
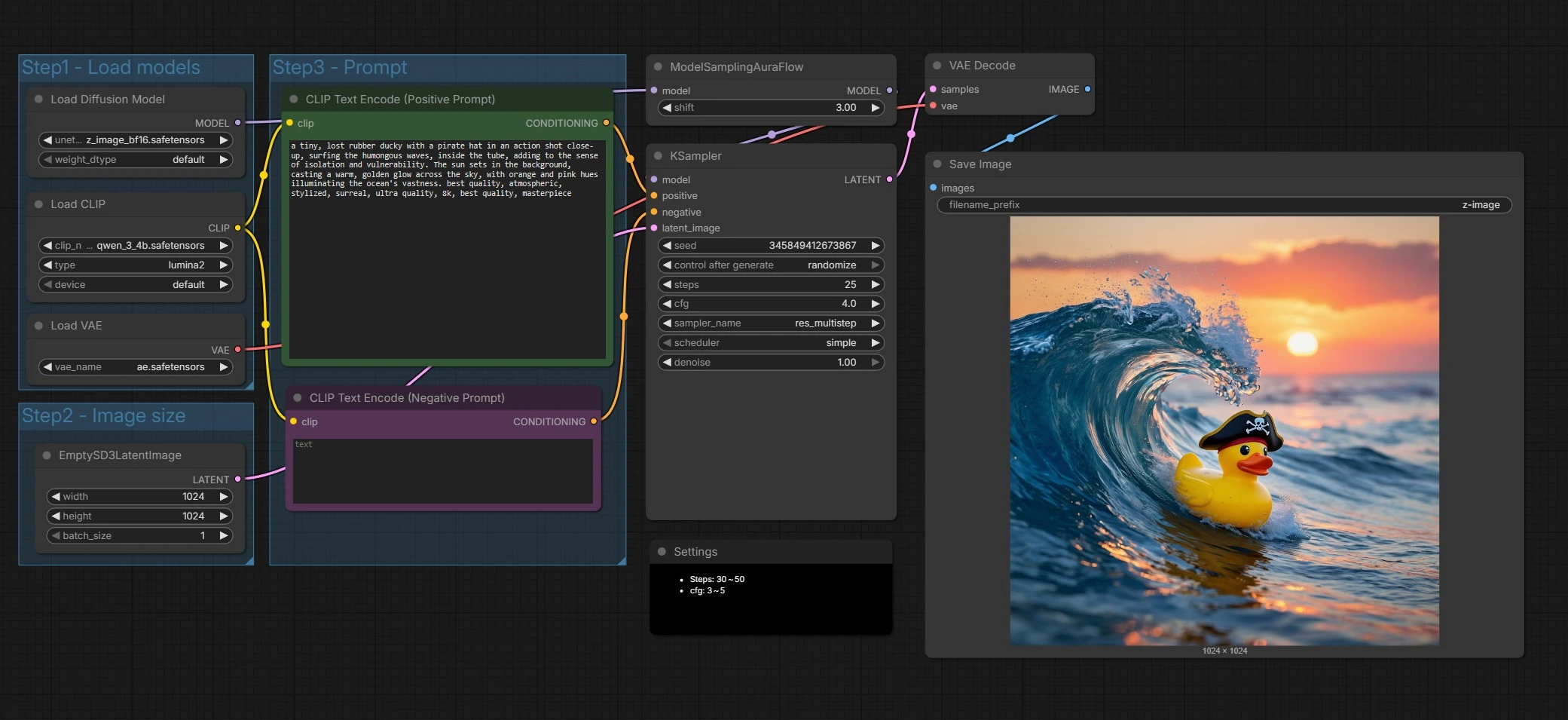
















ComfyUI 的 Z-Image 文本到影像工作流程#
此 ComfyUI 工作流程展示了 Z-Image,一種為快速、高保真影像生成而設計的下一代擴散變壓器。基於可擴展的單流架構,約有 60 億個參數,Z-Image 在寫實性、強提示遵循性和雙語文字呈現之間取得平衡。
開箱即用,圖形設置為 Z-Image 基礎版,以在普通 GPU 上最大化質量和效率。當速度重要時,它也能很好地與 Z-Image Turbo 變體配合,其結構使其易於擴展到 Z-Image 編輯,用於影像到影像任務。如果您想要一個可靠、簡約的圖形,將清晰的提示轉化為乾淨的結果,這個 Z-Image 工作流程是一個堅實的起點。
ComfyUI Z-Image 工作流程中的關鍵模型#
- Z-Image 基礎擴散變壓器 (bf16)。核心生成器,使用 Z-Image 的單流拓撲和提示控制將潛在噪點轉化為影像。模型頁面 • bf16 權重
- Qwen 3 4B 文本編碼器。為 Z-Image 編碼提示,具有強大的雙語覆蓋和清晰的標記化以進行文字呈現。編碼器權重
- Z-Image 自編碼器 VAE。在像素空間和 Z-Image 潛在空間之間壓縮和重建影像。VAE 權重
如何使用 ComfyUI Z-Image 工作流程#
在高層次上,圖形加載 Z-Image 組件,準備一個潛在畫布,編碼您的正面和負面提示,運行一個針對 Z-Image 調整的採樣器,然後解碼並保存結果。您主要提供提示並選擇輸出大小;其餘部分設置為合理的默認值。
步驟1 - 加載模型#
此組初始化 Z-Image UNet、Qwen 3 4B 文本編碼器和 VAE,以便所有組件對齊。UNETLoader (#66) 默認指向 Z-Image 基礎版,偏向於保真度和編輯空間。CLIPLoader (#62) 引入 Qwen 基於的編碼器,能夠很好地處理多語言提示和文字標記。VAELoader (#63) 設置後續用於解碼的自編碼器。如果您想嘗試 Z-Image Turbo 以獲得更快的草稿,可以在此處交換權重。
步驟2 - 影像大小#
此組通過 EmptySD3LatentImage (#68) 設置潛在畫布。選擇您想要生成的寬度和高度,並記住構圖的長寬比。Z-Image 在常見創意尺寸中表現良好,因此選擇符合您的故事板或交付格式的尺寸。較大尺寸增加細節和計算成本。
步驟3 - 提示#
在這裡,您書寫您的故事。CLIP Text Encode (Positive Prompt) (#67) 節點接收您的場景描述和風格指令給 Z-Image。CLIP Text Encode (Negative Prompt) (#71) 幫助避免工件或不需要的元素。Z-Image 對雙語文字呈現進行了調整,因此當需要時,您可以直接在提示中包括多種語言的文字內容。保持提示具體和視覺化,以獲得最一致的結果。
採樣和去噪#
ModelSamplingAuraFlow (#70) 應用一個與 Z-Image 的單流設計對齊的採樣策略,然後 KSampler (#69) 驅動去噪過程,將噪點轉化為符合您提示的影像。採樣器結合您的正面和負面條件與潛在畫布,逐步完善結構和細節。您可以通過調整如下所述的採樣器設置來在此處進行速度與質量的權衡。這個階段是 Z-Image 的提示遵循性和文字清晰度真正展現的地方。
