
ACE-Step 1.5XL Base Text zu Musik: Prompt‑zu‑Song-Workflow für ComfyUI#
Dieser Workflow wandelt Beschreibungen in natürlicher Sprache in fertige Audiodateien um, indem die ACE-Step 1.5XL Base Diffusionsfamilie verwendet wird. Er kombiniert das Basismodell mit seinem ACE Step VAE und den dualen Qwen-Text-Encodern, um die Ergebnisse fest im Musikbereich und nicht bei TTS oder Sprache zu halten. Wenn Sie KI-Musik mit vorhersehbarer Struktur, Tempi und Instrumentierung wünschen, ist diese ACE-Step 1.5XL Base Text zu Musik-Pipeline ein fokussiertes, minimalistisches Setup, das Sie schnell von der Idee zum MP3 bringt.
Entwickelt für Produzenten, Sounddesigner und Kreative, betont das Diagramm Klarheit: Modelle auswählen, eine Dauer festlegen, ein musikalisches Prompt schreiben, dann generieren und speichern. Der ACE-Step 1.5XL Base Text zu Musik-Workflow ist kompakt genug für schnelle Iterationen und bleibt dennoch ausdrucksstark für detaillierte Arrangements, Tonarten und Tempi.
Wichtige Modelle im Comfyui ACE-Step 1.5XL Base Text zu Musik-Workflow#
- ACE-Step 1.5 XL Base (bf16) Diffusionsmodell. Das generative Rückgrat, das Audio-Latents in kohärente Musikphrasen und -texturen entrauscht. Modelldatei
- ACE Step 1.5 VAE. Der gepaarte Variationsautoencoder, der zwischen latentem Raum und Wellenformbereich kodiert/dekodiert und Timbre und Mix-Balancen bewahrt. Modelldatei
- Qwen 4B ACE15 Text-Encoder. Ein großer Text-Encoder, der für ACE angepasst wurde und reichhaltige musikalische Semantik, Struktur- und Arrangementhinweise aus dem Prompt erfasst. Modelldatei
- Qwen 0.6B ACE15 Text-Encoder. Ein leichter ACE-angepasster Encoder, der Geschwindigkeit und Ressourceneffizienz priorisiert und dabei dennoch ein starkes Verständnis für den Prompt beibehält. Modelldatei
Verwendung des Comfyui ACE-Step 1.5XL Base Text zu Musik-Workflows#
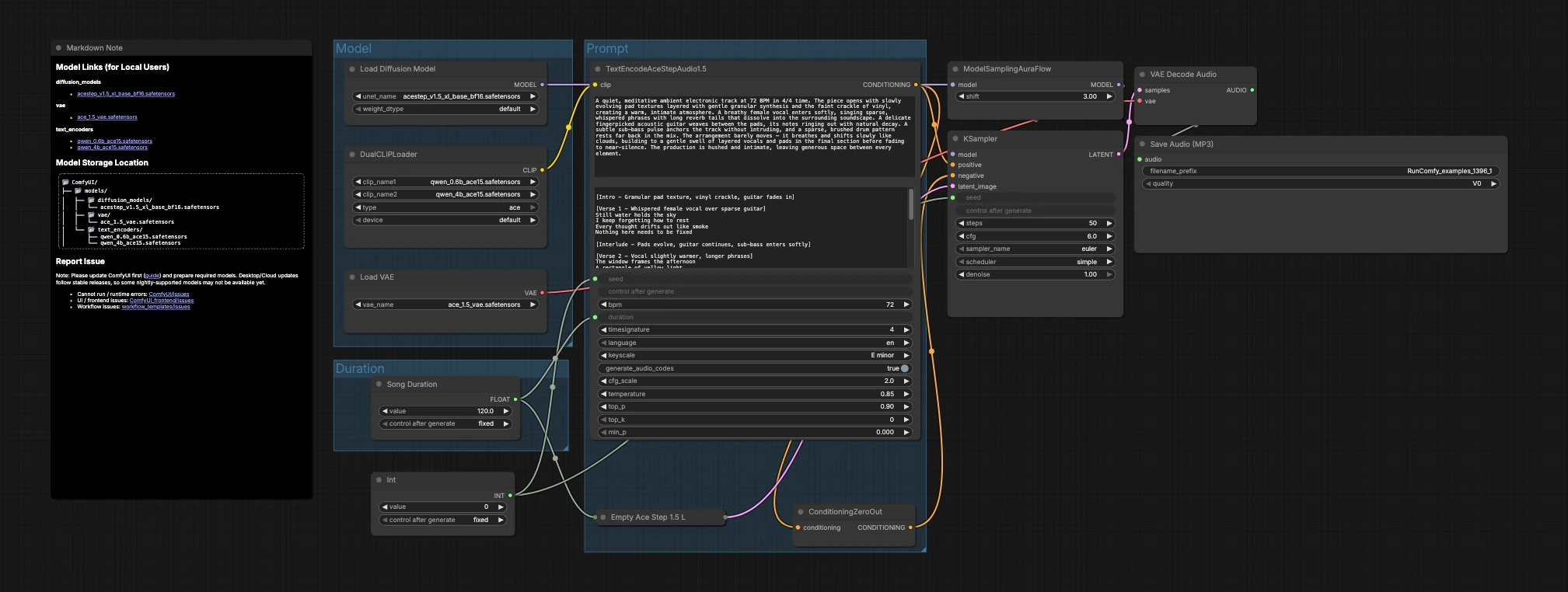
Das Diagramm ist in drei Gruppen organisiert, die in die Generierung und den Export übergehen: Modell, Dauer und Prompt. Sie laden die Modelle, wählen eine Zieldauer, beschreiben die Musik, dann erstellt der Sampler Latents, die der VAE in Audio dekodiert.
Modell#
