
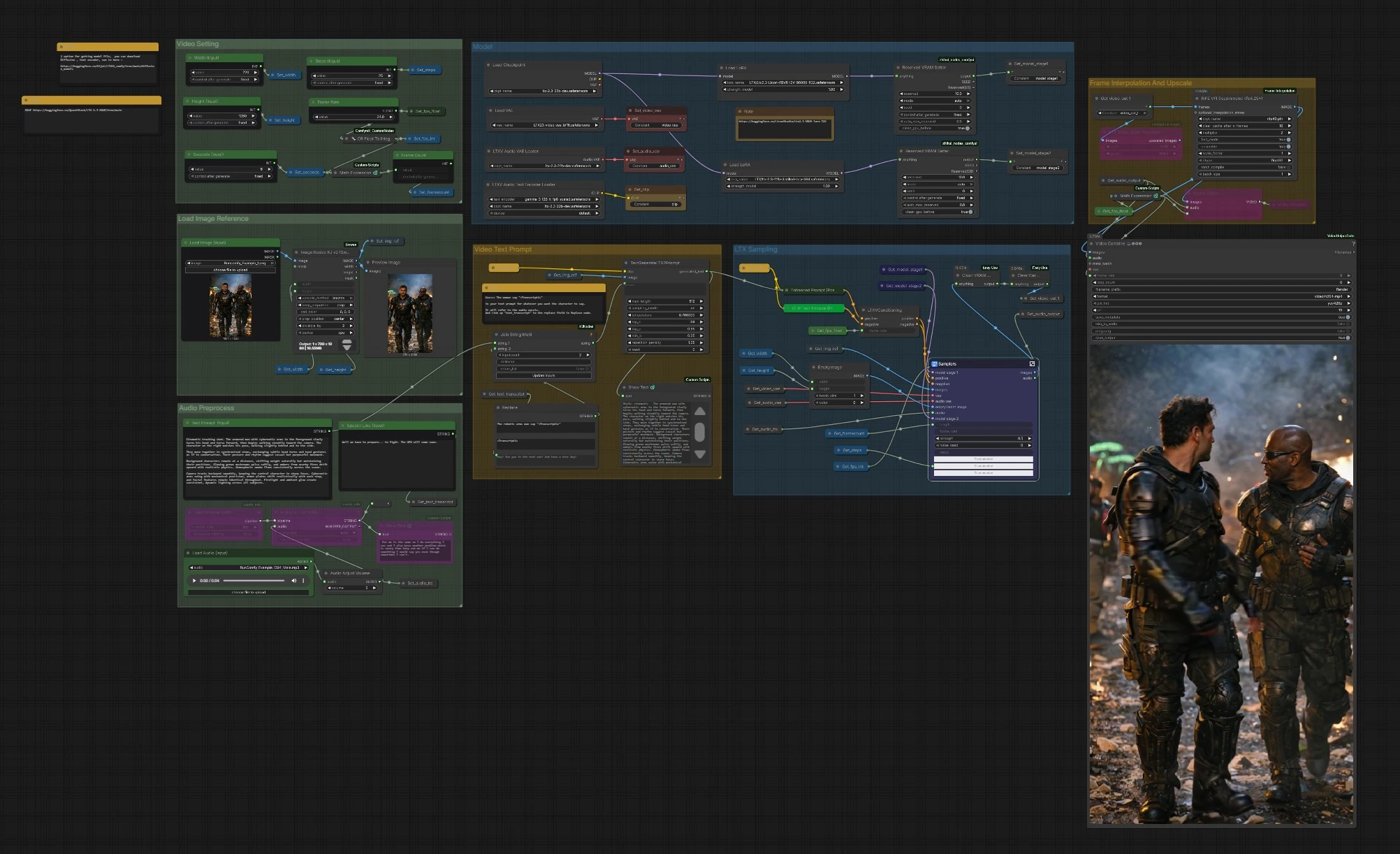
LTX 2.3 VBVR ComfyUI 工作流程:考慮推理的圖像到視頻轉換,帶有對話#
此工作流程將單個參考圖像轉換為由文本和可選語音引導的連貫視頻序列,由 LTX‑2.3 和 LTX 2.3 VBVR LoRA 驅動。VBVR 代表基於視頻的視覺推理:它幫助模型在幀之間保持身份、一致的空間關係和因果關係,使您的場景感覺有意圖而非隨機。圖形包括語音感知提示、兩階段 LTX 取樣、運動平滑和最終升級/導出到 MP4。
需要敘述連續性、可信運動或對話時間的創作者會發現 LTX 2.3 VBVR 工作流程特別有用。提供強大的參考幀,描述動作和交互,並可選地插入一條自動轉錄並融入提示的語音,以便更好地對齊唇形和時間。
Comfyui LTX 2.3 VBVR 工作流程中的關鍵模型#
- LTX‑2.3 22B 視頻生成模型來自 Lightricks,是圖像到視頻和音頻條件解碼的主要擴散骨幹。Hugging Face: Lightricks/LTX-2.3
- LTX‑2.3 視頻 VAE 用於編碼/解碼視頻潛在變量,與基礎檢查點配對以實現高效平鋪解碼。Hugging Face: Lightricks/LTX-2.3
- LTX‑2.3 空間升級 x2 潛在模型在第一次通過後增強空間細節。Hugging Face: Lightricks/LTX-2.3
- Gemma 3 12B 文本編碼器為 LTX‑2 打包,在此用於解析複雜的指令和對話標記。Hugging Face: Comfy-Org/ltx-2
- LTX 2.3 VBVR LoRA 用於推理為中心的場景結構、物體交互和時間上的連續性。Hugging Face: LiconStudio/Ltx2.3-VBVR-lora-I2V
- RIFE 幀插值模型用於平滑生成幀之間的運動。GitHub: hzwer/Practical-RIFE
- Whisper 語音識別模型用於可選的音頻到文本提示融合。GitHub: openai/whisper
如何使用 Comfyui LTX 2.3 VBVR 工作流程#
圖形組織成清晰的組。您配置輸入、模型堆棧和視頻設置,然後 LTX 取樣器生成幀,這些幀可以選擇性地插值和升級後導出。
加載圖像參考#
使用 Load Image (Input) (#5525) 選擇一個強烈的、風格一致的參考幀。圖像由 ImageResizeKJv2 (#5280) 調整為您選擇的寬度和高度,同時保留構圖。預覽節點確認模型實際會看到什麼。好的參考圖像具有清晰的主題和光線,為 LTX 2.3 VBVR 堆棧提供可靠的身份和風格錨點。
視頻設置#
設置 Width (Input) (#5284)、Height (Input) (#5286)、Seconds (Input) (#5573) 和基本 Frame Rate (#5289)。圖形自動計算幀數,這樣當您改變持續時間或 fps 時,時間保持一致。如果您計劃稍後啟用插值,您可以選擇適度的基礎 fps 以節省時間並讓 RIFE 添加平滑度。這些設置還通知條件節點,以便運動和節奏保持一致。
模型#
