
Steuerbare Animation im KI-Video: WanVideo + TTM Bewegungssteuerungs-Workflow für ComfyUI#
Dieser Workflow von mickmumpitz bringt Steuerbare Animation im KI-Video zu ComfyUI, indem er einen trainingsfreien, bewegungsgeführten Ansatz verwendet. Er kombiniert WanVideo’s Bild-zu-Video-Diffusion mit Time-to-Move (TTM) latenter Führung und regionsbewussten Masken, sodass Sie steuern können, wie sich Subjekte bewegen, während Identität, Textur und Szenenkontinuität erhalten bleiben.
Sie können von einer Videoplatte oder von zwei Schlüsselbildern aus starten, Regionsmasken hinzufügen, die die Bewegung dort fokussieren, wo Sie es möchten, und Trajektorien ohne Feinabstimmung steuern. Das Ergebnis ist präzise, wiederholbare Steuerbare Animation im KI-Video, geeignet für gerichtete Aufnahmen, Objektbewegungssequenzen und benutzerdefinierte kreative Bearbeitungen.
Schlüsselmodelle im ComfyUI Steuerbare Animation im KI-Video Workflow#
- Wan2.2 I2V A14B (HIGH/LOW). Das Kernmodell der Bild-zu-Video-Diffusion, das Bewegung und zeitliche Kohärenz aus Eingabeaufforderungen und visuellen Referenzen synthetisiert. Zwei Varianten balancieren Treue (HIGH) und Agilität (LOW) für unterschiedliche Bewegungsintensitäten. Modelldateien sind in den Community WanVideo Sammlungen auf Hugging Face gehostet, z. B. Kijai’s WanVideo Verteilungen. Links: Kijai/WanVideo_comfy_fp8_scaled, Kijai/WanVideo_comfy
- Lightx2v I2V LoRA. Ein leichter Adapter, der die Struktur und Bewegungskonsistenz beim Komponieren der Steuerbaren Animation im KI-Video mit Wan2.2 strafft. Er hilft, die Geometrie des Subjekts unter stärkeren Bewegungshinweisen zu erhalten. Link: Kijai/WanVideo_comfy – Lightx2v LoRA
