
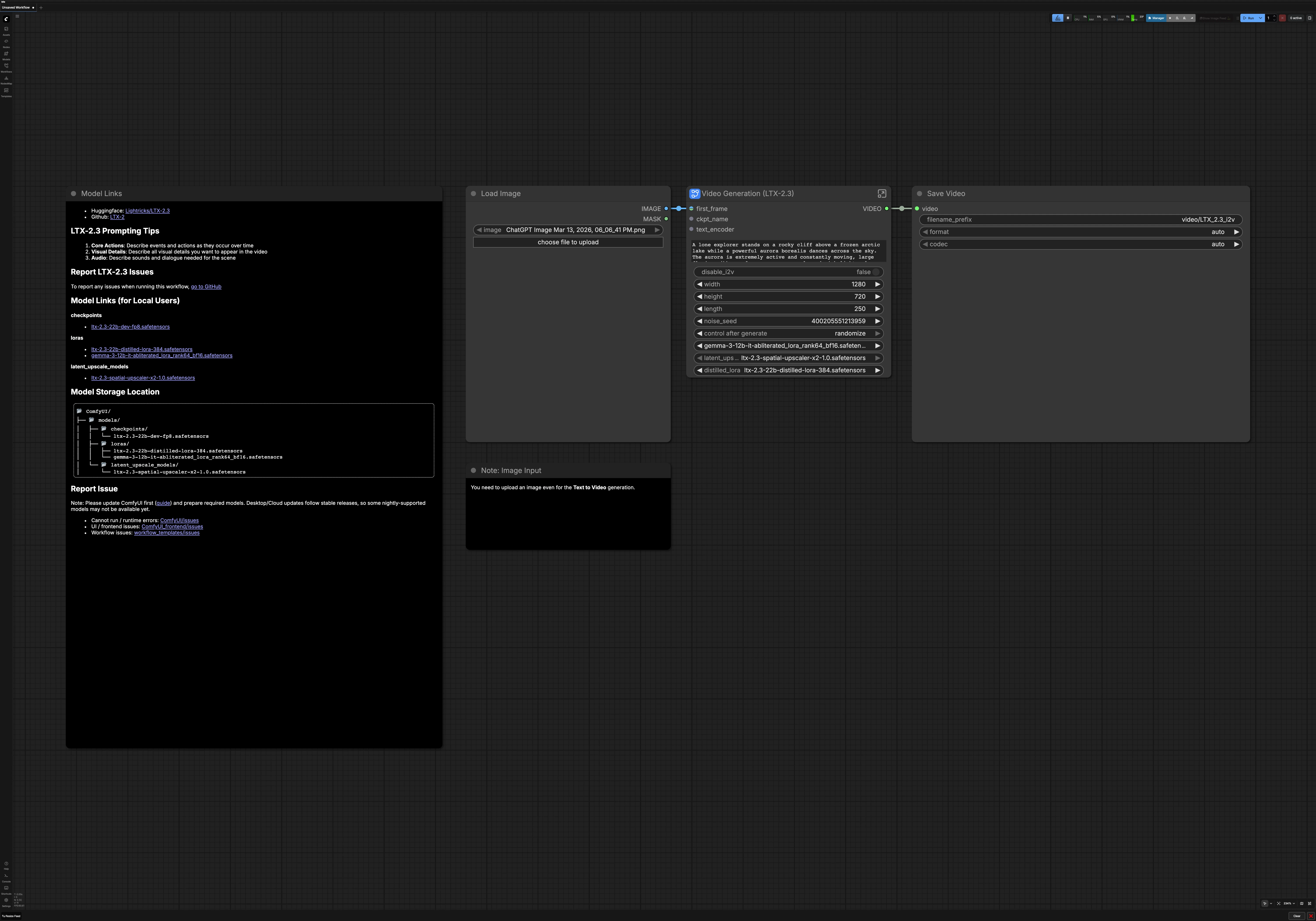
ComfyUI 的 LTX 2.3 圖像轉視頻#
此工作流將單一圖像或純文本提示轉換為流暢的電影化 AI 視頻,使用 LTX 2.3 圖像轉視頻。專為希望高視覺一致性、強場景一致性和精緻運動的創作者而設計,無需手動接線。在 RunComfy 或任何 ComfyUI 環境中使用它以生成動態、風格化的結果,忠實於您的提示。
該圖支持兩種創意模式:以您的第一幀作為視覺錨的圖像轉視頻,或完全由語言引導的文本轉視頻。它還包括自動提示增強、潛在超分辨率以獲得更清晰的細節,以及可選的音頻解碼,使您的最終 LTX 2.3 圖像轉視頻渲染準備好發布。
ComfyUI LTX 2.3 圖像轉視頻工作流中的關鍵模型#
- Lightricks LTX 2.3 22B 視頻模型。核心視頻擴散轉換器,從文本和可選圖像指導中合成時間一致的運動和視覺效果。模型文件和文檔可在 Hugging Face 上獲得,代碼級參考在 GitHub。
- LTX Audio VAE。音頻變分自編碼器,用於將模型的音頻潛在解碼為音軌,與幀合併。隨 LTX 2.3 版本在 Hugging Face 上分發。
- LTX 2.3 空間超分辨率 x2。一個潛在空間超分辨率模型,在最終高分辨率採樣通過之前提高清晰度和空間保真度。可在 LTX 2.3 資源庫中獲得 Hugging Face 上。
- Gemma 3 12B 指令文本編碼器加 LoRA。這裡使用的緊湊指令調優文本編碼器和 LoRA 用於改善提示理解和措辭。此模板使用的打包編碼器和 LoRA 權重在 Comfy-Org LTX-2 資產中提供於 Hugging Face。
如何使用 ComfyUI LTX 2.3 圖像轉視頻工作流#
在高層次上,您的提示和可選的第一幀被編碼,然後採樣低分辨率潛在視頻,然後在潛在空間中放大並在更高分辨率下進行精煉。結果被解碼為幀和音頻,然後組合成最終 MP4。在運行之前,您可以隨時在圖像轉視頻和文本轉視頻之間切換。
- 模型
- 此組加載 LTX 2.3 檢查點、音頻 VAE 和文本編碼器。它還將 LTX 2.3 LoRA 應用於基礎模型以改進指令遵循。它們共同定義了 LTX 2.3 圖像轉視頻管道的基礎。除非您更換模型變體或 LoRA 風格,否則通常不會更改這裡的任何內容。
- 提示
- 輸入您的場景描述和可選的否定。文本被編碼為正面和負面條件,並與您選擇的幀率配對,以便運動規劃與時間保持一致。使用描述變化的動詞使語言與時間相關,例如“相機向前推”或“葉子在風中旋轉”。否定提示有助於避免不需要的人工痕跡,如水印或卡通簡化。
- 提示增強
- 該圖包括一個助手,分析您的圖像和文本,然後生成一個更強的、時間感知的提示草稿,您可以採用或編輯。這使得更容易將 LTX 2.3 圖像轉視頻引導至電影化、動作驅動的描述。當您從單一靜態開始並希望運動感覺有意圖時,這尤其有幫助。預覽節點讓您在生成之前檢查增強的文本。
