
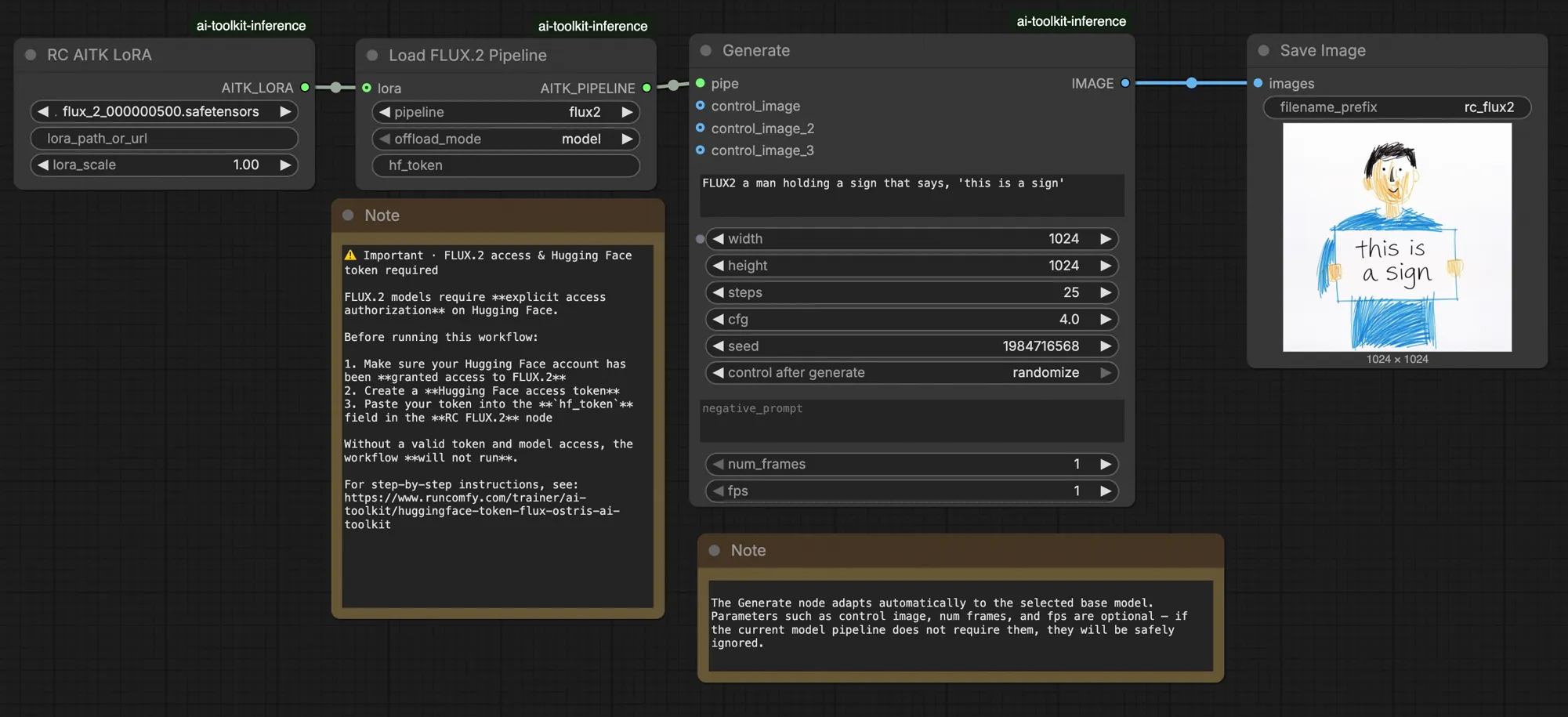
FLUX.2 LoRA ComfyUI Inferenz: training-übereinstimmende AI Toolkit LoRA Ausgabe mit der FLUX.2 Dev Pipeline#
Dieses produktionsbereite RunComfy Workflow führt FLUX.2 Dev LoRA Inferenz in ComfyUI durch RC FLUX.2 Dev (Flux2Pipeline) (Pipeline-Ebene, keine generische Sampler-Graph). RunComfy hat diesen benutzerdefinierten Knoten entwickelt und als Open-Source bereitgestellt—siehe die runcomfy-com Repositories—und Sie steuern die Adapteranwendung mit lora_path und lora_scale.
