
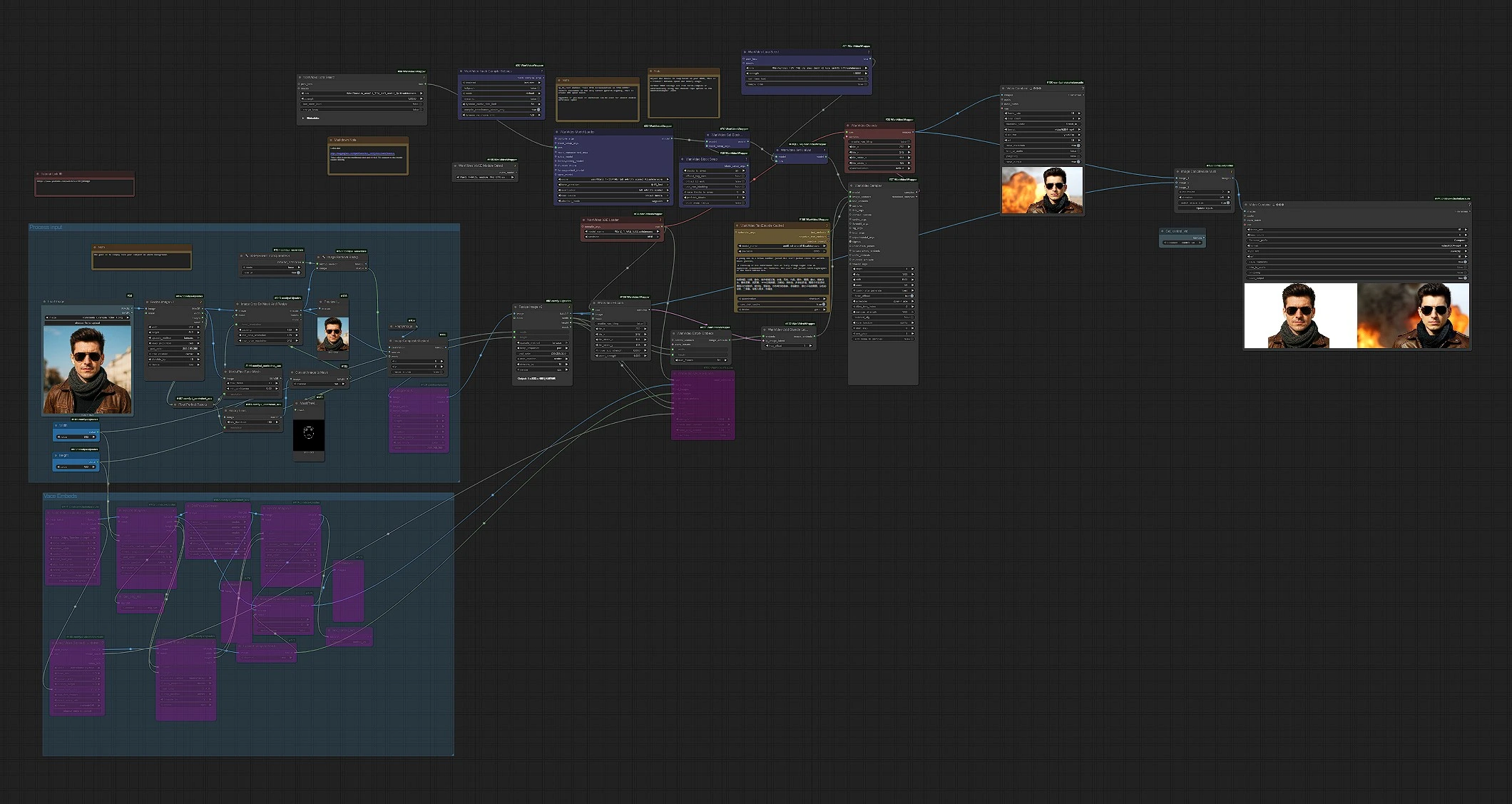
Wan2.1 Stand In: 單圖像角色一致性影片生成工具 for ComfyUI#
這個工作流程將一張參考圖像轉化為短影片,其中相同的面孔和風格在幀中持續。由 Wan 2.1 系列和專門設計的 Stand In LoRA 提供動力,適合需要穩定身份且設置最小化的故事講述者、動畫師和虛擬人物創作者。Wan2.1 Stand In 管道處理背景清理、裁剪、遮罩和嵌入,因此您可以專注於您的提示和運動。
當您需要從單張照片獲得可靠的身份連續性、快速迭代以及可導出的 MP4 和可選的並排比較輸出時,請使用 Wan2.1 Stand In 工作流程。
Comfyui Wan2.1 Stand In 工作流程中的關鍵模型#
- Wan 2.1 Text-to-Video 14B。負責時間一致性和運動的主要生成器。它支持 480p 和 720p 的生成,並與 LoRAs 集成以實現目標行為和風格。Model card
- Wan-VAE for Wan 2.1。一種高效的時空 VAE,在保持運動提示的同時編碼和解碼影片潛變量。它支援此工作流程中的圖像編碼/解碼階段。請參見 Wan 2.1 模型資源和 Diffusers 集成說明以了解 VAE 的使用。Model hub • Diffusers docs
- Stand In LoRA for Wan 2.1。角色一致性適配器,訓練以鎖定單張圖像的身份;在此圖中,它在模型加載時應用以確保身份信號融合於基礎。Files
- LightX2V Step-Distill LoRA(可選)。一個輕量級適配器,可以提高 Wan 2.1 14B 的指導行為和效率。Model card
- VACE module for Wan 2.1(可選)。通過影片感知條件啟用運動和編輯控制。工作流程包括一個嵌入路徑,您可以啟用 VACE 控制。Model hub
- UMT5-XXL text encoder。為 Wan 2.1 提供強大的多語言提示編碼。Model card
如何使用 Comfyui Wan2.1 Stand In 工作流程#
概覽:加載一張乾淨的、正面朝前的參考圖像,工作流程準備一個面部聚焦的遮罩和合成,將其編碼為潛變量,將該身份合併到 Wan 2.1 圖像嵌入中,然後採樣影片幀並導出 MP4。保存兩個輸出:主渲染和並排比較。
處理輸入(群組)#
從一個光線充足、正面朝前的圖像開始,背景簡單。管道在 LoadImage (#58) 中加載您的圖像,用 ImageResizeKJv2 (#142) 標準化大小,並使用 MediaPipe-FaceMeshPreprocessor (#144) 和 BinaryPreprocessor (#151) 創建一個面部中心的遮罩。背景在 TransparentBGSession+ (#127) 和 ImageRemoveBackground+ (#128) 中移除,然後主題被合成到一個乾淨的畫布上,使用 ImageCompositeMasked (#108) 以最小化顏色滲透。最後,ImagePadKJ (#129) 和 ImageResizeKJv2 (#68) 對生成的長寬比進行對齊;準備好的幀通過 WanVideoEncode (#104) 編碼為潛變量。
