
Gemma 4 Textgenerierung ComfyUI-Workflow: multimodaler Text mit Bild-, Video- und Audiokontext#
Dieser Gemma 4 Textgenerierung ComfyUI-Workflow ist eine kompakte, RunComfy-bereite Vorlage, die hochwertigen Text generiert und dabei Bilder und Audio versteht, mit einem Video-Beispiel inklusive. Er ist für schnelle Iterationen auf multimodalen Eingaben, Produktbewertungssummen, Inhaltsanalysen und leichte Assistentenprototypen innerhalb von ComfyUI konzipiert.
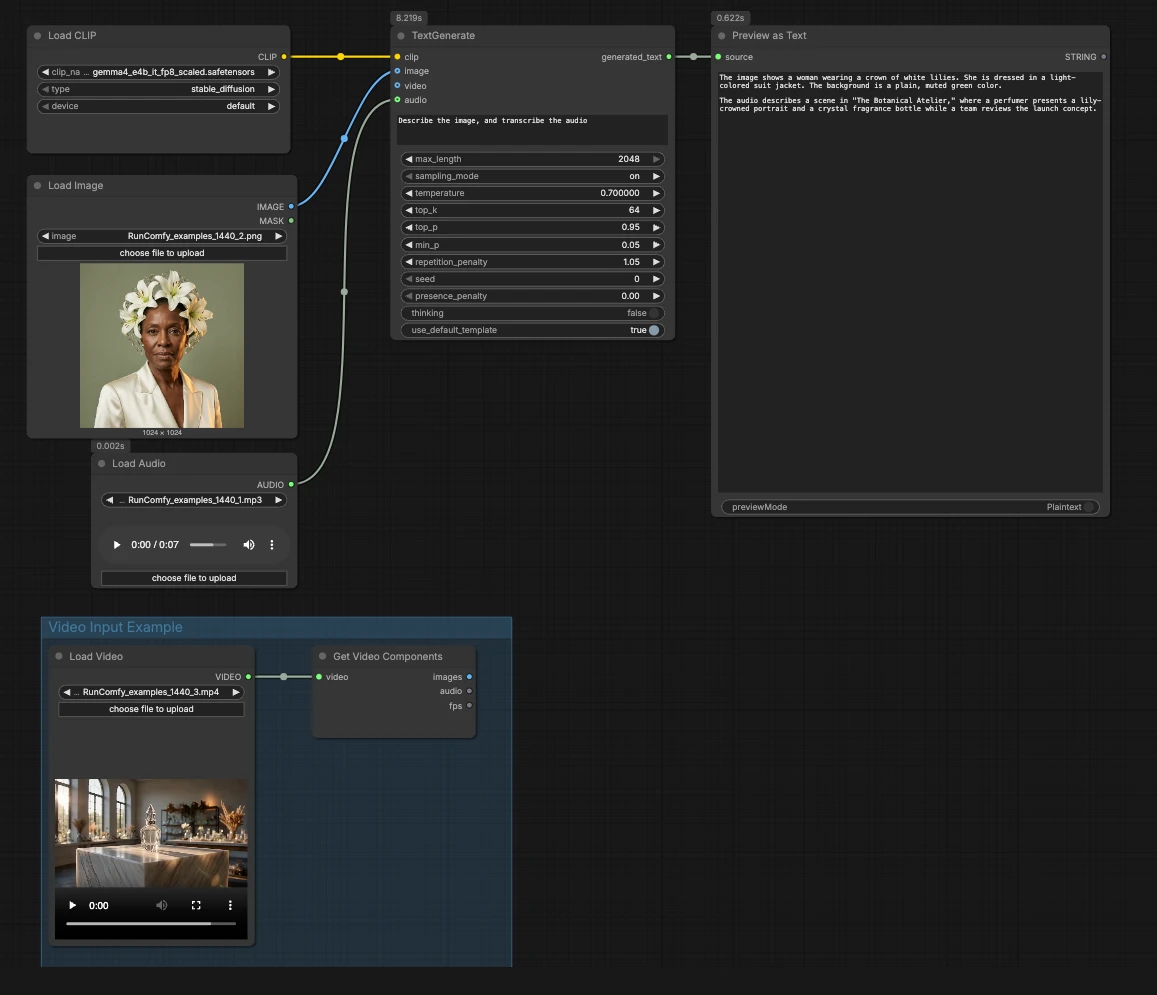
Der Graph verwendet ComfyUI’s native TextGenerate und CLIPLoader, um Gemma 4 E4B mit optionalen Bild-, Audio- und Videoeingaben auszuführen. Sie können es einfach für reine Textgenerierung halten oder Medien anhängen, um das Denkvermögen des Modells zu leiten und reichhaltigere Ausgaben zu erzeugen.