CheckpointLoaderSimple (#5493) 加載 LTX‑2.3。圖形通過 LoraLoaderModelOnly (#5616) 附加 LTX 2.3 VBVR LoRA,並可選地應用一個蒸餾 LoRA 和一個細節 LoRA 以增強保真度。LTXAVTextEncoderLoader (#5494) 引入基於 Gemma 的文本編碼器,而 VAELoader (#5629) 和 LTXVAudioVAELoader (#5492) 提供視頻和音頻 VAE。兩個 ReservedVRAMSetter 節點平衡內存使用,以便長時間運行保持穩定。
視頻文本提示#
在 Text Prompt (Input) (#5620) 中編寫您的場景。要注入與音頻對齊的對話,請包括如下佔位符:The woman says "<Transcript1>"。將實際台詞輸入 Speech Line (Input) (#5524) 或讓 Whisper 從音頻中生成;StringReplace (#5226) 和 JoinStringMulti (#5602) 將 <Transcript1> 替換為轉錄。TextGenerateLTX2Prompt (#5488) 然後組成一個精煉的指令,Enhanced Prompt (Positive) (#5174) 在 LTXVConditioning (#5173) 準備最終指導之前編碼。清晰的動詞、主題參考和空間提示給 LTX 2.3 VBVR LoRA 提供它需要的上下文以便在時間上進行推理。
音頻預處理#
使用 Load Audio (Input) (#5590) 或連接 TTS 帶入音軌。AudioAdjustVolume (#5601) 正規化音量水平。如果您想要提示感知對話,使用 Whisper 通過 Load Whisper (mtb) (#5606) 和 Audio To Text (mtb) (#5607) 生成用於提示的轉錄。同一音頻也被編碼為潛在變量,稍後將重新混合回最終視頻中,以便唇形和時間提示可以影響生成。
LTX 取樣#
LTXVPreprocess (#5240) 和 LTXVImgToVideoInplace (#5245) 將您的參考幀轉換為初始潛在序列,保留核心身份同時允許運動。Samplers 子圖 (#5278) 使用 CFG 引導器和調度器運行兩階段過程,生成尊重您的提示和 LTX 2.3 VBVR 推理 LoRA 的時空潛在變量。音頻潛在變量與視頻潛在變量串聯,以便語音時間可以信息運動。LTXVSpatioTemporalTiledVAEDecode (#5237) 解碼幀,LTXVAudioVAEDecode (#5103) 恢復音頻軌道。
幀插值和升級#
RIFE VFI (#5554) 在幀之間插值以創建更平滑的運動,並在與基礎 fps 結合時達到目標播放率。RTXVideoSuperResolution (#5631) 增強細節並減少壓縮伪影,提高面部、邊緣和小道具的可讀性。使用此階段平衡速度和質量:插值以獲得平滑性,然後升級以獲得清晰度。
導出#