VACE 嵌入(可選群組)#
如果您想從現有剪輯中獲得運動控制,請使用 VHS_LoadVideo (#161) 加載它,並可選擇使用 VHS_LoadVideo (#168) 加載次要指南或 Alpha 影片。幀通過 DWPreprocessor (#163) 獲得姿勢提示,並通過 ImageResizeKJv2 (#169) 進行形狀匹配;ImageToMask (#171) 和 ImageCompositeMasked (#174) 讓您精確地混合控制圖像。WanVideoVACEEncode (#160) 將這些轉換為 VACE 嵌入。此路徑是可選的;當您希望僅使用 Wan 2.1 的文本驅動運動時,請保持不變。
模型、LoRAs 和文本#
WanVideoModelLoader (#22) 加載 Wan 2.1 14B 基礎和 Stand In LoRA,以便從一開始就將身份烘焙進去。VRAM 友好的速度特徵可通過 WanVideoBlockSwap (#39) 獲得,並用 WanVideoSetBlockSwap (#70) 應用。您可以通過 WanVideoSetLoRAs (#79) 附加額外的適配器,如 LightX2V。提示用 WanVideoTextEncodeCached (#159) 編碼,使用 UMT5-XXL 進行多語言控制。保持提示簡潔描述性;強調主題的服裝、角度和照明以補充 Stand In 身份。
身份嵌入和採樣#
WanVideoEmptyEmbeds (#177) 建立圖像嵌入的目標形狀,WanVideoAddStandInLatent (#102) 注入您的編碼參考潛變量以保持身份隨時間的持續。合併的圖像和文本嵌入進入 WanVideoSampler (#27),使用配置的調度器和步驟生成潛變量影片序列。採樣後,幀用 WanVideoDecode (#28) 解碼,並用 VHS_VideoCombine (#180) 寫入 MP4。
比較視圖和導出#
為了即時質量檢查,ImageConcatMulti (#122) 將生成的幀與調整大小的參考並排堆疊,讓您逐幀判斷相似度。VHS_VideoCombine (#74) 將其保存為單獨的“比較”MP4。因此,Wan2.1 Stand In 工作流程產生乾淨的最終影片和並排檢查而無需額外努力。
Comfyui Wan2.1 Stand In 工作流程中的關鍵節點#
