
Flex.1 LoRA-Inferenz: Führen Sie AI Toolkit LoRA in ComfyUI für Training-Abgestimmte Ergebnisse aus#
Flex.1 LoRA-Inferenz: training-abgestimmte, minimal-schrittige Generierung in ComfyUI. Flex.1 LoRA-Inferenz ist ein produktionsreifer RunComfy-Workflow zum Ausführen von AI Toolkit-trainierten Flex.1 LoRAs in ComfyUI mit training-abgestimmtem Verhalten. Es basiert auf RC Flex.1 (RCFlex1), das eine Flex.1-spezifische Inferenz-Pipeline umschließt (anstatt eines generischen Sampler-Graphs) und Ihre LoRA konsistent über lora_path und lora_scale anwendet; RunComfy hat diesen Knoten entwickelt und open-sourced—sehen Sie den Code in den runcomfy-com GitHub-Organisations-Repositories.
Verwenden Sie es, wenn Ihre LoRA-Inferenz anders aussieht als das Training—zum Beispiel sehen AI Toolkit-Vorschauen richtig aus, aber die gleiche LoRA + Prompt fühlt sich anders an, sobald Sie zu ComfyUI wechseln.
Warum Flex.1 LoRA-Inferenz in ComfyUI oft anders aussieht & Was der RCFlex1-Benutzerdefinierte Knoten tut#
AI Toolkit-Vorschauen stammen aus einer Flex.1-spezifischen Inferenz-Pipeline. Viele ComfyUI-Graphen rekonstruieren den Stack aus generischen Ladern und Samplern, sodass „die Zahlen abgleichen“ (Prompt/Schritte/CFG/Seed) nicht immer ausreicht—Unterschiede in der Pipeline können Standards ändern und wo/wie die LoRA angewendet wird.
RCFlex1 leitet die Inferenz durch einen Flex.1-spezifischen Pipeline-Wrapper, der mit AI Toolkit-Vorschauen übereinstimmt, und hält die LoRA-Injektion konsistent für Flex.1. Referenzimplementierung: `src/pipelines/flex1_alpha.py`
Wie man den Flex.1 LoRA-Inferenz-Workflow verwendet#