- 視頻設置
- 選擇是否運行圖像轉視頻或切換到文本轉視頻,簡單切換即可。設置寬度、高度、持續時間和幀率以適合您的目標平台。這些設置驅動潛在分配和下游解碼,因此請確保它們與您的創意意圖保持一致。如果您計劃廣泛發布,請選擇編解碼器友好的尺寸和時間。
- 圖像預處理
- 您的第一幀被調整大小並歸一化為模型友好的比例,同時保留構圖。一個輕微的預過濾有助於穩定邊緣並減少壓縮噪音,這可能在運動期間造成閃爍。即使您僅使用圖像來建議佈局和顏色,這一步也很重要。
- 空潛在
- 工作流根據您的尺寸、持續時間和幀率分配空的視頻和音頻潛在。這為採樣器提供了一個乾淨的畫布,並確保音頻和視頻保持長度一致。當您希望可重現性時,噪音會確定性生成或在運行之間隨機生成變化。
- 生成低分辨率
- 第一個採樣通過將運動和結構雕刻成一個緊湊的潛在視頻。如果您使用圖像轉視頻,
LTXVImgToVideoInplace(#249) 將您的第一幀作為視覺錨注入,以便運動從一致的起始點發展。來自您的正面和負面文本的調節引導內容和風格,而ManualSigmas(#252) 和KSamplerSelect定義噪音隨時間的去除程度。LTXVCropGuides(#212) 有助於保持與您的提示匹配的構圖。然後將生成的音視頻潛在分割以便單獨處理。
- 第一個採樣通過將運動和結構雕刻成一個緊湊的潛在視頻。如果您使用圖像轉視頻,
- 潛在放大
- 在承諾高分辨率精煉之前,
LTXVLatentUpsampler(#253) 將 x2 空間放大器應用於低分辨率潛在。在潛在空間中這樣做速度快,並保持學習的運動,同時提高細節能力。這是一種安全的方法,增加清晰度而不引入人工痕跡。
- 在承諾高分辨率精煉之前,
- 生成高分辨率
- 第二個採樣器在更大的空間尺寸下精煉放大的潛在,以鎖定紋理、照明和小運動。運行文本轉視頻時,可以繞過早期的圖像轉視頻步驟,
LTXVImgToVideoInplace(#230) 僅將潛在通過。VAEDecodeTiled(#251) 然後高效地將視頻潛在解碼為幀。同時,音頻潛在使用 LTX Audio VAE 解碼,因此兩個流最終幀準確。
- 第二個採樣器在更大的空間尺寸下精煉放大的潛在,以鎖定紋理、照明和小運動。運行文本轉視頻時,可以繞過早期的圖像轉視頻步驟,
- 導出
CreateVideo(#242) 將幀和音頻合併為您選擇幀率的單一視頻。頂級SaveVideo節點將最終文件寫入您的 ComfyUI 輸出,以便您立即下載。您的 LTX 2.3 圖像轉視頻渲染現在可以預覽或發布。
ComfyUI LTX 2.3 圖像轉視頻工作流中的關鍵節點#
LTXVImgToVideoInplace(#249 和 #230)- 將靜態轉換為視頻潛在或在禁用時將潛在通過。當您希望第一幀定義佈局、調色板和角色位置時使用它。如果您希望運動僅從提示中出現,請切換文本轉視頻開關。操作符系列的文檔在 ComfyUI 集成中維護於 GitHub。