Hinweis: Dieses Workflow erfordert eine 3XL Maschine zum Ausführen.
Warum FLUX.2 LoRA ComfyUI Inferenz oft anders aussieht in ComfyUI#
AI Toolkit Training-Previews werden durch eine modellspezifische FLUX.2 Pipeline gerendert, in der Textkodierung, Planung und LoRA-Injektion zusammenarbeiten. In ComfyUI kann das Neuschaffen von FLUX.2 mit einem anderen Graph (oder einem anderen LoRA-Ladepfad) diese Interaktionen ändern, sodass das Kopieren derselben Eingabeaufforderung, Schritte, CFG und Seed immer noch sichtbare Abweichungen erzeugt. Die RunComfy RC Pipeline-Knoten schließen diese Lücke, indem sie FLUX.2 vollständig in Flux2Pipeline ausführen und Ihr LoRA innerhalb dieser Pipeline anwenden, um die Inferenz mit dem Vorschauverhalten abzustimmen. Quelle: RunComfy Open-Source Repositories.
Wie man das FLUX.2 LoRA ComfyUI Inferenz-Workflow verwendet#
Schritt 1: Holen Sie sich den LoRA-Pfad und laden Sie ihn in das Workflow (2 Optionen)#
⚠️ Wichtig · FLUX.2 Zugriff & Hugging Face Token erforderlich#
FLUX.2 Dev Modelle erfordern explizite Zugriffserlaubnis auf Hugging Face.
Bevor Sie dieses Workflow ausführen:
- Stellen Sie sicher, dass Ihrem Hugging Face-Konto Zugriff auf FLUX.2 (Dev) gewährt wurde
- Erstellen Sie einen Hugging Face Zugriffstoken
- Fügen Sie Ihren Token in das
hf_tokenFeld im Load Pipeline Knoten ein
Ohne einen gültigen Token und ordnungsgemäßen Modellzugriff wird das Workflow nicht ausgeführt. Für schrittweise Anleitungen siehe Hugging Face Token für FLUX.2.
Option A — RunComfy Trainingsergebnis → Download auf lokales ComfyUI:
- Gehen Sie zu Trainer → LoRA Assets
- Finden Sie das LoRA, das Sie verwenden möchten
- Klicken Sie auf das ⋮ (Drei-Punkte) Menü rechts → wählen Sie LoRA-Link kopieren
- Auf der ComfyUI Workflow-Seite, fügen Sie den kopierten Link in das Download Eingabefeld in der oberen rechten Ecke der Benutzeroberfläche ein
- Bevor Sie auf Download klicken, stellen Sie sicher, dass das Zielverzeichnis auf ComfyUI > models > loras eingestellt ist (dieses Verzeichnis muss als Downloadziel ausgewählt sein)
- Klicken Sie auf Download — dies stellt sicher, dass die LoRA-Datei im richtigen
models/lorasVerzeichnis gespeichert wird - Nachdem der Download abgeschlossen ist, aktualisieren Sie die Seite
- Die LoRA erscheint nun im LoRA-Auswahl Dropdown im Workflow — wählen Sie es aus

Option B — Direkte LoRA URL (überschreibt Option A):
- Fügen Sie die direkte
.safetensorsDownload URL in daspath / urlEingabefeld des LoRA-Knotens ein - Wenn hier eine URL bereitgestellt wird, überschreibt sie Option A — das Workflow lädt die LoRA direkt von der URL zur Laufzeit
- Kein lokaler Download oder Dateiablage ist erforderlich
Tipp: Bestätigen Sie, dass die URL auf die tatsächliche .safetensors Datei verweist (nicht auf eine Zielseite oder Weiterleitung).