Diese Gruppe lädt die Kernressourcen. UNETLoader (#104) wählt den ACE-Step 1.5 XL Base Diffusions-Checkpoint, und VAELoader (#106) lädt den passenden ACE Step 1.5 VAE, sodass die Dekodierungsqualität mit der Schulung übereinstimmt. DualCLIPLoader (#105) bringt beide Qwen ACE15-Encoder ein; der Workflow verwendet sie gemeinsam, damit reichhaltige Text-Prompts in starke musikalische Konditionierung übersetzt werden.
Dauer#
Hier entscheiden Sie, wie lang das Stück sein soll. Song Duration (#99) legt die Zieldauer in Sekunden fest und leitet sie weiter, damit die latente Leinwand und die Textkonditionierung übereinstimmen. PrimitiveInt (#109) bietet einen Seed, mit dem Sie genaue Ergebnisse für Reproduzierbarkeit festlegen oder variieren können, um alternative Aufnahmen zu erkunden.
Prompt#
Hier wird Sprache zu Musik. Schreiben Sie Ihre Beschreibung in TextEncodeAceStepAudio1.5 (#94), einschließlich hilfreicher musikalischer Metadaten wie Tempo (BPM), Taktart, Tonart, Instrumentierung, Arrangement, vokale Präsenz und Mix-Anmerkungen. Der Knoten gibt die positive Konditionierung aus; ConditioningZeroOut (#47) liefert einen neutralen negativen Pfad, sodass die Generierung sich auf Ihre Beschreibung konzentriert. EmptyAceStep1.5LatentAudio (#98) initialisiert eine latente Audio-Zeitleiste für die gewählte Dauer. ModelSamplingAuraFlow (#78) passt das Basismodell an einen Scheduler an, der für ACE-Step-Audio geeignet ist. KSampler (#3) kombiniert Modell, Konditionierung, Latent und Seed, um das Musiklatent zu erzeugen. VAEDecodeAudio (#18) wandelt das Latent zurück in die Wellenform, und SaveAudioMP3 (#107) schreibt das Ergebnis in eine MP3-Datei, die bereit ist, geteilt zu werden.
Schlüssel-Knoten im Comfyui ACE-Step 1.5XL Base Text zu Musik-Workflow#
TextEncodeAceStepAudio1.5 (#94)#
Verwandelt Ihren Prompt in eine Konditionierung, der das Diffusionsmodell folgen kann. Es akzeptiert musikalische Details wie Tempo, Taktart, Tonart, Arrangement-Hinweise, Instrumentierung, Sprache und optionale vokale Absicht. Für beste Ergebnisse sollten Sie konkret über Genre, Gefühl und Mix-Platzierung sein und strukturelle Hinweise prägnant halten, damit das Modell die Kohärenz über die angeforderte Dauer aufrechterhalten kann.
