
ComfyUI MOSS TTS: Text-zu-Sprache, Sprachklonen, SFX und Dialog in einem Arbeitsablauf#
Dieser ComfyUI MOSS TTS Arbeitsablauf verwandelt Text in lebhafte 24 kHz Sprache unter Verwendung der OpenMOSS MOSS-TTS Familie. Er umfasst schnelle Einzelsynthese, Zero-Shot Sprachklonen aus einem kurzen Referenzclip, beschreibendes Sprachdesign, prozedurale Soundeffekte und Multisprecher-Dialoge mit optionalen pro-Sprecher-Referenzen.
Basierend auf dem offiziellen MOSS-TTS Knoten-Stack und Modellfamilie, balanciert er Geschwindigkeit und Qualität. Der Local 1.7B Pfad ist die praktische schnelle Spur auf einer einzelnen GPU, während die größeren Delay 8B Modelle Geschwindigkeit für breitere Fähigkeiten und Ausdruckskraft eintauschen. Wenn Sie wiederverwendbare Eingabeaufforderungen, geklonte Stimmen oder Dialog in ComfyUI benötigen, ist dieser ComfyUI MOSS TTS Arbeitsablauf für Sie konzipiert.
Schlüsselmodelle im Comfyui ComfyUI MOSS TTS Arbeitsablauf#
- OpenMOSS MOSS-TTS Local 1.7B. Einzeln-GPU-freundlicher Text-zu-Sprache-Transformer, der schnelle, natürliche 24 kHz Sprache für alltägliche Produktionsarbeiten liefert. Modellkarte: MOSS-TTS-Local-Transformer.
- OpenMOSS MOSS-TTS Delay 8B. Eine größere Modelllinie, die Qualität, Sprecherähnlichkeit und Prosodie auf Kosten von Geschwindigkeit und Speicher betont. Modellkarte: MOSS-TTS.
- MOSS Audio Tokenizer. Der gelernte Codec, der Wellenformen und diskrete Token für die MOSS-TTS Modelle verbindet und hochauflösendes Decoding ermöglicht. Modellkarte: MOSS-Audio-Tokenizer.
Für Implementierungsdetails und Updates siehe die offiziellen Repositories: OpenMOSS/MOSS-TTS und den Knoten-Stack, der diesen Arbeitsablauf antreibt richservo/comfyui-moss-tts.
So verwenden Sie den Comfyui ComfyUI MOSS TTS Arbeitsablauf#
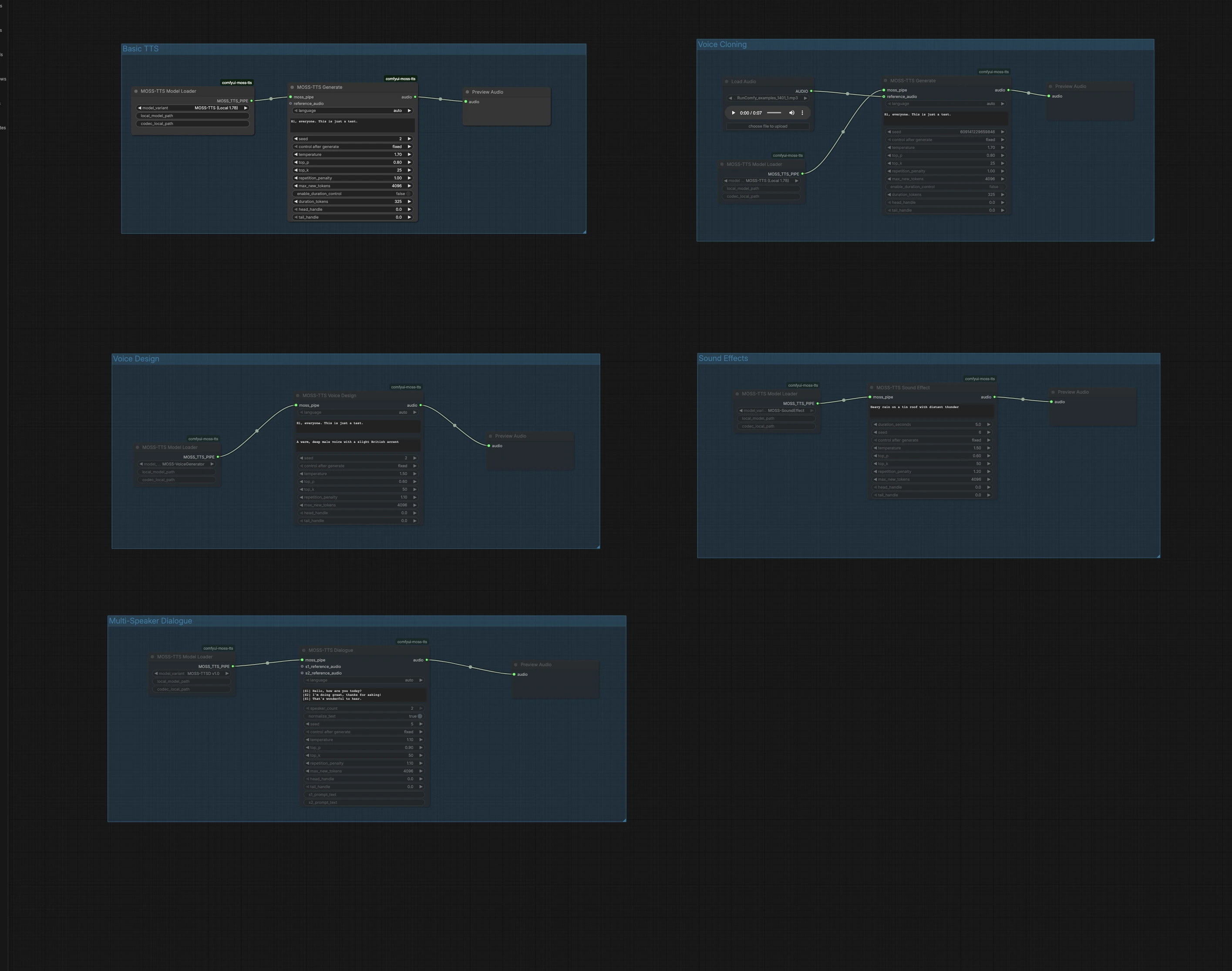
Dieses Diagramm ist in fünf unabhängige Gruppen organisiert. Wählen Sie die Gruppe, die Ihrem Ziel entspricht, führen Sie sie aus und hören Sie dann die Vorschau-Audio direkt auf der Leinwand. Sie können mehrere Gruppen parallel ausführen, um verschiedene Ansätze auszuprobieren.
Grundlegendes TTS#
Die grundlegende TTS-Gruppe wandelt einfachen Text in Sprache mit dem Local 1.7B schnellen Pfad um. Laden Sie das Modell in MossTTSModelLoader (#1), geben Sie Ihren Text an MossTTSGenerate (#2) weiter und hören Sie dann in PreviewAudio (#3). Der Generator konditioniert auf Ihre Eingabeaufforderung, um Aussprache und Prosodie zu gestalten, also schreiben Sie natürlich mit Interpunktion für das Timing. Halten Sie den Seed fixiert, wenn Sie wiederholbare Takes wünschen, oder randomisieren Sie ihn, wenn Sie Lieferungsvarianten erkunden.
