
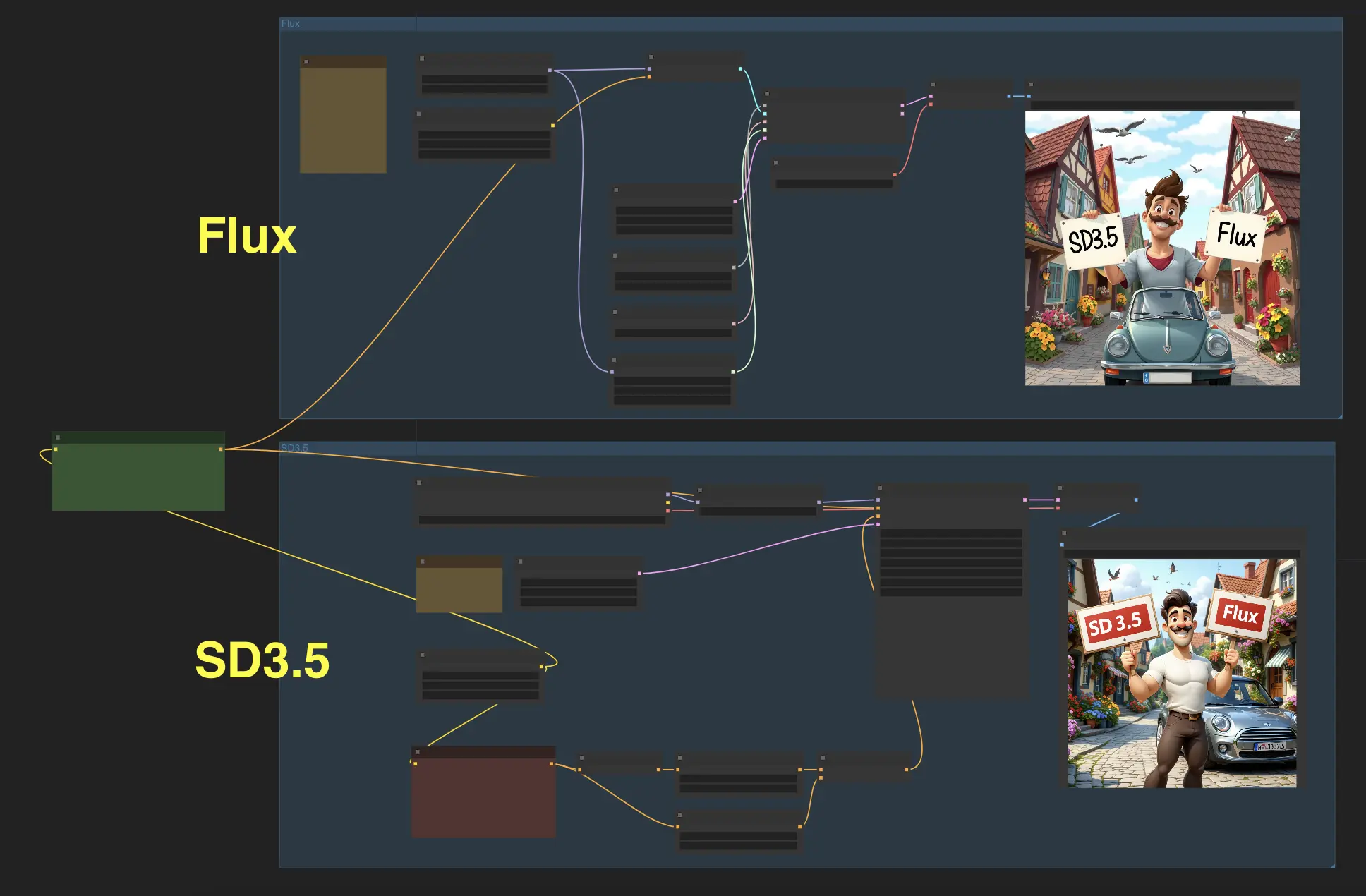

Stable Diffusion 3.5 VS FLUX.1#
準備好見證兩個尖端模型的驚人能力:Stable Diffusion 3.5 (SD3.5) 和 FLUX.1?通過這個ComfyUI工作流程,您可以現在輸入文本提示,並同時使用這兩個模型生成圖像,讓您比較結果並選擇您最喜歡的。
我們已經使用SD3.5-large和Flux.1-schnell測試了一些案例,結果顯示Stable Diffusion 3.5 (SD3.5) 和 FLUX.1在不同領域各有優勢。雖然FLUX.1在生成寫實圖像方面具有優勢,但SD3.5在生成動漫風格作品方面表現出更高的熟練度,無需額外的微調或修改。
不僅僅是聽我們說——親自體驗這種魔力!






