
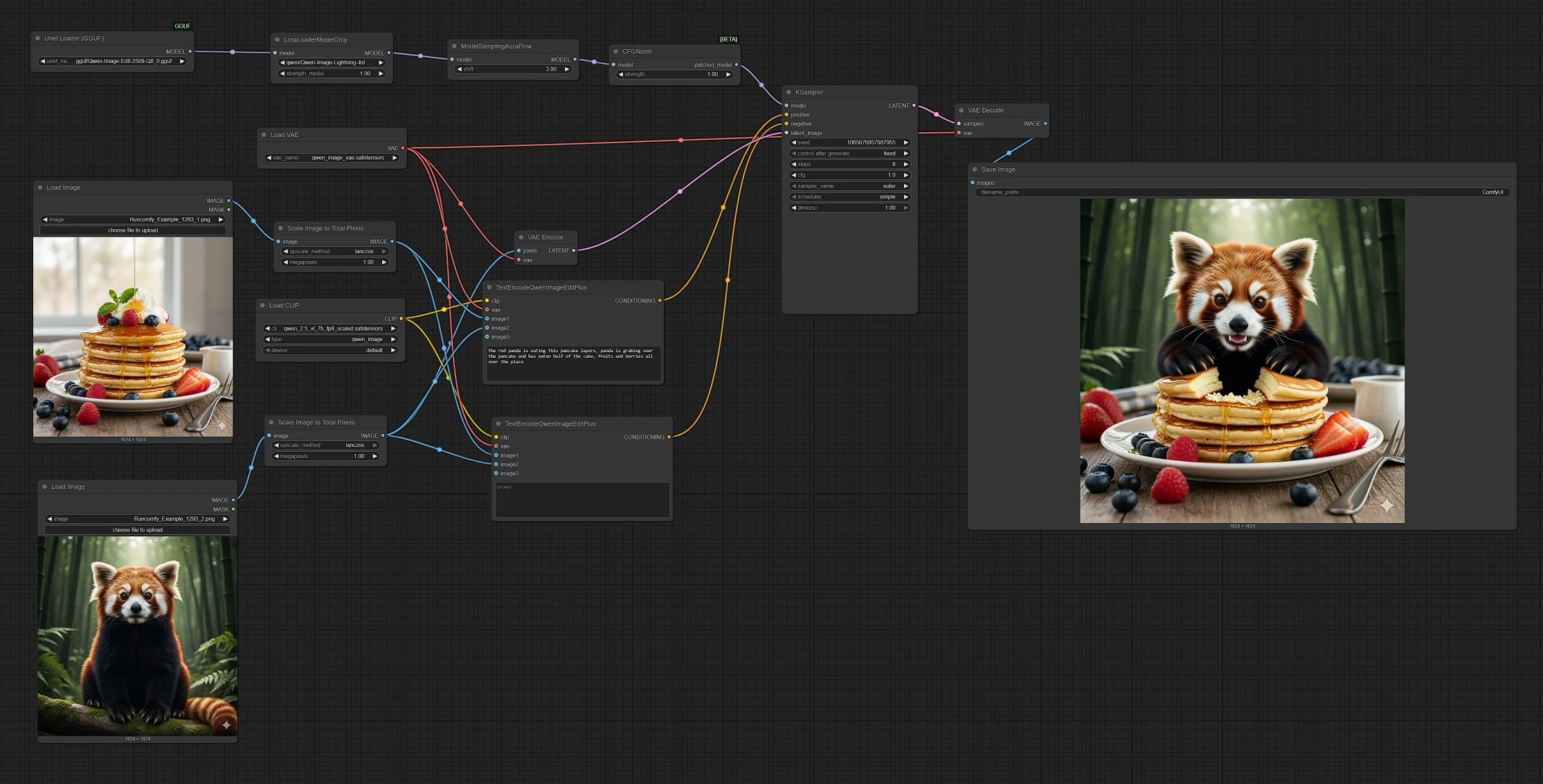






Qwen Image Edit 2509: 用於 ComfyUI 的多圖像、提示驅動編輯和混合#
Qwen Image Edit 2509 是一個用於 ComfyUI 的多圖像編輯工作流程,將 2–3 張輸入圖像融合在一個單一提示下,創造精確的編輯和無縫的混合。它是為希望合成物件、重新設計場景、替換元素或合併參考的創作者設計的,同時保持控制的直覺性和可預測性。
此 ComfyUI 圖表將 Qwen 圖像模型與編輯感知的文本編碼器配對,讓您可以使用自然語言和一個或多個視覺參考來引導結果。開箱即用,Qwen Image Edit 2509 處理風格轉移、物件插入和場景混合,即使來源的外觀或質量不同,仍能產生一致的結果。
Comfyui Qwen Image Edit 2509 工作流程中的關鍵模型#
- Qwen Image Edit 2509 (Diffusion Model & GGUF, Q8_0)。主要的圖像編輯檢查點,以量化形式加載以減少 VRAM 同時保留編輯行為。它提供了在採樣期間解釋文本和參考圖像的擴散骨幹。
- Qwen Image VAE。為 Qwen Image 專門設計的 VAE,將基礎畫布編碼到潛在空間,並將最終結果解碼回像素。資產來源:Comfy-Org/Qwen-Image_ComfyUI。
- Qwen 2.5 VL 7B 文本編碼器 (FP8 scaled)。為 ComfyUI 打包的視覺語言文本編碼器,將您的提示加上參考圖像轉化為編輯條件。資產來源:Comfy-Org/Qwen-Image_ComfyUI。
- Qwen‑Image‑Lightning‑4steps‑V1.0 LoRA。可選的 LoRA,將模型偏向快速、高影響力的更新,適用於快速迭代或低步數。模型頁面:lightx2v/Qwen-Image-Lightning。
如何使用 Comfyui Qwen Image Edit 2509 工作流程#
此工作流程遵循從輸入到輸出的清晰路徑:您加載 2–3 張圖像,編寫提示,圖表會編碼文本和參考,採樣在潛在基礎上運行,結果被解碼並保存。
階段 1 — 加載並調整您的來源
- 使用
LoadImage(#103) 加載圖像 1,使用LoadImage(#109) 加載圖像 2。圖像 2 作為基礎畫布,將接收編輯。 - 每張圖像都通過
ImageScaleToTotalPixels(#93 和 #108),因此兩個參考共享一致的像素預算。這穩定了合成和風格轉移。 - 如果您需要第三個參考,將另一個
