
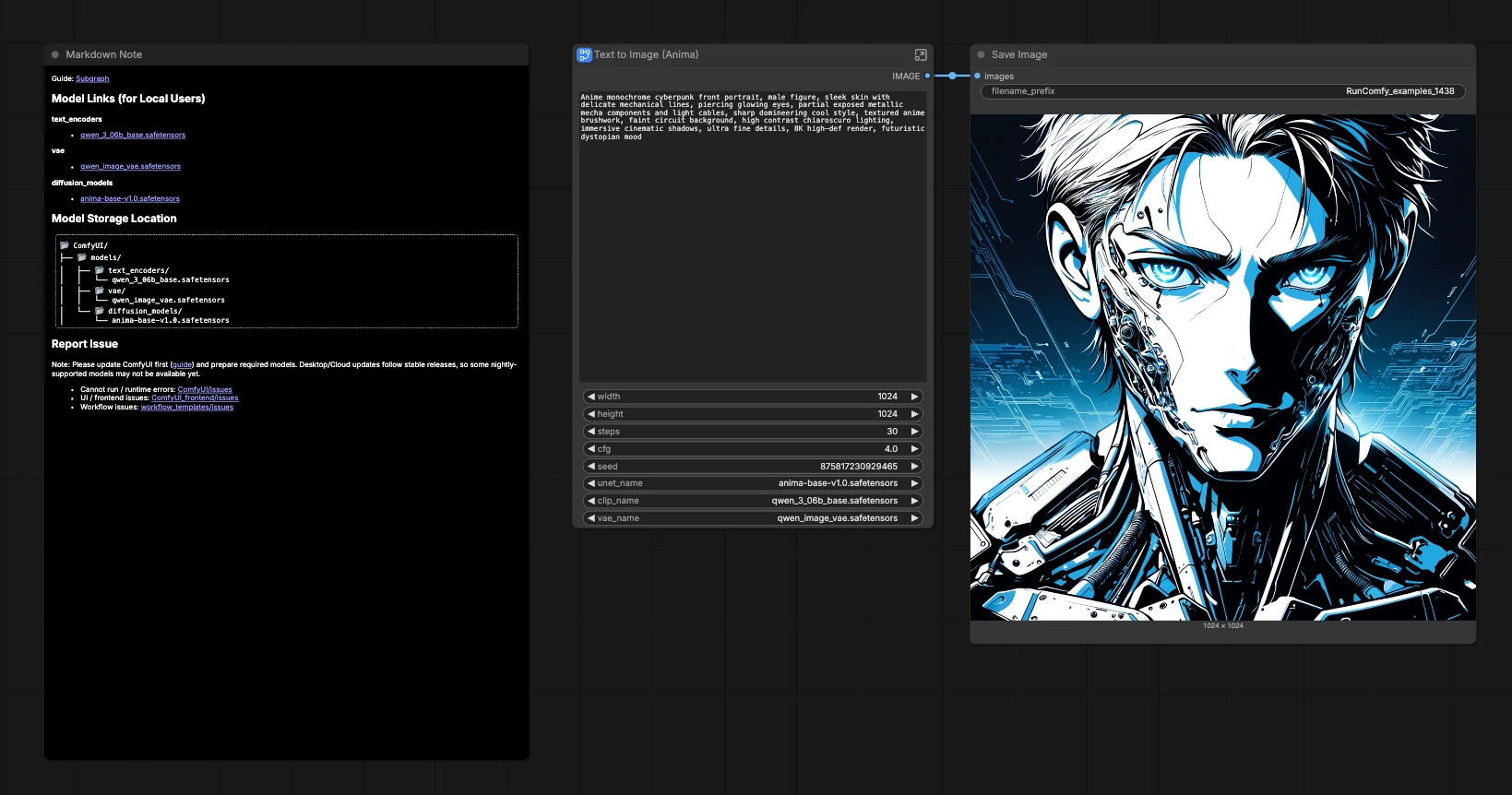






Anima Base v1 ComfyUI: Anime-Cyberpunk-Text-zu-Bild-Workflow#
Diese Vorlage ist ein kompakter, offizieller Anima Base v1 ComfyUI-Workflow zum Erzeugen kontrastreicher Anime-Porträts und stilisierter Illustrationen aus einem einzigen Eingabeprompt. Sie ist auf saubere Linienführung, filmische Beleuchtung und Cyberpunk-Stimmung abgestimmt, während das Diagramm minimal gehalten wird, damit Sie sich auf Kreativität statt auf Verkabelung konzentrieren können.
