
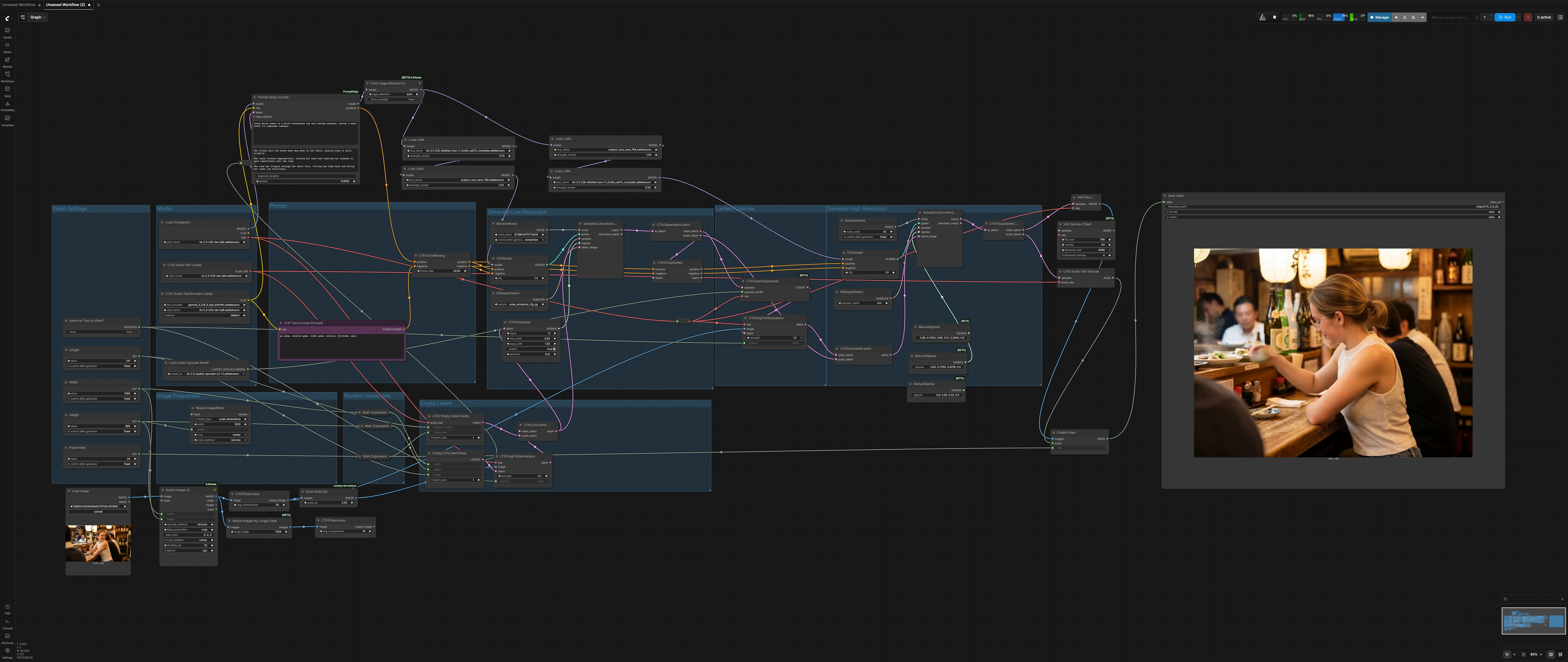
LTX 2.3 Sulphur 圖像轉影片工作流程:可控運動的電影圖像轉影片#
此 LTX 2.3 Sulphur 圖像轉影片工作流程將單一靜態影像轉換為發佈準備就緒的電影鏡頭,具有自然的微表情、可信的角色運動和穩定的氣氛連續性。它專為故事鏡頭設計,讓您在不迷失於設置細節的情況下控制攝影機感覺、情感和場景動態。
該工作流程運行一個圍繞 LTX-2.3 的兩階段擴散管線:低解析度通道建立運動和時間,隨後是潛在放大和高解析度精細通道以達到最終細節。Sulphur 風格 LoRA 引導外觀和膚色,而提示分割支持鏡頭中的變化節奏。只需切換一個開關即可根據需要運行經典圖像到影片或純文本到影片。
Comfyui LTX 2.3 Sulphur 圖像轉影片工作流程的關鍵模型#
- Lightricks LTX-2.3-22B dev FP8。基礎影片擴散檢查點,驅動生成和解碼,同時保持記憶體使用實際。Model card
- LTX-2.3 空間放大器 x2。在通道之間使用的潛在超解析度模型,以在增加空間保真度的同時保留運動。Model page
- Gemma 3 12B 指令調整文本編碼器,為 LTX-2 包裝。啟用豐富的、基於實地的條件設定,用於全局和分段提示。Repository
- Sulphur 風格 LoRA 和 LTX-2.3 蒸餾 LoRA 1.1。配對的 LoRA 穩定面部真實感和電影色調,同時保留提示控制。
如何使用 Comfyui LTX 2.3 Sulphur 圖像轉影片工作流程#
整體流程:設置鏡頭尺寸和長度,準備您的靜態影像,定義全局提示以及可選的本地提示節拍,然後渲染。低解析度階段建立運動和時間,潛在放大器提升細節,並在解碼到 MP4 之前完成高解析度階段的紋理和照明。
影片設置#
選擇您的目標 寬度、高度、長度(幀數)和 幀率。尺寸設置為可被常見擴散網格尺寸整除以避免伪影。單一布林型,切換到文本到影片?(#28),控制是否注入靜態影像或繞過。保持輸入影像的一致縱橫比,以獲得最乾淨的構圖,尤其是面部和手部。
圖像預處理#
您的源靜態影像會被加載、調整大小並輕微壓縮,以便為擴散做好準備,使用 ImageResizeKJv2(#75)和 LTXVPreprocess(#76)。縮放版本被饋送到低解析度階段以穩定運動種子,而更高細節版本可用於高解析度階段。使用此部分在生成之前對齊構圖和頭部空間。這裡的微妙預裁剪調整在更一致的眼線和背景連續性中帶來回報。
空潛在#
EmptyLTXVLatentVideo(#21)和 LTXVEmptyLatentAudio(#33)使用您的鏡頭設置構建同步的影片和音頻潛在變量。它們通過 LTXVConcatAVLatent(#32)合併,以建立下游節點將精細化的時間軸框架。音頻分支創建一個靜音、有效的音軌,以便最終的 MP4 在任何地方可靠播放。這些潛在變量還錨定提示段,以便運動變化落在您期望的位置。
提示#