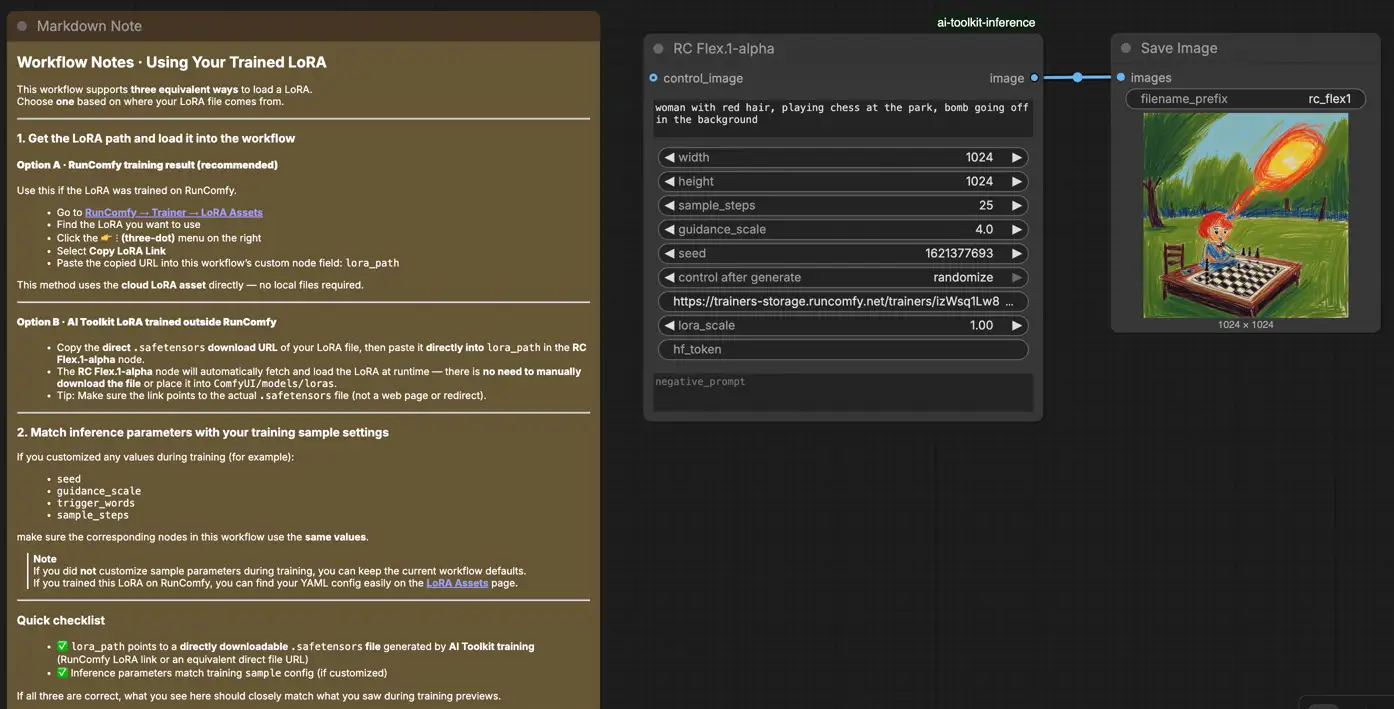
Schritt 1: Öffnen Sie den Workflow#
Öffnen Sie den RunComfy Flex.1 LoRA-Inferenz-Workflow in ComfyUI.
Schritt 2: Importieren Sie Ihre LoRA (2 Optionen)#
- Option A (RunComfy-Trainingsergebnis): RunComfy → Trainer → LoRA Assets → finden Sie Ihre LoRA → ⋮ → LoRA-Link kopieren

- Option B (AI Toolkit LoRA außerhalb von RunComfy trainiert): Kopieren Sie einen direkten
.safetensorsDownload-Link für Ihre LoRA und fügen Sie diese URL inlora_pathein (kein Download inComfyUI/models/loraserforderlich).
Schritt 3: Konfigurieren Sie RCFlex1 für Flex.1 LoRA-Inferenz#
Im RCFlex1 Flex.1 LoRA-Inferenz-Knoten-UI stellen Sie die restlichen Parameter ein:
prompt: Ihr Haupttext-Prompt (einschließlich aller Trigger-Tokens, die Sie während des Trainings verwendet haben)negative_prompt: optional; lassen Sie es leer, wenn Sie keinen in der Vorschau-Sampling verwendet habenwidth/height: Ausgabeauflösungsample_steps: Sampling-Schritte (entsprechen Sie Ihren Vorschau-Einstellungen beim Vergleich der Ergebnisse)guidance_scale: CFG / Anleitung (entsprechen Sie Ihrem Vorschau-CFG)seed: Verwenden Sie einen festen Seed für Reproduzierbarkeit; ändern Sie ihn, um Variationen zu erkundenlora_scale: LoRA-Stärke/Intensität
Für training-abgestimmte Ergebnisse öffnen Sie Ihr AI Toolkit-Training-YAML und wenden Sie die gleichen Sampling-Werte hier an—insbesondere width, height, sample_steps, guidance_scale und seed. Wenn Sie bei RunComfy trainiert haben, öffnen Sie Trainer → LoRA Assets → Konfiguration und nutzen Sie die Vorschau/Sample-Werte erneut.