LTXVConditioning(#239)- 將編碼的正面和負面文本與您的幀率結合以產生調節,指導內容和運動節奏。偏好簡短、清晰的句子來描述隨時間變化,並將否定預留給您持續看到並希望抑制的人工痕跡。這個節點是調整風格和場景行為而不接觸採樣器的最有效地方。
ManualSigmas(#252) 與KSamplerSelect- 噪音日程和採樣器共同工作以在大運動與細節之間進行權衡。早期的高噪音鼓勵更廣泛的運動,而後期步驟則鞏固紋理。僅在您有良好的提示和圖像指導後調整這些。基礎採樣控制遵循標準 ComfyUI 語義,請參見 LTX 資源庫中的參考實現於 GitHub。
LTXVLatentUpsampler(#253)- 在潛在空間中應用 LTX 2.3 空間放大器,以便您可以在下一階段以更高分辨率進行精煉。當您需要額外的清晰度或計劃交付更大格式時使用它。x2 模型隨 LTX 2.3 在 Hugging Face 上分發。
VAEDecodeTiled(#251) 和CreateVideo(#242)- 平鋪解碼防止在更高分辨率下的記憶體尖峰,並確保一致的幀質量。然後
CreateVideo將幀和解碼的音頻流合併為選擇的 fps 的最終 MP4。保持您的 fps 與調節期間使用的值一致,以避免播放漂移。
- 平鋪解碼防止在更高分辨率下的記憶體尖峰,並確保一致的幀質量。然後
可選附加功能#
- 即使使用文本轉視頻,您仍需要上傳第一幀圖像。切換將在生成期間忽略它,但 UI 需要一個佔位符圖像。
- 對於 LTX 2.3 圖像轉視頻提示,首先是核心動作,然後是視覺細節,然後是氛圍。像“緩慢地”、“突然地”和“持續地”這樣的時間詞幫助模型計劃運動。
- 使用否定提示避免覆蓋和 UI 人工痕跡,例如“水印”、“字幕”或“靜止幀”。
- 如果風格看起來過強或過弱,嘗試不同的 LoRA 或在 LoRA 加載器中調整其權重。您也可以刪除 LoRA 以依賴基礎模型的外觀。
- 在文本迭代時重用固定的噪音種子以便可重現性,然後在鎖定鏡頭後隨機生成變化。
致謝#
此工作流實施並建立在以下作品和資源之上。我們衷心感謝 Lightricks 提供 LTX-2.3 和 EyeForAILabs 提供 EyeForAILabs YouTube 教程的貢獻和維護。權威細節請參見下方鏈接的原始文檔和資源庫。
資源#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: LTX-2: Efficient Joint Audio-Visual Foundation Model
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: EyeForAILabs YouTube Tutorial
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款約束。