Angetrieben von CircleStone Labs Anima Base v1.0 mit Qwen-Textcodierung und dem Qwen Image VAE, bietet der Workflow genau die Steuerungen, die Sie für Iterationen benötigen: Eingabe, Samplereinstellungen, Auflösung, Seed und Modellauswahl. Es ist ein schneller Ausgangspunkt für Anime-Charakterkunst, Cyberpunk-Porträts und promptgesteuerte Illustrationsstudien.
Wichtige Modelle im Anima Base v1 ComfyUI-Workflow#
- CircleStone Labs Anima Base v1.0 Diffusionsmodell. Der Kern-UNet, der latente Bilder mit klaren Anime-Linien, kontrastreicher Schattierung und stilisierten Details synthetisiert. Es liefert das visuelle Vorbild, das Cyberpunk-Porträts und Charakterkunst hervorhebt. Model card
- Qwen3 0.6B Base Text Encoder. Übersetzt Ihren Eingabeprompt in Einbettungen, die das Diffusionsmodell versteht, und verbessert die Subjektgenauigkeit und Stilkontrolle für Anime-Eingaben. Wird mit dem Anima-Paket als qwen_3_06b_base.safetensors verteilt. Files
- Qwen Image VAE. Dekodiert das endgültige Latent in ein Bild in voller Auflösung, während Animas Kontrast und Farbantwort erhalten bleiben. Wird als qwen_image_vae.safetensors geliefert. Files
So verwenden Sie den Anima Base v1 ComfyUI-Workflow#
Der Workflow läuft in einem Durchgang: Ihr Prompt wird kodiert, ein latentes Bild wird abgetastet, dann zu Pixeln dekodiert und gespeichert. Drei Gruppen organisieren das Erlebnis, sodass Sie schnell von der Idee zum Ergebnis gelangen können.
Modell#
Verwenden Sie diese Gruppe, um das Anima Base v1.0 Diffusionsmodell, den Qwen-Textencoder und das Qwen Image VAE auszuwählen. Wenn diese drei übereinstimmen, bleibt der beabsichtigte Look und Kontrast von Anima erhalten. Sie können sie für Experimente austauschen, aber die Verwendung nicht-Anima-Assets wird Farbe, Texturen und Kantendarstellung ändern. Wenn Sie planen, Varianten zu vergleichen, halten Sie den Seed fest, damit Unterschiede die Modellauswahl und nicht zufälliges Rauschen widerspiegeln.
Bildgröße#
Stellen Sie die Breite und Höhe für die latente Leinwand ein. Quadratische Rahmen eignen sich für Porträts und erleichtern die Beurteilung von Beleuchtung und Stil, während vertikale Verhältnisse wie 3:4 oder 4:5 Charaktere betonen. Größere Größen verbessern Details, erhöhen jedoch den Speicherverbrauch und die Abtastzeit. Beginnen Sie bescheiden, finden Sie einen Look, den Sie lieben, und skalieren Sie dann für die Endversionen hoch.
Eingabe#
Geben Sie Ihre kreative Beschreibung in den positiven Prompt ein. Für Anime-Cyberpunk kombinieren Sie Subjekt + Styling + Beleuchtung, zum Beispiel: "stilisiertes Anime-Cyberpunk-Porträt, Neonakzente, reflektierendes Metall, filmisches Gegenlicht." Der interne negative Prompt ist mit häufigen Qualitätsunterdrückern vorbefüllt, um Artefakte und verschwommene Kanten zu reduzieren, während das freigelegte Textfeld den Haupt-Input leicht bearbeitbar hält.
Abtastung und Ausgabe#
Hinter den Kulissen generiert der Sampler das latente Bild unter Verwendung Ihrer steps, cfg und seed. Mehr Schritte fügen Verfeinerung hinzu, während cfg die Einhaltung des Prompts gegen das künstlerische Vorbild des Modells ausbalanciert. Der VAE dekodiert das Latent zu RGB, und das Bild wird mit einem Basisnamen gespeichert, sodass Sie Iterationen verfolgen können, während Sie Variationen erkunden.
