
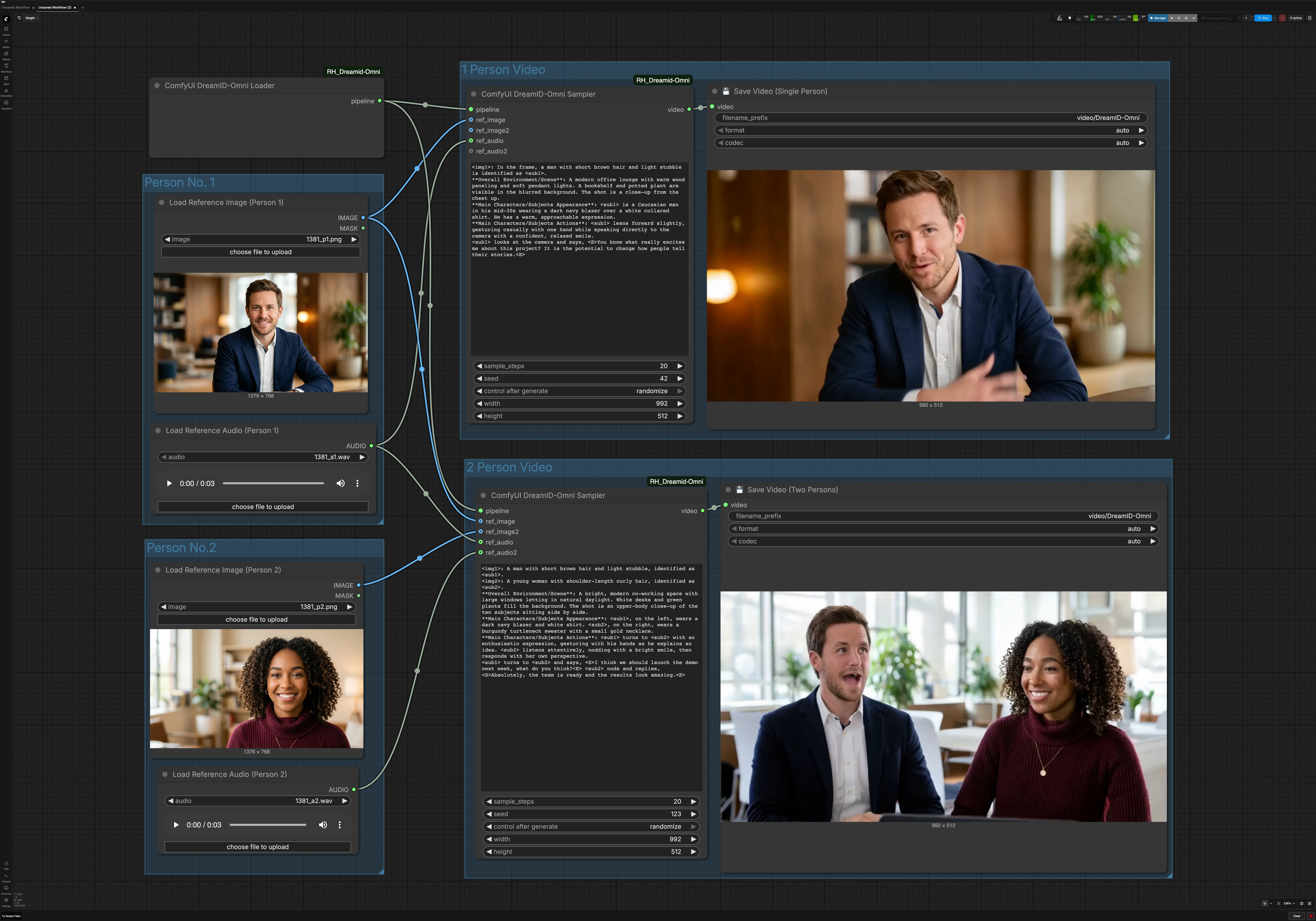
DreamID-Omni Ein- und Zwei-Personen-Charakter sprechender Video-Workflow für ComfyUI#
Dieser Workflow verwandelt ein einzelnes Referenzfoto und einen Audioclip in ein identitätsbewahrendes sprechendes Kopf-Video. Angetrieben durch das DreamID-Omni-Modell, kombiniert es ein modernes Video-Rückgrat mit MMAudio-gesteuerter Lippenbewegung, sodass das Subjekt natürlich spricht, während es das Gesicht aus Ihrem Bild beibehält. Es unterstützt auch zwei Charaktere und ermöglicht nebeneinander liegende Gesprächsclips, die von zwei Stimmen gesteuert werden.
