
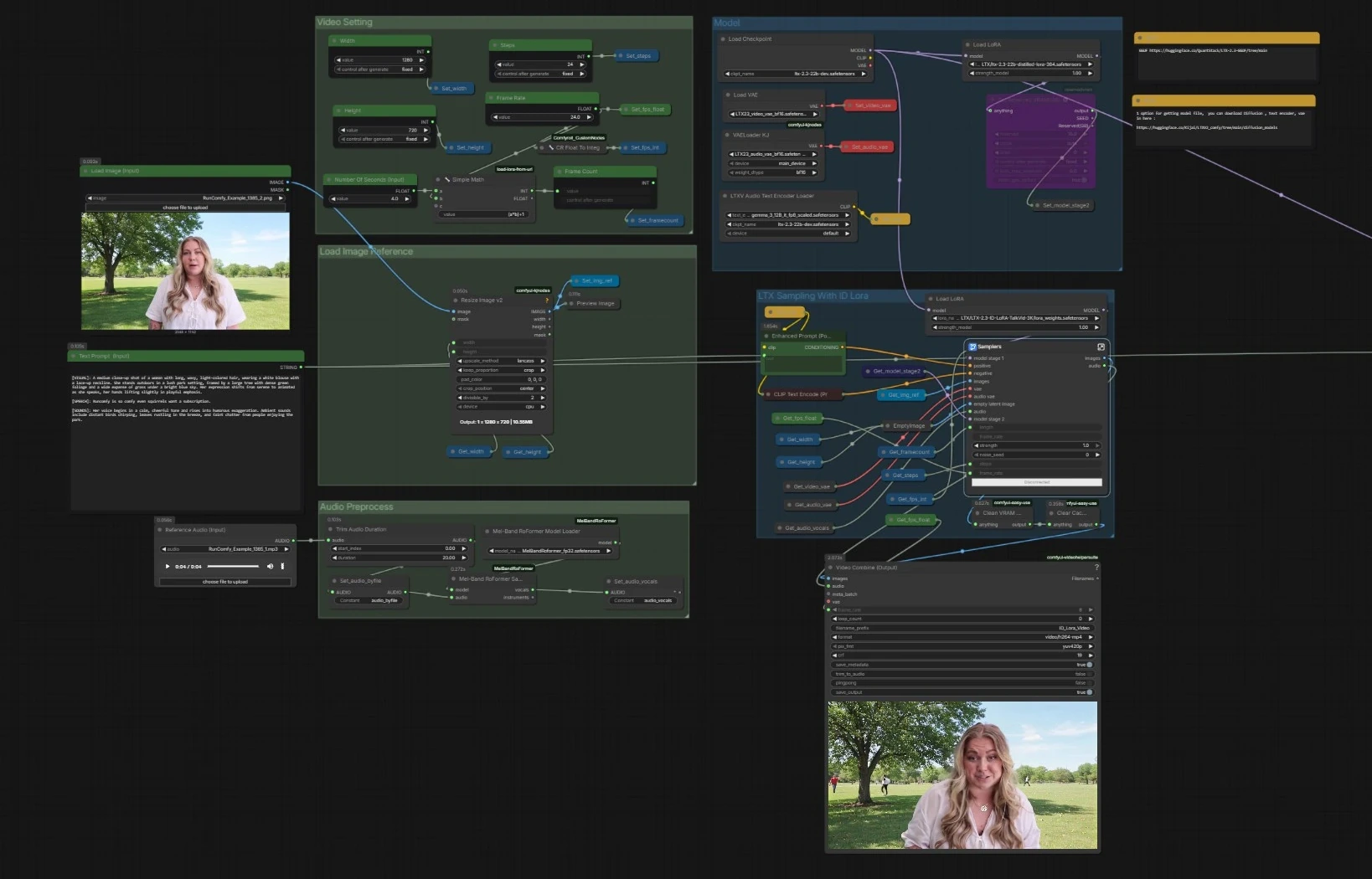
LTX 2.3 ID-LoRA 說話影片工作流程 for ComfyUI#
此工作流程將單張人臉圖像、一段短音頻剪輯和提示轉換為完全同步的說話影片。基於 LTX‑2.3,它將音頻和視覺融合在一個擴散過程中,並添加了一個 In‑Context LoRA 身份適配器,以便您的參考圖像中的人物在所有幀中保持一致。LTX 2.3 ID-LoRA 非常適合化身、虛擬主持人和任何需要唇形同步、相似性和提示控制在一次通過中對齊的場景。
您提供三樣東西:一張參考圖像、一兩句音頻和描述外觀和性能的文本提示。LTX 2.3 ID-LoRA 路徑處理身份,而輕量級音頻預處理器則增強了聲音清晰度以提供更強的口型提示。結果是一個連貫的、保持身份的影片,具有同步的語音,而不需要每個主體的訓練。
Comfyui LTX 2.3 ID-LoRA 工作流程中的關鍵模型#
- Lightricks LTX‑2.3 22B 基礎檢查點。聯合音視頻基礎模型,從文本、圖像和音頻條件生成同步的幀和聲音。這是此 ComfyUI 流程中使用的核心生成器。Model card
- LTX‑2.3 distilled LoRA 384。官方 LoRA 適配器,將蒸餾指導應用於基礎模型,以穩定和加速採樣而不犧牲質量。它作為此工作流程中的第二階段模型插入。查看 LTX‑2.3 頁面上的檢查點表。Model card
- LTX‑2.3 空間放大器 x2。潛在空間放大器,用於采樣器子圖內,在解碼前提升空間細節,改善最終影片中的面部和邊緣保真度。Model card
- Gemma 3 12B Instruct 文本編碼器 for LTX‑2.3。提供驅動風格、場景和性能的文本條件。此工作流程使用為 LTX‑2 打包的 Gemma 3 編碼器在 ComfyUI 中。 Comfy‑Org text encoders
- LTX‑2.3 視頻和音頻的 VAEs。專門構建的 VAEs 將模型生成的視覺和聲音潛在變量解碼為圖像和波形。兼容的 bf16 構建在圖中引用。範例來源:Video VAE · Audio VAE
- Mel‑Band RoFormer 用於聲音分離。可選的預處理器,從參考音頻中提取乾淨的聲音,以便模型可以更可靠地跟踪音節和口型。Paper · ComfyUI node
- LTX 2.3 ID‑LoRA (IC‑LoRA)。一個為說話影片使用訓練的上下文內身份 LoRA,使生成器偏向於您的參考圖像中的人臉,同時尊重提示和聲音提示。Lightricks 在模型頁面上記錄了 LoRA 和 IC‑LoRA 的用法。Model card
如何使用 Comfyui LTX 2.3 ID-LoRA 工作流程#
整體流程。管道加載 LTX‑2.3 基礎,帶有文本編碼器和 VAEs,準備您的圖像和音頻,然後運行一個兩階段的 LTX 采樣器,將文本、人臉參考和聲音軌道結合起來生成同步的幀和語音。包含一個並行的采樣器,不帶 ID‑LoRA,用於快速比較。最終幀和音頻被混合到 MP4 中。
- 模型