選擇 CreateVideo (#5599) 進行簡單的混合或 VHS_VideoCombine (#5618) 以獲得更多對格式、元數據和修剪的控制。管道通過 SaveVideo (#5597) 寫入 H.264 MP4。幀率來自您的設置和插值階段,因此播放與您在開始時設計的運動意圖匹配。
Comfyui LTX 2.3 VBVR 工作流程中的關鍵節點#
LoraLoaderModelOnly (#5616)#
加載 LTX 2.3 VBVR LoRA,提高邏輯連續性、物件交互和攝像頭感知運動。調整 LoRA 權重以平衡推理影響與來自基礎模型和其他 LoRA 的風格。此節點是 LTX 2.3 VBVR 工作流程定義的獨特外觀和連貫性的核心。對於 LTX 節點和 LoRA 使用,請參見 Lightricks/ComfyUI-LTXVideo 和上面的 VBVR LoRA 卡。
TextGenerateLTX2Prompt (#5488)#
通過合併您的基礎描述、圖像參考和從 <Transcript1> 替換的對話標記來組裝最終的正面提示。保持指令簡潔、明確,並在主題和行動上保持一致,以便模型能夠在時間上進行推理。這是您編碼意圖的地方,LTX 2.3 VBVR LoRA 將在取樣期間加強這一意圖。
LTXVConditioning (#5173)#
打包正面和負面條件並轉發時間信息,以便運動和節奏與您的 fps 選擇對齊。如果您在設置中更改幀率,請在此更新以保持運動動態一致。強烈的負面幫助防止靜止幀、水印或不需要的覆蓋層潛入序列。
Samplers (#5278)#
兩階段取樣器塊協調噪聲、指導和調度,將圖像和音頻潛在變量轉換為連貫視頻。最具影響力的調整是總的 steps,初始 I2V 階段的 image strength,以及 noise_seed 用於再現性。仔細調整這些以在參考幀的保真度和願意遵循新的運動和行動之間進行權衡。
RIFE VFI (#5554)#
插值幀以獲得更平滑的運動或在不重新生成序列的情況下達到更高的有效 fps。當您的基礎 fps 較低或運動感覺卡頓時,增加插值;減少插值以保持原始生成節奏。該模型廣泛用於高質量的 VFI;參見 RIFE 項目在 GitHub。
可選附加功能#
- 使用 LTX 2.3 VBVR 的對話技巧:寫一個自然的句子,帶有佔位符,例如 The woman says "<Transcript1>",然後在 Speech Line 中提供台詞或讓 Whisper 轉錄音頻,以便提示和唇形對齊。
- 推理提示:指出誰在做什麼、在哪裡和為什麼。使用一致的主題名稱和時間提示,例如然後、同時和攝像機移動時,以利用 VBVR 的優勢。
- 更快的迭代:從較短的持續時間或較低的基礎 fps 開始,確認運動節拍,然後增加插值或秒數以完成。
- 穩定性提示:如果您看到身份漂移,稍微降低圖像到視頻的強度或提高 VBVR LoRA 的權重;如果您看到過度約束,則反之。
致謝#
此工作流程實施並構建在以下作品和資源之上。我們感謝 @Benji’s AI Playground 提供的 2.3 VBVR 工作流程源的貢獻和維護。關於權威詳細信息,請參閱下文鏈接的原始文檔和存儲庫。
資源#
- LTX/2.3 VBVR 工作流程源
注意:使用參考的模型、數據集和代碼需遵循其作者和維護者提供的各自許可和條款。