Schritt 4: Führen Sie Flex.1 LoRA-Inferenz aus#
- Klicken Sie auf Queue/Run → SaveImage schreibt die Ausgabe automatisch
Fehlerbehebung bei Flex.1 LoRA-Inferenz#
Die meisten „Training-Vorschau vs ComfyUI-Inferenz“-Abweichungen resultieren aus Pipeline-Unterschieden (nicht einem einzigen falschen Knopf). Der schnellste Weg, training-abgestimmte Ergebnisse wiederherzustellen, ist die Ausführung der Inferenz durch den RunComfy RC Flex.1 (RCFlex1) benutzerdefinierten Knoten, der Flex.1-Sampling + LoRA-Injektion auf Pipeline-Ebene mit AI Toolkit's Vorschau-Pipeline abstimmt.
(1) Warum sieht die Beispielvorschau in AI Toolkit großartig aus, aber der gleiche Prompt sieht in ComfyUI anders aus? Wie kann ich das in ComfyUI reproduzieren?#
Warum das passiert
Selbst mit demselben Prompt / Seed / Schritten können die Ergebnisse abweichen, wenn ComfyUI eine andere Inferenz-Pipeline als AI Toolkit's Vorschau-Pipeline verwendet. Bei Flex.1 speziell können Pipeline-Unterschiede Modellstandards und wo/wie die LoRA injiziert wird ändern, was sich als „gleicher Prompt, anderes Aussehen“ zeigt.
Wie man es behebt (empfohlen)
- Führen Sie die Inferenz mit RCFlex1 aus, um die Inferenz pipeline-abgestimmt mit AI Toolkit-Vorschauen zu halten (das ist der Haupthebel).
- Spiegeln Sie Ihre AI Toolkit-Vorschau-Sampling-Einstellungen:
width,height,sample_steps,guidance_scale,seed. - Verwenden Sie die gleichen Trigger-Wörter (wenn Sie mit ihnen trainiert haben) und halten Sie
lora_scalegleich wie Ihre Vorschau-Stärke.
(2) Wie man Flux LoRA in Flex mit Diffusers lädt#
Warum das passiert
Flex.1 hat sich von Flux entfernt, sodass „es wie eine normale Flux LoRA laden“ zu teilweiser Anwendung, schwacher Wirkung oder unerwartetem Verhalten führen kann—insbesondere wenn die LoRA nicht für Flex.1 trainiert wurde.
Wie man es behebt (am zuverlässigsten)
- Für AI Toolkit-trainierte Flex.1 LoRAs: Laden Sie über
lora_pathin RCFlex1, sodass die LoRA-Injektion innerhalb der abgestimmten Flex.1-Inferenz-Pipeline erfolgt. - Wenn die LoRA für ein anderes Basismodell trainiert wurde, erwarten Sie keinen perfekten Transfer—trainieren Sie die LoRA in AI Toolkit für Flex.1 neu für die saubersten Ergebnisse.
(3) Flux' Objekt hat kein Attribut 'process_timestep#
Warum das passiert
Dies weist normalerweise auf eine Unstimmigkeit zwischen den Knoten/Code, die Sie ausführen, und dem Modell/Pipeline, das Sie ausführen sollten (Versionsabweichung, falsches Knotenset oder inkompatible Flex/Flux-Tools mischen).
Wie man es behebt
- Bevorzugen Sie die Ausführung von Flex.1-Inferenz durch RCFlex1, das den Ausführungspfad im beabsichtigten Flex.1-Pipeline-Wrapper hält.
- Wenn Sie ComfyUI oder benutzerdefinierte Knoten kürzlich aktualisiert haben, aktualisieren Sie die verwandten Knoten und starten Sie ComfyUI neu, um veraltete Importe/Caches zu löschen.
- Überprüfen Sie, ob Sie tatsächlich Flex.1 als Basismodell für diesen Workflow laden (nicht eine andere Flux-Variante).
Führen Sie jetzt Flex.1 LoRA-Inferenz aus#
Öffnen Sie den RunComfy Flex.1 LoRA-Inferenz-Workflow, fügen Sie Ihre LoRA in lora_path ein und führen Sie RCFlex1 für training-abgestimmte Flex.1 LoRA-Inferenz in ComfyUI aus.