Schlüsselfunktionen im Comfyui Gemma 4 Textgenerierung ComfyUI-Workflow#
- Gemma 4 E4B Instruct Multimodal-Modell. Bietet Textgenerierung mit visuellem und auditivem Verständnis für prägnante Antworten, Zusammenfassungen und Analysen. Modell-Assets für ComfyUI sind unter dem Community-Paket Comfy-Org/gemma-4 organisiert.
- Gemma 4 E4B Text-Encoder (FP8 skaliert). Der Workflow lädt die verpackten Encoder-Gewichte
gemma4_e4b_it_fp8_scaled.safetensors, die die Sprach- und Multimodaleingaben desTextGenerate-Knotens unterstützen. Direkter Dateilink für lokale Benutzer: `text_encoders/gemma4_e4b_it_fp8_scaled.safetensors`.
Wie man den Comfyui Gemma 4 Textgenerierung ComfyUI-Workflow verwendet#
Gesamtlogik: Der Workflow lädt den Gemma 4 Encoder, akzeptiert optionale Medien und verwendet dann TextGenerate, um eine Antwort zu erzeugen, die in einer Vorschau angezeigt wird. Sie können es als reinen Text ausführen, ein Bild und Audio einstecken oder es auf Video erweitern, indem Sie die Beispielgruppe verbinden.
CLIPLoader(#3) Lädt den Gemma 4 E4B Text-Encoder, der vom Generator benötigt wird. Wenn Sie lokal arbeiten, wählen Siegemma4_e4b_it_fp8_scaled.safetensors, damit das Sprachmodell den richtigen Tokenizer und Multimodal-Encoder hat. In verwalteten Umgebungen ist die richtige Datei normalerweise vorausgewählt. Sie müssen hier nichts anpassen, sobald die gewählten Gewichte sichtbar sind.- Bildeingabe mit
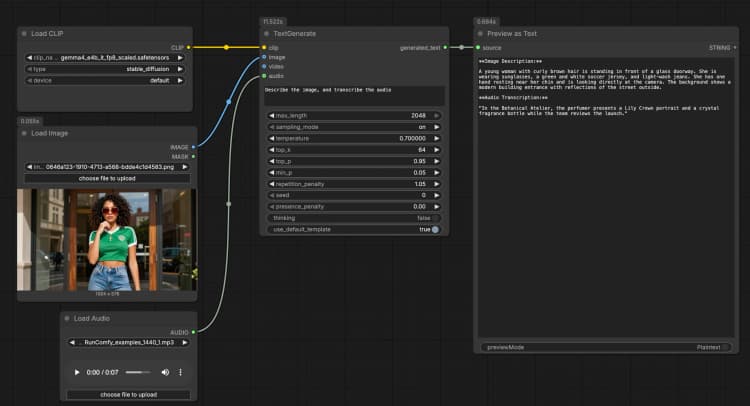
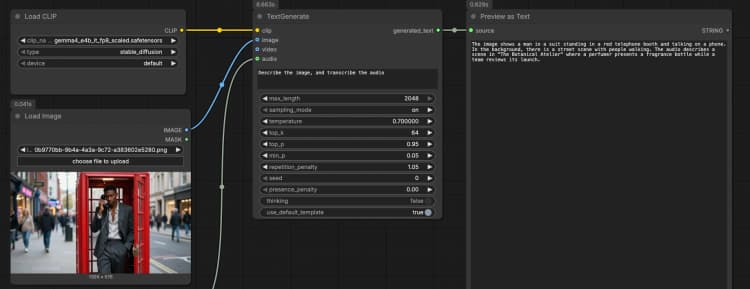
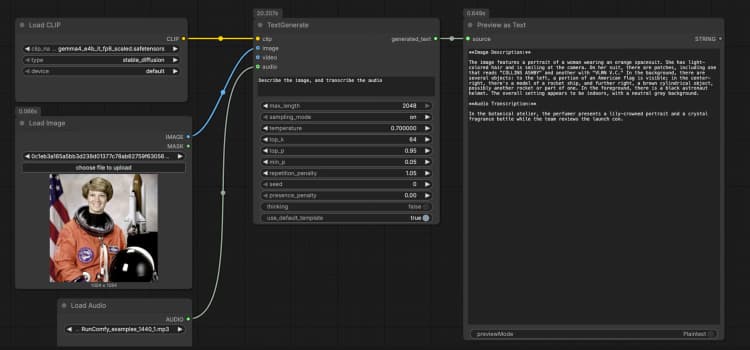
LoadImage(#2) Liefert ein einzelnes Referenzbild, das das Modell beschreiben, OCRen oder als Teil des Eingabeaufforderung analysieren kann. Tauschen Sie die Beispieldatei gegen Ihren eigenen Screenshot, Ihr Diagramm, Dokument oder Produktfoto aus. Das Bild wird direkt anTextGenerateübergeben, das die Antwort auf den visuellen Inhalt konditioniert. Wenn Sie ein reines Textverhalten wünschen, lassen Sie diesen Knoten unverbunden. - Audioeingabe mit