LoadImage插入編碼節點上的image3輸入。Qwen Image Edit 2509 最多接受三張圖像以獲得更豐富的指導。
階段 2 — 編寫提示並設置意圖
- 正向編碼器
TextEncodeQwenImageEditPlus(#104) 將您的文本提示與圖像 1 和圖像 2 結合,以描述您想要的結果。使用自然語言請求合併、替換或風格提示。 - 負向編碼器
TextEncodeQwenImageEditPlus(#106) 讓您遠離不需要的細節。保持空白以保持中立,或添加抑制不需要的工件或風格的短語。 - 兩個編碼器都使用 Qwen 文本編碼器和 VAE,因此模型將您的參考視為指令的一部分。
階段 3 — 準備模型
UnetLoaderGGUF(#102) 以 GGUF 格式加載 Qwen Image Edit 2509 骨幹以進行高效推理。LoraLoaderModelOnly(#89) 應用 Qwen‑Image‑Lightning LoRA。增加其影響力以強化編輯,或減少以獲得更保守的更新。- 然後模型準備好進行採樣,配置調整為編輯穩定性。
階段 4 — 引導生成
- 基礎畫布(圖像 2)由
VAEEncode(#88) 編碼並提供給KSampler(#3) 作為起始潛在。這使得運行從圖像到圖像,而非純文本到圖像。 KSampler(#3) 將正向和負向條件與潛在畫布融合,以產生編輯結果。鎖定種子以確保可重現性,或改變以探索替代方案。- 指導和採樣選擇平衡了對來源的忠實性與提示遵從性,賦予 Qwen Image Edit 2509 精確性和靈活性的結合。
階段 5 — 解碼並保存
VAEDecode(#8) 將最終潛在轉換為圖像,並由SaveImage(#60) 寫入您的輸出文件夾。文件名反映運行,以便您可以輕鬆比較版本。
Comfyui Qwen Image Edit 2509 工作流程中的關鍵節點#
TextEncodeQwenImageEditPlus (#104)#
此節點通過 Qwen 編碼器將您的提示與最多三張參考圖像結合,創建正向編輯條件。用於指定應出現的內容、應採用的風格以及參考應如何強烈影響結果。從明確的單句目標開始,然後根據需要添加風格描述符或攝影機提示。編碼器的資產打包在 Comfy-Org/Qwen-Image_ComfyUI。
TextEncodeQwenImageEditPlus (#106)#
此節點形成負向條件以防止不需要的特徵。添加阻止工件、過度平滑或不匹配風格的短語。保持簡單以避免與正向意圖對抗。它使用與正向路徑相同的 Qwen 編碼器和 VAE 堆疊。
UnetLoaderGGUF (#102)#