- Wan2.1 VAE. Der Video-Autoencoder, der Frames in Latenzen kodiert und die Ausgaben des Samplers zurück zu Bildern dekodiert, ohne Details zu opfern. Link: Kijai/WanVideo_comfy – Wan2_1_VAE_bf16.safetensors
- UMT5-XXL Text-Encoder. Bietet reichhaltige Texteingebungen für eingabeaufforderungsgesteuerte Kontrolle neben Bewegungshinweisen. Links: google/umt5-xxl, Kijai/WanVideo_comfy – encoder weights
- Segment Anything Modelle für Videomasken. SAM3 und SAM2 erstellen und verbreiten Regionsmasken über Frames hinweg, wodurch regionsabhängige Führung ermöglicht wird, die die Steuerbare Animation im KI-Video dort schärft, wo es zählt. Links: facebook/sam3, facebook/sam2
- Qwen-Image-Edit 2509 (optional). Ein Bildbearbeitungsfundament und ein blitzschnelles LoRA für schnelle Start-/Endframe-Bereinigung oder Objektentfernung vor der Animation. Links: QuantStack/Qwen-Image-Edit-2509-GGUF, lightx2v/Qwen-Image-Lightning, Comfy-Org/Qwen-Image_ComfyUI
- Time-to-Move (TTM) Führung. Der Workflow integriert TTM-Latenzen, um Trajektorienkontrolle auf trainingsfreie Weise in die Steuerbare Animation im KI-Video zu injizieren. Link: time-to-move/TTM
Wie man den ComfyUI Steuerbare Animation im KI-Video Workflow verwendet#
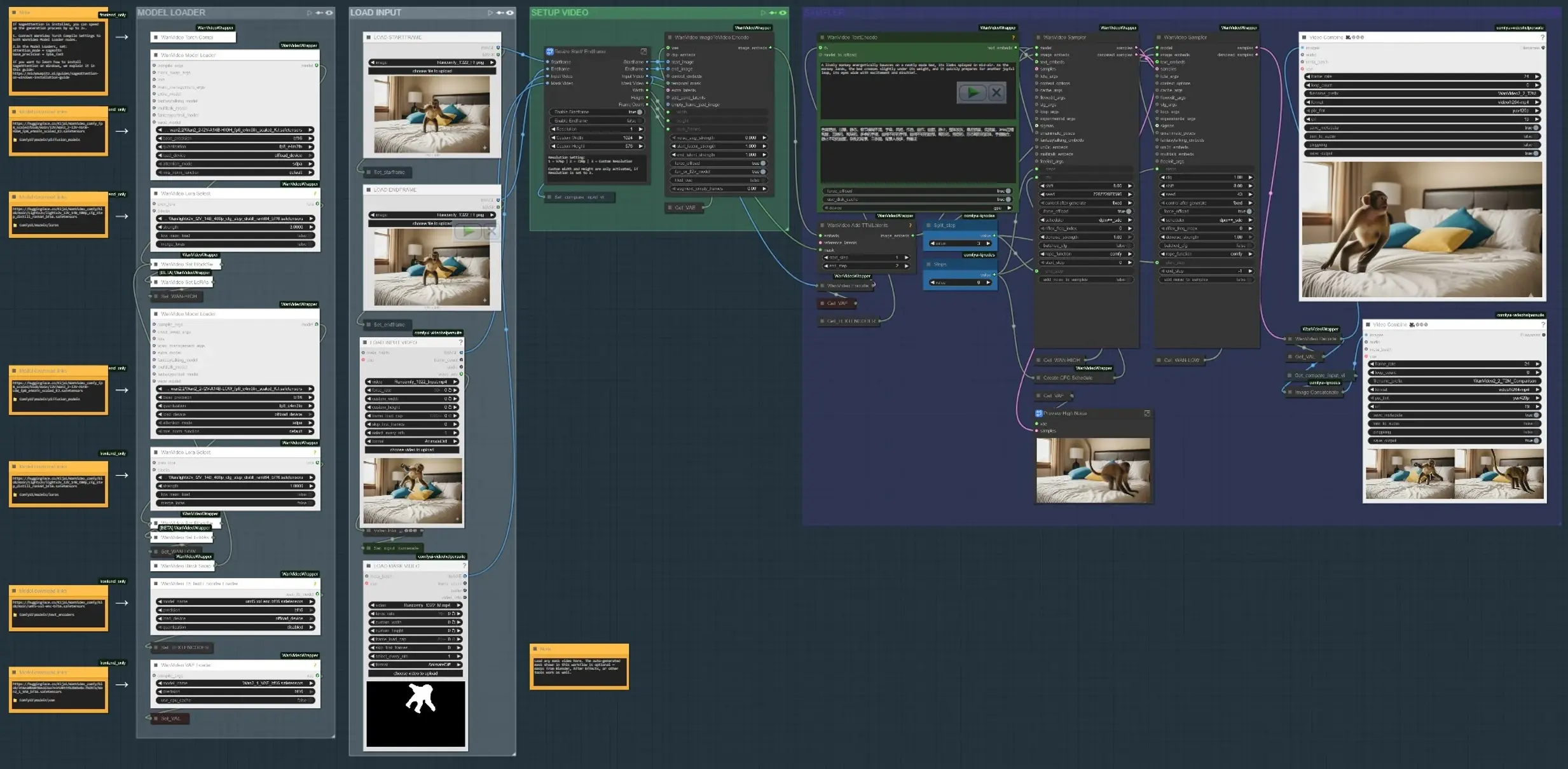
Der Workflow läuft in vier Hauptphasen: Eingaben laden, definieren, wo Bewegung stattfinden soll, Text- und Bewegungshinweise kodieren, dann das Ergebnis synthetisieren und überprüfen. Jede Gruppe unten korrespondiert mit einem beschrifteten Abschnitt im Diagramm.
