
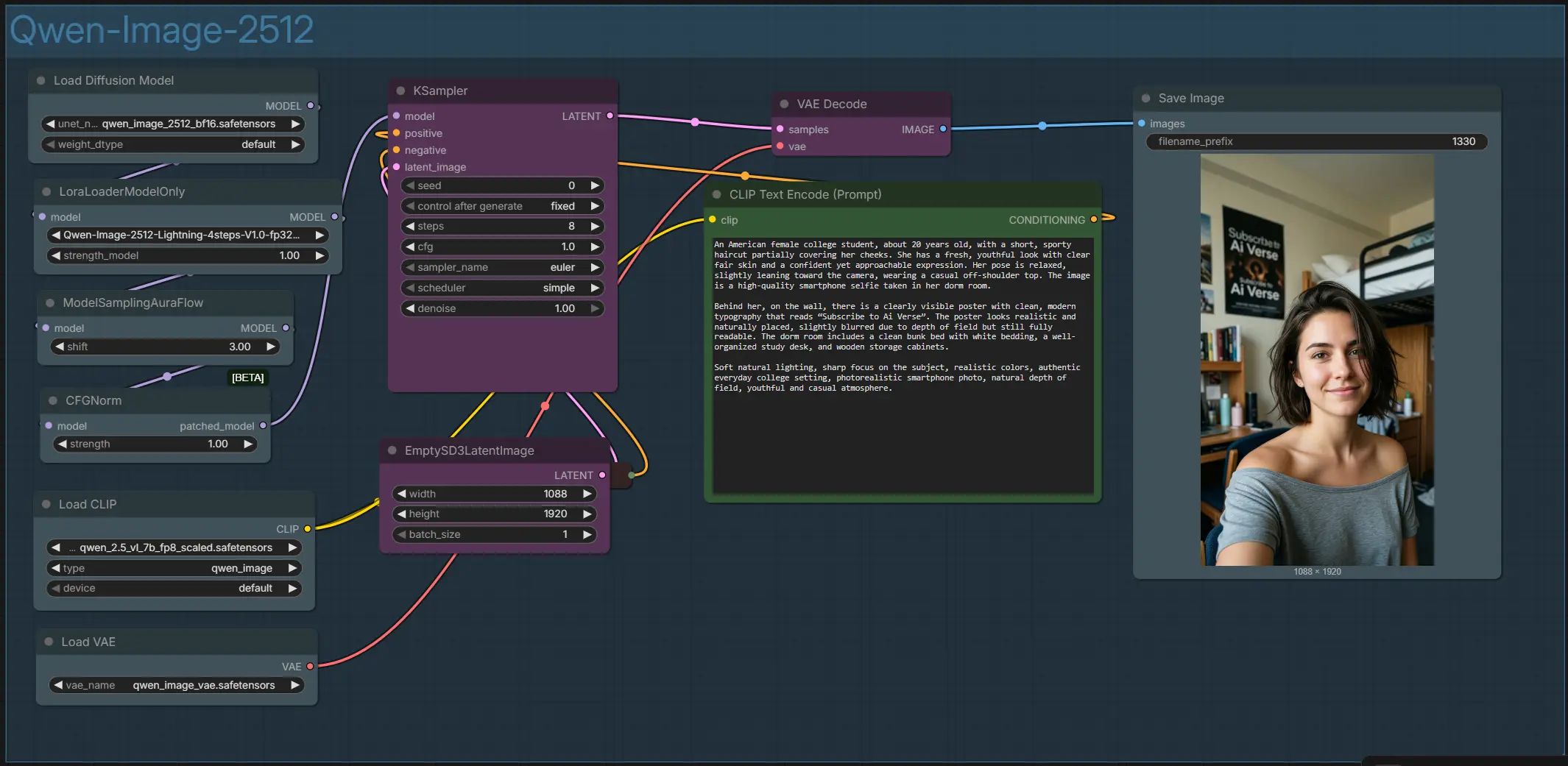






Qwen Image 2512 ComfyUI 工作流程,用於文本精準的人物肖像和場景#
此工作流程使用 Qwen Image 2512 將您的提示轉換為高保真圖像。專為需要強文本到圖像對齊、現實人物和場景內可靠雙語文本呈現的創作者設計。圖形預先連接了 Qwen 的 VAE 和文本編碼器,以及可選的 Lightning LoRA 用於少步驟生成,因此您可以以最小的設置從提示轉換到結果。
可用於概念藝術、插圖、標牌、海報和日常照片風格。Qwen Image 2512 帶來穩定的構圖和清晰的排版,使其成為混合人物、環境和可讀文本的提示的理想選擇。
Comfyui Qwen Image 2512 工作流程中的關鍵模型#
- Qwen-Image 2512 基礎模型 (bfloat16)。核心擴散模型,從條件合成圖像。Comfy-Org 套件中提供了 Comfy-ready 權重。模型文件
- Qwen2.5-VL 7B 文本編碼器。將您的提示編碼為驅動 Qwen Image 2512 的佈局、風格和文本呈現的條件向量。文本編碼器文件
- Qwen Image VAE。將由採樣器產生的潛在解碼回 RGB 圖像,保留真實的顏色和細節。VAE 文件
- Qwen-Image-2512-Lightning-4steps-V1.0 LoRA (可選)。一個社區 LoRA,針對少步驟生成進行調整,以加快渲染速度,並進行輕微的質量權衡。LoRA 卡
- 有關模型家族和訓練方法的背景,請參見 Qwen-Image 技術報告。論文
如何使用 Comfyui Qwen Image 2512 工作流程#
整體流程:您的提示被編碼,選擇的分辨率上創建一個潛在畫布,模型堆疊應用基礎模型和可選的 LoRA,採樣器迭代以優化潛在,然後 VAE 解碼最終圖像以保存。
- Qwen-Image-2512 群組概述
- 整個圖形組織在一個名為 “Qwen-Image-2512” 的單一群組中。它將文本編碼器、模型和 LoRA 堆疊、採樣輔助和 VAE 解碼連接在一起。您可以通過正面和負面提示、畫布大小和一些採樣器設置來控制外觀。輸出是一個高分辨率的人像風格圖像,保存到您的 ComfyUI 輸出文件夾中。
- 使用
CLIPTextEncode(#52) 和可選的負面CLIPTextEncode(#32) 提示- 在
CLIPTextEncode(#52) 中輸入您的主要描述。編寫場景、主題和您希望呈現的任何圖像內文本;Qwen Image 2512 對標牌、海報、UI 模擬和雙語字幕特別強。使用CLIPTextEncode(#32) 進行可選的負面,以避免產生文物或不需要的風格。如果需要精確的措辭,請將文本片段放在引號內。
- 在
- 使用
EmptySD3LatentImage(#57) 設置畫布和縱橫比- 在這裡選擇您的目標寬度和高度以設置構圖。人像格式適合人物和自拍,而方形和橫向比例適合產品和場景佈局。較大的畫布會在記憶體和時間上帶來更高的細節;在您喜歡框架後再開始擴大。保持相同的縱橫比可以提高一致性。
