
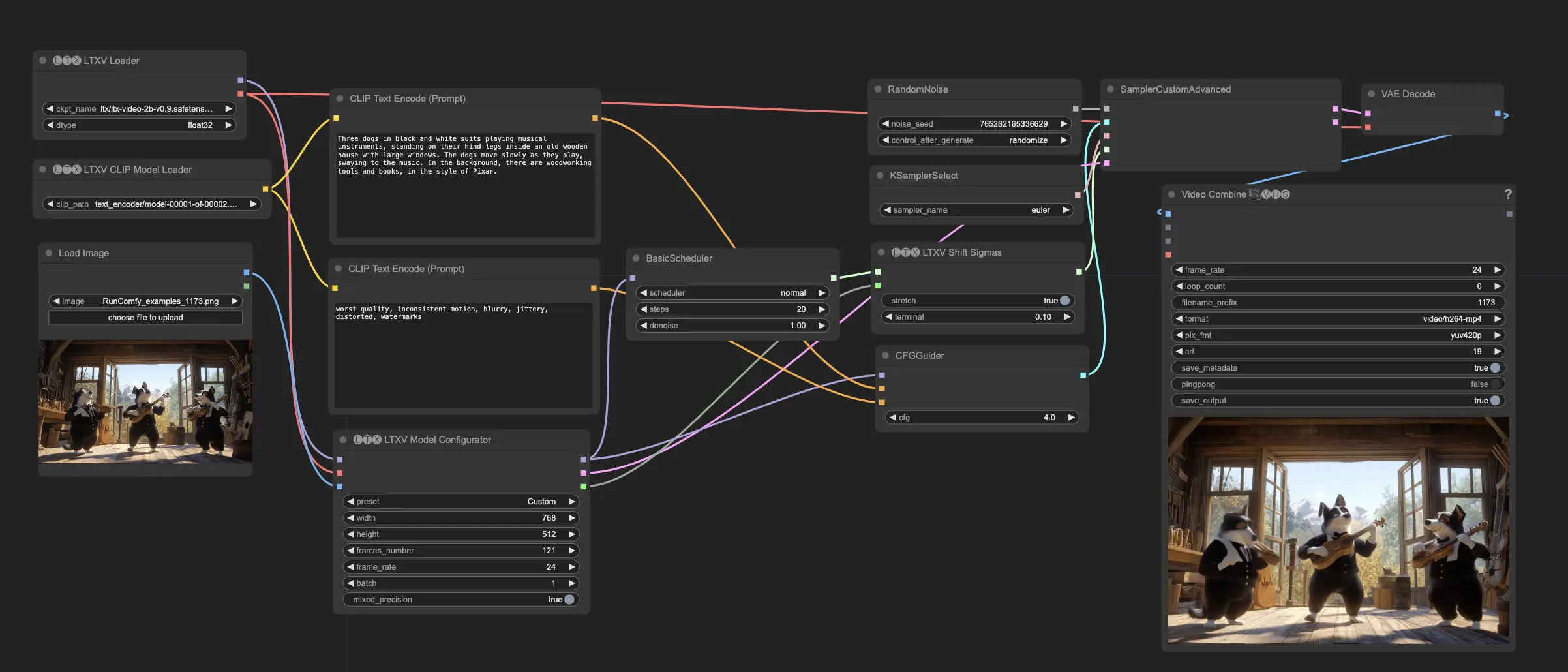
LTX Video 是由 Lightricks 開發的基於擴散技術的視頻生成模型。它能夠從文本提示(文本到視頻)或圖像和文本提示的組合(圖像+文本到視頻)生成視頻。LTX Video 以每秒 24 幀(FPS)的速度生成分辨率為 768x512 的視頻,比觀看速度更快。該模型已在包含多樣化視頻的大規模數據集上進行訓練,使其能夠以高分辨率生成逼真且多樣的視頻內容。
LTX Video Model 和 ComfyUI-LTXVideo Nodes 由 Lightricks 開發。所有功勞歸於他們在創建 LTX Video 上的工作。欲了解更多有關 LTX Video 和 Lightricks 項目的信息,請訪問他們的 GitHub 存儲庫:https://github.com/Lightricks/LTX-Video 或他們的網站:https://www.lightricks.com/ltxv。
LTX 模型背後的技術#
LTX Video 使用基於擴散的方式來生成視頻。擴散模型通過在多個時間步中逐步去噪聲來生成最終輸出。在 LTX Video 的情況下,模型將噪聲潛表示作為輸入,並通過迭代去噪聲來生成一系列視頻幀。去噪聲過程由提供的文本或圖像+文本提示引導,這些提示控制生成視頻的內容和風格。
LTX Video 採用的關鍵技術包括:
- 基於擴散的視頻生成:通過利用擴散模型,LTX Video 可以生成具有逼真運動和幀間一致性高質量視頻。
- 文本到視頻合成:LTX Video 可以僅基於文本描述生成視頻,使用戶能夠使用自然語言提示從頭創建自定義視頻。
- 圖像+文本到視頻合成:LTX Video 還支持通過結合初始圖像和文本提示生成視頻。這允許用戶提供視頻的起始點,並使用文本引導其內容和風格。
如何在 ComfyUI 中使用 LTX Video 工作流程#
- 準備輸入:
- 默認工作流程是圖像 + 文本到視頻生成。提供初始圖像以及文本提示。圖像作為起始點,模型將根據圖像和隨附的文本生成視頻。請注意,此模型需要長而具描述性的提示;如果提示過短,質量將大大下降。
- 配置模型參數:
- 設置生成內容所需的分辨率和幀數。分辨率應能被 32 整除,幀數應能被 8 + 1 整除(例如,257 幀)。LTX 在分辨率低於 720x1280 像素和少於 257 幀的情況下效果最佳。
- 根據您的需求調整其他參數,如擴散步驟、噪聲計劃和指導尺度。這些參數控制生成輸出的質量和多樣性。
- 生成內容:
- 輸出將具有指定的分辨率和幀數,並將與提供的輸入提示一致。
LTX 模型的限制#
- LTX Video 不旨在或無法提供事實信息。
- 作為統計模型,LTX Video 可能會放大訓練數據中存在的現有社會偏見。
- 生成的視頻可能與提供的提示不完全匹配。
- 提示跟隨的質量在很大程度上取決於使用的提示風格。
許可證#
請根據 **許可證** 使用該模型