在 GGUF 格式中加載 Qwen Image Edit 2509 檢查點以進行 VRAM 友好的推理。較高的量化節省記憶體,但可能稍微影響細節;如果有空間,嘗試較不激進的量化以最大化保真度。實現參考:city96/ComfyUI-GGUF。
LoraLoaderModelOnly (#89)#
在基礎模型上應用 Qwen‑Image‑Lightning LoRA,以加速收斂和加強編輯。增加 strength_model 以強調此 LoRA 的效果,或降低以獲得細微的指導。模型頁面:lightx2v/Qwen-Image-Lightning。核心節點參考:comfyanonymous/ComfyUI。
ImageScaleToTotalPixels (#93, #108)#
使用高質量重採樣將每個輸入調整到一致的總像素數。提高目標百萬像素會在時間和記憶體的代價下產生更清晰的結果;降低它可以加速迭代。保持兩個參考在相似的尺度上,以幫助 Qwen Image Edit 2509 乾淨地混合元素。核心節點參考:comfyanonymous/ComfyUI。
KSampler (#3)#
運行擴散步驟,根據您的條件轉換潛在畫布。調整步驟和採樣器以平衡速度和保真度,並變化種子以探索相同設置中的多個組合。對於保留圖像 2 結構的緊密編輯,保持步數適中,並依賴提示和參考進行控制。核心節點參考:comfyanonymous/ComfyUI。
可選附加功能#
- 將圖像 2 視為畫布,圖像 1 視為捐贈者;在提示中描述應轉移哪些元素,哪些應保留。
- 使用簡潔的負面來抑制光暈、紋理漂移或過度風格化;長的負面列表可能與您的目標相衝突。
- 如果結果顯得過於保守,稍微增加 LoRA 強度或採樣步驟;如果它們過於偏離基礎,則減少它們。
- 在完成時提高目標百萬像素,然後重用相同的種子以放大您喜歡的精確組合。
- 保持提示具體:主題、動作、設置和風格。Qwen Image Edit 2509 最能響應清晰的意圖和少量強烈的描述符。
鳴謝#
此工作流程實現並基於以下作品和資源。我們感謝 RobbaW 為 Qwen Image Edit 2509 工作流程的貢獻和維護。欲了解權威詳情,請參閱以下鏈接的原始文檔和資源庫。
資源#
- RobbaW/Qwen Image Edit 2509 工作流程
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- 文檔 / 發布說明: Qwen Image Edit 2509 工作流程 @RobbaW from Reddit r/comfyui
注意:使用所引用的模型、數據集和代碼需遵循其作者和維護者提供的相應許可和條款。