- 圖加載基礎檢查點,使用
CheckpointLoaderSimple(#5493)、基於 Gemma 的文本編碼器通過LTXAVTextEncoderLoader(#5494),以及專用的視頻VAELoader(#5651) 和音頻VAELoaderKJ(#5649) 的 VAEs。然後應用兩個適配器:官方蒸餾 LoRA 形成階段 2 模型,和 LTX 2.3 ID-LoRA 通過LoraLoaderModelOnly(#5573) 用於身份調節。 - 此階段確保生成器理解您的提示,擁有正確的解碼堆棧,並以效率指導和身份偏向為準備。
- 您通常不會在此處修改任何內容,除非您有替代方案來替換檢查點或 LoRAs。
- 圖加載基礎檢查點,使用
- 視頻設置
- 控制輸出尺寸、幀率、步驟和長度。
Width(#5284)、Height(#5286) 和Frame Rate(#5289) 提供一個小工具,從秒鐘計算總幀數,保持音頻和視頻的一致性。 - 設置一次存儲,並由所有下游節點讀取,以便兩個采樣器和合併器保持一致。
- 當您想要不同的比例、平滑度或持續時間時,首先調整這些值。
- 控制輸出尺寸、幀率、步驟和長度。
- 加載圖像參考
- 通過
Load Image (Input)(#5525) 提供一張清晰的人臉圖像。圖像使用ImageResizeKJv2(#5280) 調整大小,以匹配您選擇的輸出。 - 此預處理的圖像成為 LTX 2.3 ID-LoRA 階段的身份錨點,指導相似性和鏡頭構圖。
- 使用一張光線充足、正面的照片,並且運動模糊最小,以獲得最佳效果。
- 通過
- 音頻預處理
- 使用
Reference Audio (Input)(#5652) 投入一段短的 WAV 或 MP3。若有需要,剪輯會被修剪,然後傳遞給MelBandRoFormerSampler(#5473) 以隔離聲音。 - 清晰的聲音有助於模型推斷音素和時間,從而實現準確的唇形移動和說話節奏。
- 如果您的音頻已經是僅聲音,您可以跳過分離,直接輸入。
- 使用
- LTX 采樣與 ID Lora
- 這是主要路徑。采樣器子圖(
Samplers(#5278))將來自Enhanced Prompt (Positive)(#5174) 的積極提示、負面列表、人臉參考和聲音軌道通過 LTX‑2.3 的 AV 潛在管道混合。 LTXVReferenceAudio將運動與語音對齊,而LTXVImgToVideoInplace將人臉圖像注入潛在的作為空間先驗。LTX 2.3 ID-LoRA 適配器引導生成器朝向您的主體身份。- 此階段包括一個內部潛在放大器,以便在解碼前提升細節。它輸出幀和同步的音頻流。
- 這是主要路徑。采樣器子圖(
- LTX 采樣不帶 ID Lora
- 一個鏡像的采樣器(
Samplers(#5643))運行相同的條件,但不帶 ID‑LoRA 適配器。用於 A/B 檢查或當您想要更多自由,遠離參考身份時。 - 其他一切保持不變,因此您注意到的差異僅由身份調節引起。
- 此路徑可用於快速草稿或創意偏離。
- 一個鏡像的采樣器(
- 視頻合併和輸出