Sprachklonen#
Die Sprachklon-Gruppe führt Zero-Shot Sprachklonen aus einem kurzen Referenz-Audioclip durch. Importieren Sie ein sauberes Sprachbeispiel mit LoadAudio (#4), verbinden Sie es mit MossTTSGenerate (#6), das von MossTTSModelLoader (#5) gesteuert wird, und geben Sie den Zieltext an. Das Modell extrahiert Sprecher-Timbre und Stil aus der Referenz und rendert Ihr neues Skript in dieser Stimme. Verwenden Sie neutrale Inhalte und minimales Hintergrundrauschen in der Referenz, um die Ähnlichkeit zu verbessern, und halten Sie die Dauer moderat für die schnellste Bearbeitung.
Sprachdesign#
Sprachdesign erstellt eine neue Stimme aus einer Beschreibung in natürlicher Sprache anstelle eines Beispielclips. MossTTSVoiceDesign (#9) verwendet eine Textbeschreibung wie "Eine warme, tiefe männliche Stimme mit leicht britischem Akzent," kombiniert mit Ihrem Skript, um 24 kHz Sprache zu synthetisieren. Der Knoten wird von einem dedizierten Sprachgenerator-Pfad angetrieben, der über MossTTSModelLoader (#8) geladen wird. Dies ist ideal, wenn Sie eine konsistente, reproduzierbare Persona wünschen, ohne echte Aufnahmen zu beschaffen. Verfeinern Sie Beschreibungen mit Merkmalen wie Alter, Timbre, Akzent und Energie, um den Klang zu steuern.
Soundeffekte#
Soundeffekte erzeugen nicht-sprachliche Audio aus Texteingaben, nützlich für Hintergrundspuren, Übergänge oder Umgebungsgeräusche. Mit MossTTSSoundEffect (#12) und seiner Modell-Pipeline aus MossTTSModelLoader (#11) erzeugen Eingaben wie "Schwerer Regen auf einem Blechdach mit entferntem Donner" reiche, wiederholbare Texturen. Verwenden Sie prägnante Substantive und Aktionen, um die Szene zu definieren, und fügen Sie einige Adjektive hinzu, um Intensität oder Entfernung zu bestimmen. Vorschau in PreviewAudio (#13) und iterieren Sie schnell, um Ihre Mischung zu passen.
Multisprecher-Dialog#
Die Multisprecher-Dialoggruppe rendert geskriptete Gespräche mit optionalen pro-Sprecher-Referenzclips. Schreiben Sie Ihr Skript mit eckigen Sprechertags, zum Beispiel [S1] Hallo. und [S2] Hi!, und übergeben Sie es an MossTTSDialogue (#15) unter der Modell-Pipeline von MossTTSModelLoader (#14). Sie können Referenz-Audioeingaben für S1 und S2 anhängen, um spezifische Stimmen für jede Rolle zu klonen, oder sie leer lassen, damit das Modell unterschiedliche Sprecher allein aus dem Textkontext auswählt. Dieser Pfad eignet sich gut für Frage-und-Antwort, Erzählungen mit Charakterlinien oder Sprach-UI-Mockups.