- EINGABEN LADEN Verwenden Sie die Gruppe “EINGABEN VIDEO LADEN”, um eine Platte oder einen Referenzclip zu laden oder Start- und End-Schlüsselbilder zu laden, wenn Sie Bewegung zwischen zwei Zuständen erstellen. Der Subgraph “Start-/Endframe anpassen” normalisiert die Dimensionen und ermöglicht optional Start- und Endframe-Gating. Ein Nebeneinander-Vergleichsbilderzeuger erstellt einen Ausgang, der Eingabe versus Ergebnis für eine schnelle Überprüfung zeigt (
VHS_VideoCombine(#613)). - MODELLLADER Die Gruppe “MODELLLADER” richtet Wan2.2 I2V (HIGH/LOW) ein und wendet das Lightx2v LoRA an. Ein Blockaustauschpfad mischt Varianten für einen guten Treue-Bewegung-Kompromiss vor dem Sampling. Der Wan VAE wird einmal geladen und über Kodierung/Dekodierung geteilt. Die Textkodierung verwendet UMT5-XXL für starke Eingabeaufforderungs-Konditionierung in der Steuerbaren Animation im KI-Video.
- SAM3/SAM2 MASKE SUBJEKT In “SAM3 MASKE SUBJEKT” oder “SAM2 MASKE SUBJEKT”, klicken Sie auf einen Referenzframe, fügen Sie positive und negative Punkte hinzu und verbreiten Sie Masken über den Clip. Dies ergibt zeitlich konsistente Masken, die Bewegungseingriffe auf das von Ihnen gewählte Subjekt oder die Region beschränken, wodurch regionsabhängige Führung ermöglicht wird. Sie können auch umgehen und Ihr eigenes Maskenvideo laden; Masken aus Blender/After Effects funktionieren gut, wenn Sie künstlerisch gezeichnete Kontrolle wünschen.
- STARTFRAME/ENDFRAME VORBEREITUNG (optional) Die Gruppen “STARTFRAME – QWEN ENTFERNEN” und “ENDFRAME – QWEN ENTFERNEN” bieten einen optionalen Bereinigungsschritt für spezifische Frames mit Qwen-Image-Edit. Verwenden Sie sie, um Rigging, Stöcke oder Plattenartefakte zu entfernen, die ansonsten Bewegungshinweise verschmutzen würden. Inpainting schneidet und näht die Bearbeitung zurück in den Vollframe für eine saubere Basis.
- TEXT + BEWEGUNG KODIEREN Eingabeaufforderungen werden mit UMT5-XXL in
WanVideoTextEncode(#605) kodiert. Start-/Endframe-Bilder werden in Videolatenzen inWanVideoImageToVideoEncode(#89) transformiert. TTM-Bewegungslatenzen und eine optionale zeitliche Maske werden überWanVideoAddTTMLatents(#104) zusammengeführt, sodass der Sampler sowohl semantische (Text) als auch Trajektorien-Hinweise erhält, zentral für die Steuerbare Animation im KI-Video. - SAMPLER UND VORSCHAU Der Wan-Sampler (
WanVideoSampler(#27) undWanVideoSampler(#90)) entstört Latenzen mit einem dualen Takt-Setup: Ein Pfad steuert globale Dynamik, während der andere das lokale Erscheinungsbild erhält. Schritte und ein konfigurierbarer CFG-Zeitplan formen Bewegungsintensität versus Treue. Das Ergebnis wird in Frames dekodiert und als Video gespeichert; ein Vergleichsausgang hilft zu beurteilen, ob Ihre Steuerbare Animation im KI-Video dem Auftrag entspricht.