Entwickelt für Kreative, Produktteams und Forscher, ist der DreamID-Omni-Workflow in ComfyUI ideal für digitale Avatare, personalisierte Ankündigungen, Tutorial-Intros und AI-Dialog-Szenen. Sie liefern Fotos und Audio, beschreiben optional die Aufnahme in einem kurzen Prompt, und der Graph rendert ein poliertes Video, das bereit zum Teilen ist.
Wichtige Modelle im ComfyUI DreamID-Omni-Workflow#
- DreamID-Omni. Das Kern-Identitätsmodul, das die Person in Ihrem Referenzbild über die Frames hinweg bewahrt, während es auf Audio für realistische Lippenbewegungen reagiert. Siehe das offizielle Repo und die Gewichte für Details: DreamID-Omni und DreamID-Omni auf Hugging Face.
- Wan 2.2 Video-Generierung. Ein hochkapazitives Video-Diffusions-Rückgrat, das kohärente Bewegung, Beleuchtung und Shot-Komposition synthetisiert, während DreamID-Omni die Gesichtsidentität steuert.
- MMAudio. Ein Audio-Darstellungsmodell, das die Mundformen und subtilen Gesichtshinweise mit der gelieferten Sprache ausrichtet und die Lippen-Synchronisation verbessert.
So verwenden Sie den ComfyUI DreamID-Omni-Workflow#
Dieser Graph hat zwei parallele Pfade. Der Ein-Personen-Pfad verwendet ein Bild und ein Audio. Der Zwei-Personen-Pfad verwendet zwei Bilder und zwei Audios, um einen Gesprächsclip zu erstellen. Ein geteilter DreamID-Omni-Loader initialisiert die Pipeline für beide.
Person Nr. 1#
Verwenden Sie Load Reference Image (Person 1) (#6), um ein klares, frontal ausgerichtetes Porträt mit gleichmäßiger Beleuchtung und minimaler Verdeckung auszuwählen. Verwenden Sie Load Reference Audio (Person 1) (#7), um die Rede bereitzustellen, die der Charakter sagen soll. Sauberer Audio sorgt für bessere Lippen-Synchronisation, daher bevorzugen Sie Sprache ohne Musik oder starken Hintergrundlärm. Dieses Paar füttert sowohl den Ein-Personen-Modus als auch, wenn aktiviert, das linke oder erste Subjekt im Zwei-Personen-Modus.
Person Nr. 2#
Verwenden Sie Load Reference Image (Person 2) (#9) und Load Reference Audio (Person 2) (#11), wenn Sie einen Dialog erstellen. Wählen Sie ein Foto, das dem Framing von Person 1 entspricht, um die Komposition ausgeglichen zu halten. Stellen Sie sicher, dass das zweite Audio in der Lautstärke dem ersten ähnlich ist, um abrupte Wahrnehmungsverschiebungen zu vermeiden. Wenn Sie nur einen Ein-Personen-Clip erstellen, können Sie diese Gruppe ignorieren.
1 Person Video#
Der Ein-Sprecher-Pfad wird von ComfyUI DreamID-Omni Sampler (#21) angetrieben. Es fusioniert die DreamID-Omni-Pipeline mit dem Foto und Audio von Person 1 und rendert dann einen Shot, der mit Ihrer kurzen Szenenbeschreibung im Prompt-Bereich des Knotens konsistent ist. Halten Sie Ihren Prompt prägnant und praktisch, zum Beispiel indem Sie Hintergrund, Kameradistanz und Verhalten beschreiben. Das Ergebnis wird von 💾 Save Video (Single Person) (#4) geschrieben, das die Datei für Sie benennt und exportiert.
2 Person Video#
Der Dialog-Pfad verwendet ComfyUI DreamID-Omni Sampler (#22), um zwei Identitäten in einem Frame zu komponieren und jeden Mund mit seinem gepaarten Audio zu steuern. Geben Sie einen kurzen Prompt, um die Umgebung und den Interaktionsstil festzulegen, wie z.B. einen Co-Working-Bereich, einen lässigen Ton oder wer zuerst spricht. Dies hilft, die Kameraplatzierung und Gesten zu stabilisieren, während DreamID-Omni und MMAudio Identität und Lippenausrichtung beibehalten. Der Clip wird von 💾 Save Video (Two Persons) (#5) exportiert.