Schlüssel-Knoten im Comfyui ComfyUI MOSS TTS Arbeitsablauf#
MossTTSModelLoader (#1)#
Lädt die ausgewählte OpenMOSS Modellfamilie und stellt die interne TTS-Pipeline zusammen. Wählen Sie die Local 1.7B-Variante für schnelle Iterationen auf einer einzelnen GPU oder wechseln Sie zu einem größeren Delay 8B Modell, wenn Sie Ausdruckskraft und Ähnlichkeit priorisieren. Halten Sie einen Loader pro Aufgabenfamilie, damit jeder nachgeschaltete Zweig eigenständig bleibt.
MossTTSGenerate (#2)#
Der Haupt-Einzelsprecher-Synthesizer, der Ihren Texteingabe und optionales Referenz-Audio konsumiert, um 24 kHz Sprache zu erzeugen. Bereitstellen Sie sauberen, gut interpunktierten Text für klareres Timing und verbinden Sie einen kurzen Sprachclip, wenn Sie Zero-Shot-Klonen benötigen. Wechseln Sie zwischen fester und zufälliger Seeding, um Reproduzierbarkeit und Erkundung auszugleichen.
MossTTSVoiceDesign (#9)#
Erzeugt eine neue Stimme aus einer beschreibenden Eingabeaufforderung zusammen mit dem zu sprechenden Text. Konzentrieren Sie die Beschreibung auf Timbre, Alter, Akzent und Energie, um die Identität zu steuern, während Sie sie prägnant halten. Dies ist eine starke Wahl, wenn das Lizensieren oder Beschaffen einer echten Stimme nicht praktikabel ist.
MossTTSSoundEffect (#12)#
Synthesisiert nicht-verbales Audio aus einer kurzen Textbeschreibung. Schreiben Sie kompakte Eingaben, die Quelle, Aktion und Raum verankern, und iterieren Sie, um die Szene zu treffen. Großartig für Ambiente und One-Shots im selben ComfyUI MOSS TTS Diagramm, das Sie für Dialoge verwenden.
MossTTSDialogue (#15)#
Parst eckige Sprechertags und rendert mehrteilige Gespräche als eine einzelne Audioausgabe. Verwenden Sie [S1], [S2] und so weiter, um jede Zeile zu markieren, und verbinden Sie optional pro-Sprecher-Referenzclips, um die Identität über die Runden hinweg zu bewahren. Halten Sie die Zeilen prägnant für die zuverlässigsten Übergaben zwischen den Sprechern.
Optionale Extras#
- Beginnen Sie mit dem Local 1.7B Modell für schnelle Entwürfe und wechseln Sie dann zu einem Delay 8B Checkpoint, wenn Sie stärkere Ähnlichkeit oder reichere Prosodie benötigen.
- Für Zero-Shot-Klonen verwenden Sie einen sauberen 5–15 s Sprachclip mit minimalem Nachhall und Rauschen, um den Timbre-Transfer zu verbessern.
- Halten Sie in Dialogen Sprechertags konsistent und frei von Interpunktion wie
[S1], um Parsing-Fehler zu vermeiden. - Gestalten Sie Sprachdesign-Eingaben mit 3–6 Merkmalen wie Timbre, Alter, Akzent, Stil und Energie für vorhersehbare Ergebnisse.
- Verwenden Sie Interpunktion und Zeilenumbrüche in Ihrem Text, um Pausen und Timing in ComfyUI MOSS TTS Ausgaben zu steuern.
- Fügen Sie einen
SaveAudioKnoten nach jeder Vorschau hinzu, wenn Sie eine automatische Dateiexportfunktion für Batch-Render benötigen.
Referenzen: OpenMOSS/MOSS-TTS • MOSS-TTS-Local-Transformer • MOSS-TTS • MOSS-Audio-Tokenizer • comfyui-moss-tts
Danksagungen#
Dieser Arbeitsablauf implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken richservo für die ComfyUI MOSS-TTS benutzerdefinierten Knoten, OpenMOSS für das MOSS-TTS Repository und OpenMOSS-Team für die MOSS-TTS Modelle (Delay 8B und Local 1.7B) und den MOSS Audio Tokenizer für ihre Beiträge und Wartung. Für maßgebliche Details verweisen wir auf die originale Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- richservo/comfyui-moss-tts
- GitHub: richservo/comfyui-moss-tts
- OpenMOSS/MOSS-TTS
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS (Delay 8B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-TTS-Local-Transformer (Local 1.7B)
- GitHub: OpenMOSS/MOSS-TTS
- Hugging Face: OpenMOSS-Team/MOSS-TTS-Local-Transformer
- arXiv: 2603.18090
- OpenMOSS-Team/MOSS-Audio-Tokenizer
- Hugging Face: OpenMOSS-Team/MOSS-Audio-Tokenizer
- arXiv: 2602.10934
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.