Schlüssel-Knoten im ComfyUI Steuerbare Animation im KI-Video Workflow#
WanVideoImageToVideoEncode(#89) Kodiert Start-/Endframe-Bilder in Videolatenzen, die die Bewegungssynthese initiieren. Passen Sie nur an, wenn Sie die Basisauflösung oder die Bildanzahl ändern; halten Sie diese mit Ihrer Eingabe abgestimmt, um Streckungen zu vermeiden. Wenn Sie ein Maskenvideo verwenden, stellen Sie sicher, dass dessen Dimensionen mit der kodierten Latenzgröße übereinstimmen.WanVideoAddTTMLatents(#104) Verschmilzt TTM-Bewegungslatenzen und zeitliche Masken in den Steuerstrom. Schalten Sie den Maskeneingang um, um die Bewegung auf Ihr Subjekt zu beschränken; wenn leer gelassen, wird die Bewegung global angewendet. Verwenden Sie dies, wenn Sie Trajektorien-spezifische Steuerbare Animation im KI-Video ohne Beeinträchtigung des Hintergrunds wünschen.SAM3VideoSegmentation(#687) Sammeln Sie einige positive und negative Punkte, wählen Sie einen Spur-Frame und verbreiten Sie sie über den Clip. Verwenden Sie die Visualisierungs-Ausgabe, um Maskenverschiebung vor dem Sampling zu validieren. Für datenschutzsensible oder Offline-Workflows wechseln Sie zur SAM2-Gruppe, die keine Modell-Gating erfordert.WanVideoSampler(#27) Der Entstörer, der Bewegung und Identität ausbalanciert. Kombinieren Sie “Schritte” mit der CFG-Zeitplanliste, um die Bewegungsstärke zu erhöhen oder zu entspannen; übermäßige Stärke kann das Erscheinungsbild überlagern, während zu wenig die Bewegung unterliefert. Wenn Masken aktiv sind, konzentriert sich der Sampler auf Updates innerhalb der Region, was die Stabilität für die Steuerbare Animation im KI-Video verbessert.
Optionale Extras#
- Für schnelle Iterationen beginnen Sie mit dem LOW Wan2.2 Modell, stellen Sie die Bewegung mit TTM ein und wechseln Sie dann zu HIGH für den letzten Durchgang, um die Textur wiederherzustellen.
- Verwenden Sie künstlerisch gezeichnete Maskenvideos für komplexe Silhouetten; der Lader akzeptiert externe Masken und wird sie passend skalieren.
- Die “Start-/Endframe”-Schalter ermöglichen es Ihnen, den ersten oder letzten Frame visuell zu sperren, nützlich für nahtlose Übergänge in längeren Bearbeitungen.
- Wenn in Ihrer Umgebung verfügbar, kann die Aktivierung optimierter Aufmerksamkeit (z. B. SageAttention) das Sampling erheblich beschleunigen.
- Passen Sie die Ausgabe-Bildrate im Kombinationsknoten an die Quelle an, um wahrgenommene Zeitunterschiede in der Steuerbaren Animation im KI-Video zu vermeiden.
Dieser Workflow liefert trainingsfreie, regionsbewusste Bewegungssteuerung, indem er Texteingaben, TTM-Latenzen und robuste Segmentierung kombiniert. Mit einigen gezielten Eingaben können Sie nuancierte, produktionsreife Steuerbare Animation im KI-Video steuern und dabei Subjekte modellgetreu und Szenen kohärent halten.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Mickmumpitz, dem Schöpfer der Steuerbaren Animation im KI-Video, für das Tutorial/Post, und dem time-to-move-Team für TTM für ihre Beiträge und Wartung. Für autoritative Details, beziehen Sie sich bitte auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Patreon/Controllable Animation in AI Video
- Docs / Release Notes: Mickmumpitz Patreon post
- time-to-move/TTM
- GitHub: time-to-move/TTM
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartungspersonen bereitgestellt werden.