LoadAudio(#5) Fügt einen Audioclip für Transkription oder auditiv-bewusstes Denken hinzu. Ersetzen Sie die Beispieldatei durch eine Sprachnotiz, einen Meeting-Ausschnitt oder eine Bewertungsaufnahme. Der Audiostream wird anTextGenerategesendet, sodass Sie das Modell bitten können, es neben dem Bild zu transkribieren oder zusammenzufassen. Für reine Textaufgaben lassen Sie diesen Eingang leer. - Videoeingabe-Beispielgruppe Die „Videoeingabe-Beispielgruppe“ zeigt, wie man Video in denselben Ablauf bringt, indem
LoadVideo(#6) undGetVideoComponents(#7) verwendet wird.GetVideoComponentsstellt repräsentative Frames und den Soundtrack bereit, sodass Sie Szenen, Folien oder Text auf dem Bildschirm analysieren können. Um das Videoverstehen zu aktivieren, verbinden Sie denimages-Ausgang mit demimage-Eingang vonTextGenerateund denaudio-Ausgang mit dessenaudio-Eingang. Dies ermöglicht dem Gemma 4 Textgenerierung ComfyUI-Workflow, sowohl über Frames als auch über Sprache aus einem Clip nachzudenken. - Textgenerierung mit
TextGenerate(#1) Dies ist der Kernknoten, der Ihre Anweisung plus alle angehängten Medien akzeptiert und den generierten Text zurückgibt. Geben Sie eine klare Eingabeaufforderung wie „Beschreibe das Bild und transkribiere das Audio, dann schreibe eine 2-Satz-Zusammenfassung.“ Der Knoten kombiniert visuellen und auditiven Kontext automatisch, sodass Sie natürliche Anweisungen ohne Platzhalter schreiben können. Sie können Eingabeaufforderungen je nach Anwendungsfall gesprächig oder aufgabenorientiert halten. - Ergebnisanzeige mit
PreviewAny(#4) Zeigt den generierten Text an, sodass Sie ihn in Ihre Notizen oder nachgelagerte Tools kopieren können. Führen Sie es erneut aus, nachdem Sie die Eingabeaufforderung bearbeitet oder Medien ausgetauscht haben, um Ausgaben schnell zu vergleichen. Verwenden Sie diese Vorschau, um zu validieren, wie stark jede Modalität die Antwort beeinflusst.