Schritt 2: Passen Sie die Inferenzparameter an Ihre Trainingsmuster-Einstellungen an#
Wählen Sie im LoRA-Knoten Ihren Adapter in lora_path (Option A) oder fügen Sie einen direkten .safetensors Link in path / url ein (Option B überschreibt das Dropdown). Stellen Sie dann lora_scale auf die gleiche Stärke ein, die Sie während der Training-Previews verwendet haben, und passen Sie von dort aus an.
Verbleibende Parameter befinden sich auf dem Generate Knoten (und, abhängig vom Graph, dem Load Pipeline Knoten):
prompt: Ihre Texteingabeaufforderung (einschließlich Triggerwörter, falls Sie mit ihnen trainiert haben)width/height: Ausgabeauflösung; passen Sie Ihre Trainingsvorschaugröße für den saubersten Vergleich an (Vielfache von 16 werden für FLUX.2 empfohlen)sample_steps: Anzahl der Inferenzschritte (25 ist ein häufiger Standard)guidance_scale: CFG/Leitwert (4.0 ist ein häufiger Standard)seed: Fester Seed zur Reproduktion; ändern Sie ihn, um Variationen zu erkundenseed_mode(nur wenn vorhanden): wählen Siefixedoderrandomizenegative_prompt(nur wenn vorhanden): FLUX.2 wird in diesem Workflow leitungsgestillt, daher werden negative Eingabeaufforderungen ignorierthf_token: Hugging Face Zugriffstoken; erforderlich für FLUX.2 Dev Modell-Download (fügen Sie es im Load Pipeline Knoten ein)
Training-Ausrichtungstipp: Wenn Sie während des Trainings Sampling-Werte angepasst haben (seed, guidance_scale, sample_steps, Triggerwörter, Auflösung), spiegeln Sie diese genauen Werte hier wider. Wenn Sie auf RunComfy trainiert haben, öffnen Sie Trainer → LoRA Assets > Konfiguration, um das aufgelöste YAML anzuzeigen und die Vorschau/Sample-Einstellungen in die Workflow-Knoten zu kopieren.

Schritt 3: Führen Sie FLUX.2 LoRA ComfyUI Inferenz aus#
Klicken Sie auf Queue/Run — der SaveImage Knoten schreibt die Ergebnisse in Ihren ComfyUI Ausgabeordner.
Schnellcheckliste:
- ✓ LoRA ist entweder: heruntergeladen in
ComfyUI/models/loras(Option A), oder geladen über eine direkte.safetensorsURL (Option B) - ✓ Seite nach lokalem Download aktualisiert (nur Option A)
- ✓ Inferenzparameter stimmen mit der Training
sampleKonfiguration überein (wenn angepasst)
Wenn alles oben Genannte korrekt ist, sollten die Inferenz-Ergebnisse hier Ihren Trainings-Previews sehr nahe kommen.
Fehlerbehebung bei FLUX.2 LoRA ComfyUI Inferenz#
Die meisten FLUX.2 „Training-Preview vs ComfyUI Inferenz“ Lücken resultieren aus Pipeline-Ebenen-Unterschieden (wie das Modell geladen, geplant und wie das LoRA zusammengeführt wird), nicht aus einem einzigen falschen Knopf. Dieses RunComfy Workflow stellt die nächste „training-übereinstimmende“ Basislinie wieder her, indem es die Inferenz durch RC FLUX.2 Dev (Flux2Pipeline) vollständig ausführt und Ihr LoRA innerhalb dieser Pipeline über lora_path / lora_scale anwendet (anstatt generische Loader/Sampler-Knoten zu stapeln).
(1) Flux.2 mit Lora Fehler: "mul_cuda" nicht implementiert für 'Float8_e4m3fn'#
Warum das passiert Dies tritt typischerweise auf, wenn FLUX.2 mit Float8/FP8 Gewichten (oder quantisierter Mischpräzision) geladen wird und das LoRA durch einen generischen ComfyUI LoRA Pfad angewendet wird. Die LoRA-Zusammenführung kann nicht unterstützte Float8-Operationen (oder gemischte Float8 + BF16-Promotionen) erzwingen, was den mul_cuda Float8 Laufzeitfehler auslöst.