- 使用
UNETLoader(#100) 和LoraLoaderModelOnly(#101) 的模型和 LoRA 堆疊- 基本生成器是由
UNETLoader(#100) 加載的 Qwen Image 2512。如果您想更快地渲染,啟用LoraLoaderModelOnly(#101) 中的 Lightning LoRA,以切換到少步驟工作流程。此堆疊在採樣開始之前設置模型的現實主義、佈局和文本到圖像對齊能力。
- 基本生成器是由
- 使用
ModelSamplingAuraFlow(#43) 和CFGNorm(#55) 的採樣輔助- 這兩個節點準備模型進行穩定、對比平衡的採樣。
ModelSamplingAuraFlow(#43) 調整計劃以保持細節清晰而不過度處理紋理。CFGNorm(#55) 正規化指導,以在遵循您的提示時保持一致的顏色和曝光。
- 這兩個節點準備模型進行穩定、對比平衡的採樣。
- 使用
KSampler(#54) 的去噪和精煉- 這是從噪聲到連貫圖像的迭代優化潛在的工作馬階段。您設置種子以提高可重複性,選擇採樣器和計劃器,並選擇運行的步數。啟用 Lightning 時,您可以目標少步驟;僅使用基礎模型時,使用更多步驟以獲得最大保真度。
- 使用
VAEDecode(#45) 和SaveImage(#117) 的解碼和保存- 採樣後,VAE 將潛在乾淨地重建為 RGB,並使用
SaveImage寫入最終的 PNG。如果顏色或對比看起來不對勁,請重訪指導或提示措辭,而不是後處理;Qwen Image 2512 對描述性照明和材質提示反應良好。
- 採樣後,VAE 將潛在乾淨地重建為 RGB,並使用
Comfyui Qwen Image 2512 工作流程中的關鍵節點#
UNETLoader(#100)- 加載 Qwen-Image-2512 基礎模型,確定整體能力和風格空間。如果您的 GPU 允許,請使用 bf16 構建以獲得最大質量。僅在需要適應記憶體或提高吞吐量時切換到 fp8 或壓縮變體。
LoraLoaderModelOnly(#101)- 在基礎模型上應用 Qwen-Image-2512-Lightning-4steps-V1.0 LoRA。提高或降低
strength_model以將速度調整與基礎保真度融合,或將其設置為 0 以禁用。當此 LoRA 啟用時,減少KSampler中的steps到少數迭代以實現加速。
- 在基礎模型上應用 Qwen-Image-2512-Lightning-4steps-V1.0 LoRA。提高或降低
ModelSamplingAuraFlow(#43)- 修補模型的採樣行為,以獲得通常能產生更銳利邊緣和較少模糊的流式計劃。如果結果看起來過於銳化或細節不足,輕微調整
shift參數並重新採樣。在測試時保持其他變數穩定,以隔離效果。
- 修補模型的採樣行為,以獲得通常能產生更銳利邊緣和較少模糊的流式計劃。如果結果看起來過於銳化或細節不足,輕微調整
CFGNorm(#55)- 正規化無分類器指導,以防止洗白或過飽和的輸出。使用