Schlüssel-Knoten im Comfyui Gemma 4 Textgenerierung ComfyUI-Workflow#
TextGenerate(#1) Treibt die endgültige Ausgabe an und ist dort, wo die meisten Anpassungen stattfinden. Passen Sie an, wie lang die Antwort sein kann und wie explorativ sie sich anfühlen soll, indem Sie die maximalen Tokens und die Abtasttemperatur ändern. Aktivieren Sie den optionalen Denkmodus, wenn Sie mehr Schritt-für-Schritt-Denken vor der Antwort wünschen. Für Implementierungsdetails siehe den ComfyUI-Textgenerierungsknoten-Quellcode hier.CLIPLoader(#3) Wählt und lädt das Gemma 4 E4B Encoder-Paket, das für Text- und Multimodalverständnis benötigt wird. Wenn Sie Modelle lokal pflegen, platzieren Sie die Datei unter: ComfyUI/models/text_encoders/gemma4_e4b_it_fp8_scaled.safetensors Nach der Auswahl müssen Sie diesen Knoten selten erneut besuchen, es sei denn, Sie wechseln die Modellvarianten.GetVideoComponents(#7) Nützlich, wenn Sie möchten, dass das Modell Video berücksichtigt. Es stellt Frames und Audio bereit, sodass SieTextGenerateauf beide konditionieren können. Wenn Ihr Clip lang ist, wählen Sie eine kleinere Anzahl von Frames für schnellere Durchläufe; wenn Sie feinere Details benötigen, erhöhen Sie die Frame-Abtastung auf Kosten der Geschwindigkeit.
Optionale Extras#
- Beginnen Sie mit expliziten Anweisungen wie „Berücksichtigen Sie das angehängte Bild und Audio“, um die multimodale Verankerung offensichtlich zu machen.
- Fordern Sie bei Produktbewertungen Vor- und Nachteile sowie ein Ein-Satz-Urteil an, um Ausgaben strukturiert zu halten.
- Wenn Ihre Aufgabe rein textuell ist, trennen Sie Bild und Audio für schnellere Läufe.
- Um Experimente zu stapeln, duplizieren Sie den
TextGenerate-Knoten mit unterschiedlichen Eingabeaufforderungen und vergleichen Sie die Vorschauen nebeneinander. - Modell-Dateien und Varianten für Gemma 4 sind im Community-Paket organisiert; erkunden Sie verfügbare Assets hier: Comfy-Org/gemma-4.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Comfy-Org für das Gemma 4 ComfyUI-Modellpaket und den E4B Text-Encoder, Comfy-Org (ComfyUI-Wartungsteam) für den eingebauten TextGenerate-Knoten und Comfy.org für das offizielle Gemma 4-Tutorial und den Veröffentlichungsblog für ihre Beiträge und Pflege. Für autoritative Details beziehen Sie sich bitte auf die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- ComfyUI-Dokumentation/Gemma 4 ComfyUI-Workflow-Beispiel
- GitHub: Comfy-Org/ComfyUI
- Hugging Face: Comfy-Org/gemma-4
- Dokumentation / Veröffentlichungsnotizen: Gemma 4 ComfyUI-Workflow-Beispiel
- ComfyUI-Blog/Neue Open-Source-Modelle jetzt in ComfyUI: VOID, BiRefNet & Gemma 4
- GitHub: Comfy-Org/workflow_templates
- Hugging Face: Comfy-Org/gemma-4
- Dokumentation / Veröffentlichungsnotizen: Neue Open-Source-Modelle jetzt in ComfyUI: VOID, BiRefNet & Gemma 4
- Comfy-Org/gemma-4
- Hugging Face: Comfy-Org/gemma-4
- Comfy-Org/gemma-4 E4B Text-Encoder
- Hugging Face: Comfy-Org/gemma-4: gemma4_e4b_it_fp8_scaled.safetensors
- Comfy-Org/ComfyUI TextGenerate-Knoten
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.