在 PromptRelayEncode(#80)中撰寫您的鏡頭描述。使用簡潔的全局提示來獲得整體外觀,然後添加節奏特定的行作為本地提示,以 | 字符分隔,以便在剪輯中展開微動作。來自 LTXAVTextEncoderLoader(#5)的 LTX 文本編碼器處理語義,而 CLIPTextEncode(#41)提供強大的現實導向負面提示。LTXVConditioning(#31)混合正面和負面條件設定,並與幀率同步。
模型#
CheckpointLoaderSimple(#44)加載 LTX-2.3 基礎。PathchSageAttentionKJ(#67)優化大圖像的注意力。短 LoRA 鏈在每個採樣階段之前應用 Sulphur 風格和蒸餾穩定性 LoRA。此設計在外觀一致性和提示響應性之間取得平衡,因此角色身份和照明在通道之間保持一致。
生成低解析度#
此首個擴散階段建立運動。LTXVImgToVideoInplace(#22)將您的預處理靜態影像注入時間軸;如果 切換到文本到影片? 啟用,其 bypass 輸入可乾淨地禁用圖像注入以獲得純 T2V。LTXVScheduler(#47)塑造西格瑪計劃以控制運動幅度和時間平滑性。SamplerCustomAdvanced(#9)由 CFGGuider(#42)和 KSamplerSelect(#17)驅動,合成一致的低解析度 A/V 潛在變量。LTXVSeparateAVLatent(#35)然後分割影片和音頻路徑,並將構圖信息轉發給 LTXVCropGuides(#10)以進行引導感知的構圖。
潛在放大#
LTXVLatentUpsampler(#13)使用 LTX-2.3 空間放大器在潛在空間中提升空間細節,同時保留第一階段學習到的運動。此處的放大避免了重新發明時間,並減少了第二階段再生中常見的閃爍現象。它將更清晰、運動一致的潛在變量交給最終的精細階段。
生成高解析度#
精細階段通過 LTXVConcatAVLatent(#3)重新組合放大的影片潛在變量和音頻潛在變量。CFGGuider(#8)和 KSamplerSelect(#6)使用調整的西格瑪計劃引導 SamplerCustomAdvanced(#36)中的快速、細節導向採樣器進行完成。如果您啟用了圖像注入,則第二個 LTXVImgToVideoInplace(#14)可幫助模型在高解析度下尊重靜態,而不會丟失已建立的運動。結果是具有自然眼睛和嘴部動態的穩定電影序列。
輸出#
VAEDecode(#68)將最終影片潛在變量轉換為幀,而 LTXVAudioVAEDecode(#23)重建靜音音頻軌道。CreateVideo(#38)將幀和音頻以您選擇的幀率進行混合,並 SaveVideo(#45)寫入 H.264 MP4 以供立即查看和共享。使用每個鏡頭的描述性文件名前綴保持迭代有序。
數字轉換#
一個小型實用程序塊計算半比例尺寸以進行潛在構建,以管理 VRAM 和速度。您通常不需要觸及這些,但它們確保上游寬度和高度一致地驅動一切。如果您更改基礎解析度,這些會自動適應。
Comfyui LTX 2.3 Sulphur 圖像轉影片工作流程的關鍵節點#
