiben Sie Ihre Aufforderung, führen Sie den Workflow aus und speichern Sie das Bild. Es funktioniert gut für schnelle Iterationen in entweder englischen oder chinesischen Aufforderungen, und die beigelegte Notiz schlägt vor, 50 Schritte zu versuchen, wenn Sie das Ergebnis mit der ursprünglichen Modelleinstellung vergleichen möchten.
Hauptmerkmale von LongCat Image Text zu Bild#
- Quadratische Erzeugung zuerst: Die Standardeinstellung ist für 1:1 Ausgabe bei 1024x1024 abgestimmt.
- Kompaktes Workflow-Design: Das Diagramm bleibt auf Aufforderung-zu-Bild-Erzeugung fokussiert, ohne zusätzliche Routing-Komplexität.
- Flexibles Auffordern: Geeignet für sowohl englische als auch chinesische Textaufforderungen.
- Einfache Qualitätseinstellung: Beginnen Sie mit der Standard-20-Schritte-Einstellung und erhöhen Sie die Schritte, wenn Sie eine langsamere, aber bewusstere Probenahme wünschen.
Wie man LongCat Image in ComfyUI verwendet#
- Wählen Sie die Ausgabengröße
- Verwenden Sie den
Resolution Selector-Knoten, um das standardmäßige quadratische Layout beizubehalten oder die Ziel-Megapixel anzupassen, falls erforderlich.
- Verwenden Sie den
- Schreiben Sie Ihre Aufforderung
- Öffnen Sie das
Text to Image (LongCat Image)-Unterdiagramm und ersetzen Sie die Standardaufforderung durch Ihre eigenen Anweisungen zu Thema, Beleuchtung, Stimmung und Komposition.
- Öffnen Sie das
- Führen Sie den Workflow aus
- Stellen Sie das Diagramm in die Warteschlange, um ein einzelnes Bild aus Ihrer Aufforderung zu erzeugen.
- Speichern Sie das Ergebnis
- Der
Save Image-Knoten schreibt die endgültige Ausgabe, sobald der Lauf abgeschlossen ist.
- Der
Tipps und Einstellungen#
- Die aktuelle Standardeinstellung läuft bei 20 Schritten mit CFG 4.
- Wenn Sie mit der ursprünglichen Empfehlung aus dem Quell-Workflow vergleichen möchten, versuchen Sie 50 Schritte.
- Klare, konkrete Aufforderungen funktionieren in diesem kompakten Diagramm besser als breite oder abstrakte Aufforderungsfragmente.
Ressourcen#
- Workflow-Quelle: Comfy.org workflow page
- Offizielles Modell: meituan-longcat/LongCat-Image on Hugging Face