EmptyAceStep1.5LatentAudio (#98)#
Erstellt die latente Audio-„Leinwand“ für das Stück. Passen Sie seine Sekunden an das an, was Sie in Song Duration (#99) festgelegt und im Text-Encoder referenziert haben, um unbeabsichtigte Kürzungen oder Auffüllungen zu vermeiden. Längere Leinwände laden zu einer allmählicheren Entwicklung ein, während kürzere sich für Loops, Cues und Stinger eignen.
ModelSamplingAuraFlow (#78)#
Konfiguriert die auf ACE-Step-Audio zugeschnittene Sampling-Strategie. Verwenden Sie es wie bereitgestellt für stabile Ergebnisse; passen Sie es nur an, wenn Sie eine spezifische Scheduler-Präferenz haben, da es mit Schrittzahl und Führung in KSampler (#3) interagiert.
KSampler (#3)#
Führt das Denoising durch, das Konditionierung in Audio-Latents verwandelt. Die Schlüsselhebel hier sind Samplertyp, Schrittanzahl und Seed. Erhöhen Sie die Schritte, um Details auf Kosten der Zeit zu verfeinern, und halten Sie den Seed fixiert, wenn Sie Prompts vergleichen, damit Sie Änderungen dem Text und nicht dem Zufall zuschreiben können.
DualCLIPLoader (#105)#
Lädt beide Qwen ACE15-Text-Encoder. Wenn Sie Zugang zu beiden haben, beginnen Sie mit dem 4B-Encoder für ein reichhaltigeres Sprachverständnis; wechseln Sie zur 0.6B-Variante, wenn Sie schnellere Iterationen oder einen geringeren Speicherverbrauch benötigen. Halten Sie die Encoder-Wahl konsistent über Aufnahmen hinweg, wenn Sie subtile Prompt-Änderungen bewerten.
ConditioningZeroOut (#47)#
Bietet einen neutralen negativen Pfad. Wenn Sie spezifische Artefakte unterdrücken oder von gesprochenen Inhalten weglenken möchten, können Sie dies durch einen tatsächlichen negativen Prompt-Knoten ersetzen; andernfalls hält das genullte Negative die ACE-Step 1.5XL Base Text zu Musik-Generierung auf Ihre positive Beschreibung fokussiert.
Optionale Extras#
- Beginnen Sie Prompts mit einem kompakten Rezept: Genre + Stimmung + Tempo + Taktart + Tonart + Instrumentierung + Arrangement + Mix-Anmerkungen.
- Verwenden Sie explizite musikalische Verben und Rollen (Lead, Pad, Bass, Percussion), damit das Modell Platz im Mix zuweist und sprachähnliche Inhalte vermeidet.
- Fixieren Sie den Seed beim A/B-Testing von Prompts, dann variieren Sie den Seed, um alternative Darbietungen einer erfolgreichen Idee zu erkunden.
- Halten Sie die Dauer über
Song Duration(#99),TextEncodeAceStepAudio1.5(#94) undEmptyAceStep1.5LatentAudio(#98) hinweg konsistent für vorhersehbare Phrasierung. - Wählen Sie Qwen 4B für ein reichhaltigeres Prompt-Verständnis oder 0.6B für Geschwindigkeit; halten Sie Ihre Wahl konstant, während Sie iterieren, um Vergleiche fair zu gestalten.
Danksagungen#
Dieser Workflow implementiert und baut auf folgenden Arbeiten und Ressourcen auf. Wir danken Comfy.org für den audio_ace_step1_5_xl_base Workflow, Comfy-Org für das ACE Step 1.5 XL Base Diffusionsmodell und ACE Step 1.5 VAE sowie dem Qwen-Team für die 0.6B und 4B ACE15 Text-Encoder für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- Comfy.org/Workflow-Quellseite
- Docs / Release Notes: audio_ace_step1_5_xl_base Workflow-Seite
- Comfy-Org/ACE Step 1.5 XL Base Diffusionsmodell
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 Text-Encoder
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 Text-Encoder
- Hugging Face: qwen_4b_ace15.safetensors
Hinweis: Die Verwendung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.