Wie man es behebt (empfohlen)
- Führen Sie die Inferenz durch RC FLUX.2 Dev (Flux2Pipeline) aus und laden Sie den Adapter nur über
lora_path/lora_scale, sodass die LoRA-Zusammenführung in der AI Toolkit-abgestimmten Pipeline stattfindet, nicht über einen generischen LoRA Loader, der oben gestapelt ist. - Wenn Sie in einem Nicht-RC-Graph debuggen: Vermeiden Sie das Anwenden eines LoRA auf Float8/FP8 Diffusionsgewichte. Verwenden Sie einen BF16/FP16-kompatiblen Ladepfad für FLUX.2, bevor Sie das LoRA hinzufügen.
(2) LoRA-Formanpassungen sollten schnell fehlschlagen, anstatt den GPU-Zustand zu beschädigen und OOM/Systeminstabilität zu verursachen#
Warum das passiert Dies ist fast immer ein Basis-Mismatch: Das LoRA wurde für eine andere Modellfamilie trainiert (zum Beispiel FLUX.1) wird aber auf FLUX.2 Dev angewendet. Sie sehen oft viele lora key not loaded Zeilen und dann Formanpassungen; im schlimmsten Fall kann die Sitzung instabil werden und in OOMs enden.
Wie man es behebt (empfohlen)
- Stellen Sie sicher, dass das LoRA speziell für
black-forest-labs/FLUX.2-devmit AI Toolkit trainiert wurde (FLUX.1 / FLUX.2 / Klein Varianten sind nicht austauschbar). - Halten Sie den Graph „einspurig“ für LoRA: Laden Sie den Adapter nur über den
lora_pathInput des Workflows und lassen Sie Flux2Pipeline die Zusammenführung übernehmen. Stapeln Sie keinen zusätzlichen generischen LoRA Loader parallel. - Wenn Sie bereits auf eine Nichtübereinstimmung gestoßen sind und ComfyUI anschließend nicht zusammenhängende CUDA/OOM-Fehler produziert, starten Sie den ComfyUI-Prozess neu, um den GPU + Modellzustand vollständig zurückzusetzen, und versuchen Sie es erneut mit einem kompatiblen LoRA.
(3) Flux.2 Dev - Die Verwendung von LoRAs verdoppelt die Inferenzzeit mehr als#
Warum das passiert Ein LoRA kann FLUX.2 Dev erheblich langsamer machen, wenn der LoRA-Pfad zusätzliche Patching/Dequantisierungsarbeit erzwingt oder Gewichte in einem langsameren Codepfad als das Basismodell allein anwendet.
Wie man es behebt (empfohlen)
- Verwenden Sie den RC FLUX.2 Dev (Flux2Pipeline) Pfad dieses Workflows und übergeben Sie Ihren Adapter über
lora_path/lora_scale. In dieser Konfiguration wird das LoRA einmal während des Pipeline-Ladevorgangs zusammengeführt (AI Toolkit-Stil), sodass die pro Schritt Sampling-Kosten nahe am Basismodell bleiben. - Wenn Sie ein zu den Previews passendes Verhalten anstreben, vermeiden Sie das Stapeln mehrerer LoRA Loader oder das Mischen von Ladepfaden. Halten Sie es bei einem
lora_path+ einemlora_scale, bis die Basislinie übereinstimmt.
Hinweis In diesem FLUX.2 Dev Workflow wird FLUX.2 leitungsgestillt, sodass negative_prompt möglicherweise von der Pipeline ignoriert wird, selbst wenn ein UI-Feld vorhanden ist—passen Sie Previews mit Eingabeaufforderungsformulierung + guidance_scale + lora_scale zuerst an.
Führen Sie jetzt FLUX.2 LoRA ComfyUI Inferenz aus#
Öffnen Sie das Workflow, setzen Sie lora_path, und klicken Sie auf Queue/Run, um FLUX.2 Dev LoRA-Ergebnisse zu erhalten, die nah an Ihren AI Toolkit Trainings-Previews bleiben.