Geteilte DreamID-Omni-Pipeline#
ComfyUI DreamID-Omni Loader (#23) initialisiert die DreamID-Omni-Komponenten, die von beiden Pfaden verwendet werden. Normalerweise müssen Sie hier nichts anpassen. Solange die Gewichte und der ComfyUI-Knoten verfügbar sind, bereitet der Loader die Pipeline vor, damit die Sampler rendern können.
Wichtige Knoten im ComfyUI DreamID-Omni-Workflow#
ComfyUI DreamID-Omni Loader (#23)#
Initialisiert die DreamID-Omni-Pipeline und macht ihre Gewichte für nachgelagerte Sampler verfügbar. Hier gibt es keine typischen Benutzereingaben. Wenn Sie mehrere Modellvarianten pflegen, bestätigen Sie, dass die richtigen Gewichte installiert sind, bevor Sie Renders in die Warteschlange stellen.
ComfyUI DreamID-Omni Sampler (#21)#
Ein-Personen-Rendering. Dieser Knoten kombiniert die Loader-Pipeline mit dem ersten Referenzbild und Audio, um einen identitätsbewahrenden sprechenden Kopf zu synthetisieren. Das Prompt-Feld ist der Ort, an dem Sie die Szene und das Verhalten definieren; der Seed steuert die Wiederholbarkeit; die Auflösung bestimmt das Framing und die Gesichtsdetaillierung; und die Schritte tauschen Geschwindigkeit gegen Treue ein. Für konsistente Ergebnisse über Takes hinweg, verwenden Sie denselben Seed und halten Sie Änderungen am Prompt minimal.
ComfyUI DreamID-Omni Sampler (#22)#
Zwei-Personen-Rendering. Diese Instanz akzeptiert zwei Fotos und zwei Audios, wobei jede Stimme ihrem Subjekt für synchronisierte Lippenbewegung zugeordnet wird. Der Prompt kann das Gespräch und das Kameralayout inszenieren. Passen Sie Seed und Auflösung so an, wie Sie es im Ein-Personen-Modus tun würden, und stellen Sie sicher, dass beide Audios auf das gewünschte Timing zugeschnitten sind, bevor Sie rendern.
💾 Save Video (Single Person) (#4)#
Schreibt die Ein-Sprecher-Ausgabe auf die Festplatte. Stellen Sie den Ordner oder den Basisnamen ein, um Versionen organisiert zu halten. Wenn verfügbar, lassen Sie Codec- und Framerate-Optionen auf automatisch, wenn Sie unsicher sind.
💾 Save Video (Two Persons) (#5)#
Schreibt die Dialogausgabe auf die Festplatte. Verwenden Sie einen eindeutigen Basisnamen, damit Ein- und Zwei-Personen-Clips leicht zu unterscheiden sind. Behalten Sie automatische Exporteinstellungen für Zuverlässigkeit bei, es sei denn, Sie haben eine spezielle Lieferanforderung.
Optionale Extras#
- Halten Sie die Gesichter in den Referenzbildern groß genug, um einen bedeutenden Teil des Rahmens zu belegen, für eine stärkere Identitätssperre.
- Verwenden Sie sauberes, gut ausgesteuertes Sprach-Audio. Schneiden Sie Stille am Anfang ab, um anfänglich eingefrorene Lippen zu vermeiden.
- Für ein stabileres Aussehen, verwenden Sie denselben Seed, wenn Sie Prompts oder Outfits iterieren.
- Wenn der Zwei-Personen-Abstand eng erscheint, formulieren Sie den Prompt um, um die Kamera zu erweitern oder den Schulterraum zu vergrößern, anstatt Gesichter zu beschneiden.
- Für Assets und Updates siehe das offizielle Modell und den Knoten: DreamID-Omni, ComfyUI_RH_Dreamid-Omni, und DreamID-Omni weights.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Werken und Ressourcen auf. Wir danken Guoxu1233 für das DreamID-Omni-Modell/Workflow, HM-RunningHub für den DreamID-Omni ComfyUI-Knoten und XuGuo699 für die DreamID-Omni-Modellgewichte für ihre Beiträge und Pflege. Für autoritative Details, beziehen Sie sich bitte auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- DreamID-Omni Offizielles Repository - https://github.com/Guoxu1233/DreamID-Omni
- GitHub: Guoxu1233/DreamID-Omni
- DreamID-Omni ComfyUI Node (RunningHub) - https://github.com/HM-RunningHub/ComfyUI_RH_Dreamid-Omni
- DreamID-Omni Model Weights (Hugging Face) - https://huggingface.co/XuGuo699/DreamID-Omni
- Hugging Face: XuGuo699/DreamID-Omni
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Pfleger.