解碼和保存#
VAEDecode (#65) 將最終潛在轉化為 RGB 影像。SaveImage (#9) 使用節點中設置的前綴寫入文件,以便您的 Z-Image 輸出易於查找和組織。這完成了從提示到像素的完整過程。
ComfyUI Z-Image 工作流程中的關鍵節點#
UNETLoader (#66)#
加載執行實際去噪的 Z-Image 主幹。在探索速度或編輯用例時,請在此處更換其他 Z-Image 變體。如果您更改變體,請保持編碼器和 VAE 兼容,以避免顏色或對比度變化。
CLIP Text Encode (Positive Prompt) (#67)#
編碼 Z-Image 的主要描述。撰寫簡潔、視覺化的短語,指定主題、光照、攝影機、氛圍和任何影像上的文字。對於文字呈現,請將所需的單詞放在引號中並保持簡短,以獲得最佳可讀性。
CLIP Text Encode (Negative Prompt) (#71)#
定義要避免的內容,以便 Z-Image 可以專注於正確的細節。用於抑制模糊、多餘的肢體、混亂的排版或不合風格的元素。保持簡潔並與主題相關,以免過度限制構圖。
EmptySD3LatentImage (#68)#
創建 Z-Image 將繪製的潛在畫布。選擇適合最終用途的尺寸,並保持它們是 64 像素的倍數,以實現高效的內存使用。更寬或更高的畫布會影響構圖和透視,因此請相應調整提示。
ModelSamplingAuraFlow (#70)#
選擇與 Z-Image 的訓練和潛在空間匹配的採樣器預設。除非您正在測試替代採樣器,否則很少需要更改此設置。保留提供的設置,以獲得穩定、無工件的結果。
KSampler (#69)#
控制 Z-Image 的質量與速度權衡。增加 steps 以獲得更多細節和穩定性,減少以獲得更快的草稿。保持 cfg 適中,以平衡提示遵循性與自然紋理;此圖中的典型值為 steps: 30 到 50 和 cfg: 3 到 5。設置固定的 seed 以實現可重現性,或隨機化以探索變化。
VAEDecode (#65)#
將 Z-Image 的最終潛在轉化為 RGB 影像。如果您更改 VAE,請保持其與模型系列匹配,以保護色彩準確性和銳度。
SaveImage (#9)#
使用清晰的檔名前綴寫入結果,以便 Z-Image 輸出易於分類。調整前綴以區分實驗、模型變體或縱橫比。
可選附加功能#
- 使用 Z-Image Turbo 進行快速構思,然後切換回 Z-Image Base 並提高步驟數以進行最終渲染。
- 對於雙語提示和影像上的文字,保持提示簡短且高對比度,以幫助 Z-Image 呈現清晰的字體。
- 在比較小提示編輯時鎖定種子,以便差異反映您的更改而非新噪點。
- 如果看到過飽和或光暈,稍微降低
cfg或加強負面提示以恢復平衡。
鳴謝#
此工作流程實施並基於以下作品和資源。我們感謝 Comfy-Org 為 Z-Image Day-0 ComfyUI 工作流程模板的貢獻和維護。欲了解權威詳情,請參閱下列鏈接的原始文檔和存儲庫。
資源#
- Comfy-Org/Z-Image Day-0 在 ComfyUI 中的支持
- GitHub: Comfy-Org/workflow_templates
- 文檔 / 發布說明: 來源
注意:所引用的模型、數據集和代碼的使用需遵循其作者和維護者提供的相應許可和條款。