PromptRelayEncode(#80)。集中化全局提示和按節拍的本地提示,與時間軸對齊。使用它來編寫微表情和小型攝影機揭示鏡頭。保持本地提示簡短和具體,以便它們補充而不是對抗全局外觀。LTXVImgToVideoInplace(#22, #14)。將靜態影像注入低解析度和高解析度潛在變量中。當您希望最終結果緊貼參考幀時,增加strength;減少它以獲得更多自由。bypass輸入連接到文本到影片開關,因此您可以乾淨地禁用圖像注入以進行 T2V 運行。LTXVScheduler(#47)。控制低解析度階段期間噪音水平的演變,這直接影響運動強度和平滑性。使用它來抑制過於活躍的鏡頭或在感覺靜止時添加微妙的推動。此處的調整在面部、頭髮和手持式攝影機能量上最為明顯。LTXVLatentUpsampler(#13)。使用 LTX 的空間放大器進行 x2 潛在放大,保留第一階段學習的運動線索。使用它在高解析度精細化之前添加清晰的紋理和邊緣定義,而不重新設定時間。CFGGuider(#42, #8)。平衡模型如何強烈地遵循您的提示與其學習的先驗知識。如果面部漂移或風格減弱,增加指導;如果細節看起來過於強迫或塑料化,降低它。將更改與快速查看負面提示配對以保持現實。KSamplerSelect(#17, #6)。允許您為每個階段選擇採樣算法。為低解析度階段選擇一個強大、表現力豐富的採樣器,為完成階段選擇一個快速、細節友好的選項。在比較外觀時保持選擇一致。
可選附加項#
- 為了實現有意圖的攝影機行為,您可以在需要一致的側向推動時,將 LTX 系列的攝影機控制 LoRA(如 Dolly-Left)添加到您的 LoRA 加載器鏈中。Model page
- 保持寬度和高度可被 32 整除,以避免潛在操作中的對齊錯誤並維持 VRAM 效率。
- 在本地提示中使用簡短的、主動的動詞來編排節拍,例如緊握、轉身、微笑柔化。
- 如果您針對非常高的輸出尺寸,考慮將
VAEDecode換成VAEDecodeTiled(#43)以更高效地解碼幀。 - 當面部最重要時,通過僅調整提示文本和
CFGGuider進行迭代,然後再更改採樣器或解析度。這樣可以保持比較有意義並揭示 LTX 2.3 Sulphur 圖像轉影片工作流程的最佳措辭。
鳴謝#
此工作流程實現並建立在以下作品和資源之上。我們誠摯感謝 RunningHub 提供的工作流程參考,Lightricks 提供的 LTX 2.3 系列(模型、空間放大器和攝影機控制 LoRA),以及 Comfy-Org 提供的 LTX 文本編碼器,他們的貢獻和維護。欲了解權威詳細信息,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- RunningHub/RunningHub 工作流程參考
- Docs / Release Notes: runninghub.ai post
- Lightricks/LTX 2.3 模型來源
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX 2.3 空間放大器來源
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX 攝影機控制 LoRA 來源
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/LTX 文本編碼器來源
- Hugging Face: Comfy-Org/ltx-2
注意:引用的模型、數據集和代碼的使用需遵守其作者和維護者提供的各自許可和條款。