strength決定正規化應該多麼積極地作用。如果文本精確性在提高 CFG 時下降,增加正規化強度而不是進一步提高 CFG。
- 正規化無分類器指導,以防止洗白或過飽和的輸出。使用
EmptySD3LatentImage(#57)- 設置定義框架和縱橫比的潛在畫布大小。對於人物,肖像比例減少失真,有助於身體比例;對於海報,方形或橫向比例強調佈局和文本塊。只有在對構圖感到滿意後才提高解析度。
CLIPTextEncode(#52) 和CLIPTextEncode(#32)- 正面編碼器 (#52) 將您的描述轉換為條件,包括要在場景中呈現的明確文本字串。負面編碼器 (#32) 抑制不需要的特徵,如文物、額外的手指或嘈雜的背景。保持提示簡潔和事實,以獲得最佳對齊。
KSampler(#54)- 控制種子、採樣器、計劃器、步驟、CFG 和去噪強度。使用 Qwen Image 2512 時,適度的 CFG 值通常能保持模型的強文本對齊;如果字母變形,請在更改採樣器之前降低 CFG。對於快速草稿,啟用 Lightning 並嘗試很少的步驟,然後在需要時增加步驟以獲得最終渲染。
VAELoader(#34) 和VAEDecode(#45)- 加載並應用 Qwen 的 VAE,以重建真實的顏色和細節。保持 VAE 與基礎模型配對,以避免顏色偏移。如果切換基礎權重,也切換到匹配的 VAE 構建。
可選附加#
- 圖像內文本的提示
- 用直引號括起確切的單詞,並添加簡短的排版提示,如 "乾淨現代的排版" 或 "粗體無襯線"。包括 "牆上海報" 或 "店面招牌" 等放置提示,以錨定文本應出現的位置。
- 使用 Lightning 快速迭代
- 啟用 Lightning LoRA 並使用少量步驟進行預覽。一旦框架和措辭正確,禁用或降低 LoRA 強度並增加步驟以恢復最大保真度。
- 縱橫比選擇
- 在變化中保持一致的比例。對於人物使用肖像,對於產品或標誌研究使用方形,對於環境或幻燈片使用橫向。如果您稍後放大,保持相同的比例以保持構圖。
- 指導紀律
- Qwen Image 2512 通常更喜歡適度的 CFG。如果文本保真度下降,降低 CFG 或增加
CFGNorm強度,而不是增加更多的指導。
- Qwen Image 2512 通常更喜歡適度的 CFG。如果文本保真度下降,降低 CFG 或增加
- 可重複性
- 當您喜歡某個結果時,鎖定一個種子,以便您可以安全地迭代。在繼續之前,一次更改一個控制,以了解其影響。
聲明#
此工作流程實施並基於以下作品和資源。我們感謝 Comfy-Org 提供的 Qwen Image 2512 模型文件的貢獻和維護。欲了解權威細節,請參考以下鏈接的原始文件和庫。
資源#
- Comfy-Org/Qwen Image 2512 模型文件
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- 文檔 / 發布說明: Qwen Image 2512 模型文件
注意:引用的模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款的約束。