WanVideoModelLoader(#22)。加載 Wan 2.1 14B 並在模型初始化時應用 Stand In LoRA。請將 Stand In 適配器連接在此處而非圖中稍後的部分,以便在去噪路徑中強制身份。配對WanVideoVAELoader(#38) 以匹配 Wan-VAE。WanVideoAddStandInLatent(#102)。將您的編碼參考圖像潛變量融合到圖像嵌入中。如果身份漂移,增加其影響;如果運動似乎過於受限,稍微減少它。WanVideoSampler(#27)。主要生成器。調整步驟、調度器選擇和指導策略在此處對細節、運動豐富性和時間穩定性有最大影響。當推高分辨率或長度時,考慮在改變上游任何東西之前調整採樣器設置。WanVideoSetBlockSwap(#70) 與WanVideoBlockSwap(#39)。通過在設備之間交換注意力塊來交換 GPU 記憶體以提高速度。如果看到內存不足錯誤,增加卸載;如果有空間,減少卸載以加快迭代。ImageRemoveBackground+(#128) 和ImageCompositeMasked(#108)。這些確保主題被乾淨地隔離並放置在中性畫布上,這減少了顏色污染並提高了跨幀的 Stand In 身份鎖定。VHS_VideoCombine(#180)。控制主要 MP4 輸出的編碼、幀率和文件命名。使用它設置您的首選 FPS 和交付的質量目標。
可選附加功能#
- 使用正面、均勻光照的參考圖像在簡單背景中獲得最佳效果。小旋轉或嚴重遮擋可能會削弱身份轉移。
- 保持提示簡潔;描述與您的參考相匹配的服裝、情感和照明。避免與 Wan2.1 Stand In 信號相抵觸的面部描述符。
- 如果 VRAM 緊張,先增加塊交換或降低分辨率。如果有空間,嘗試在增強步驟之前啟用加載器堆棧中的編譯優化。
- Stand In LoRA 是非標準的,必須在模型加載時連接;請遵循此圖中的模式以保持身份穩定。LoRA 文件:Stand-In
- 對於高級控制,啟用 VACE 路徑以使用指南剪輯指導運動。如果您希望僅使用 Wan 2.1 的文本驅動運動,請從不啟用它開始。
資源
- Wan 2.1 14B T2V: Hugging Face
- Wan 2.1 VACE: Hugging Face
- Stand In LoRA: Hugging Face
- LightX2V Step-Distill LoRA: Hugging Face
- UMT5-XXL encoder: Hugging Face
- WanVideo 包裝節點: GitHub
- KJNodes 工具用於調整大小、填充和遮罩: GitHub
- ControlNet Aux 預處理器(MediaPipe Face Mesh, DWPose): GitHub
致謝#
此工作流程實現並建立在 ArtOfficial Labs 的作品和資源之上。我們感謝 ArtOfficial Labs 和 Wan 2.1 作者為 Wan2.1 Demo 所做的貢獻和維護。欲了解權威細節,請參考以下鏈接的原始文檔和資料庫。
資源#
- Wan 2.1/Wan2.1 Demo
- 文檔 / 發布說明: Wan2.1 Demo
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款的約束。