Wichtige Knoten im Anima Base v1 ComfyUI-Workflow#
KSampler(#19). Der Motor, der Ihre Konditionierung in ein latentes Bild verwandelt. Erhöhen Sie diesteps, um kompliziertere Linienführung und Mikrodetaillierung zu erhalten; passen Siecfgniedriger für freiere, stimmungsgetriebene Ergebnisse oder höher für striktere Eingabefolgen an; fixieren Sieseed, um eine Komposition zu reproduzieren, während Sie Wortwahl oder Einstellungen ändern.CLIP Text Encode (Positive Prompt)(#11). Wandelt Ihren Text in Einbettungen für das Modell um. Prägnante, beschreibende Phrasen neigen dazu, die saubersten Anime-Kanten zu erzeugen. Mischen Sie Subjekt-, Medium- und Beleuchtungsbegriffe und iterieren Sie, indem Sie pro Durchgang ein Wort tauschen, um zu lernen, was den Look antreibt.CLIP Text Encode (Negative Prompt)(#12). Drängt den Sampler von unerwünschten Merkmalen weg. Behalten Sie die enthaltenen Qualitätsfilter bei und fügen Sie zielgerichtete Ausschlüsse wie "niedriger Kontrast", "überglättete Haut" oder "Linsenreflexion" hinzu, wenn nötig.EmptyLatentImage(#28). Definiert die Leinwandgröße. Verwenden Sie quadratisch für Charakterbüsten, hohe Vertikale für Ganzkörperaufnahmen oder breitere Rahmen für Umgebungszusammenhänge. Wenn Sie das Seitenverhältnis während des Projekts ändern, erwarten Sie, dass sich die Komposition neu ordnet, selbst mit demselben Seed.UNETLoader(#44). Lädt die Anima Base v1.0 Diffusionsgewichte. Dieser Knoten ist der schnellste Weg, um kompatible Modellvarianten zu A/B testen, während alles andere konstant bleibt.VAELoader(#15). Wählt das Qwen Image VAE aus. Wenn Sie beim gepaarten VAE bleiben, wird Animas Kontrast und Farbabbildung beibehalten; das Austauschen von VAEs wird Töne und Kantenschärfe subtil verschieben.
Optionale Extras#
- Beginnen Sie mit kurzen Eingaben, fügen Sie dann einen Modifikator nach dem anderen hinzu, um zu lernen, wie Anima Base v1 ComfyUI reagiert.
- Halten Sie
seedfest, während Sie Eingaben undcfgabstimmen, ändern Sie ihn dann, um neue Kompositionen zu erkunden. - Für scharfe, grafische Anime-Schattierung bevorzugen Sie klare Beleuchtungsbegriffe wie "hartes Gegenlicht" oder "tiefes Chiaroscuro".
- Verwenden Sie vertikale Verhältnisse für Charakterporträts und quadratisch für Avatare oder soziale Thumbnails, um Überraschungen beim Zuschneiden zu reduzieren.
- Wenn Sie Streifenbildung oder ausgewaschene Farben sehen, versuchen Sie eine kleine
cfg-Anpassung oder verfeinern Sie die Eingabewortwahl, um den Kontrast zu steuern. - Benennen Sie Iterationen in
SaveImagemit einem Projektpräfix, damit Chargen beim Vergleich der Ergebnisse sauber sortiert werden.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Comfy Org für die Quell-Text-zu-Bild-Workflow-Vorlage und CircleStone Labs für Anima und Anima Base v1.0 (Diffusers). Für autoritative Details verweisen wir auf die Originaldokumentation und Repositories, die unten verlinkt sind.
Ressourcen#
- Comfy Org/Anima Base v1 Text to Image
- GitHub: Comfy-Org
- Docs / Release Notes: Comfy workflow source
- CircleStone Labs/Anima
- Hugging Face: circlestone-labs/Anima
- CircleStone Labs/Anima Base v1.0 (Diffusers)
- Hugging Face: circlestone-labs/Anima-Base-v1.0-Diffusers
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Verwalter.