- 幀和生成的音頻通過
Video Combine (Output)(#5218) 合併為 MP4。幀率來自您的全局設置,因此運動和唇形同步與采樣器的時間匹配。 - 如果您啟用了它,次要的
Video Combine(#5645) 預覽無 ID-LoRA 分支,這對於比較很有用。 - 工作流程在運行之間清理緩存,以保持長時間會話的 VRAM 穩定。
- 幀和生成的音頻通過
Comfyui LTX 2.3 ID-LoRA 工作流程中的關鍵節點#
LoraLoaderModelOnly(#5573)- 加載 LTX 2.3 ID-LoRA,保持面部身份。如果您想要更多創意變化,請減少其權重,或者增加它以更緊密地鎖定相似性。謹慎配對提示強度,以便身份和風格不會競爭。參考:LTX‑2.3 LoRA 在模型頁面上的用法。Model card
LTXVReferenceAudio(#5589)- 將您的參考音頻轉換為音節時間、語調和口型的條件。提供清晰的語音以獲得最佳對齊。如果您聽到抽動或偏離節奏的發音,請縮短或簡化剪輯,而不是增強強度。
LTXVImgToVideoInplace(#5245, also used later)- 將人臉圖像注入潛在視頻流作為空間先驗。圖像強度控制平衡對照片的依從性與運動自由。為了強大的身份與自然運動,保持圖像強度適中,讓 ID-LoRA 承擔相似性。
LTXVConditioning(#5621)- 包裝文本條件和時間提示,用於 LTX 采樣器。確保其幀率輸入與您的輸出幀率匹配,以便運動場和音素時間保持一致。
VHS_VideoCombine(#5218)- 將幀和音頻混合到最終文件中。如果您的音頻稍微長於幀,請在此處啟用修剪,以防止尾部出現黑尾。為了平台兼容性,請保持默認的 H.264 設置,除非您有理由更改它們。節點參考:ComfyUI‑VideoHelperSuite
MelBandRoFormerSampler(#5473)- 使用 Mel‑band 變壓器分離聲音與音樂,以便生成器鎖定到語音。如果齒音模糊或爆破音爆裂,請嘗試同一系列的不同模型文件或減少輸入音量。背景閱讀:arXiv
可選擴展功能#
- 對於 LTX‑2.3 最穩定的生成,使用寬度和高度可被 32 整除,並選擇 8n + 1 的幀數,如 Lightricks 所記錄的。Model card
- 保持參考圖像與您的提示一致。如果您描述戶外照明但提供室內照片,身份可能會保持,而顏色和陰影會與提示對抗。
- 給音頻 2 到 8 秒的自然節奏。即使在聲音分離後,過於壓縮或混響的剪輯會降低唇形同步的保真度。
- 當面部漂移時,稍微降低圖像強度,更多依賴 LTX 2.3 ID-LoRA。當面部漂動過多時,做相反的操作。
- 對於較長的拍攝,生成具有相同種子和全局設置的段,然後在需要時在視頻編輯中加入剪輯。
參考和有用的儲存庫#
- LTX‑2.3 開放權重和筆記:Hugging Face model page
- LTX Video 的官方 ComfyUI 節點:Lightricks/ComfyUI‑LTXVideo
- LTX‑2 代碼庫和論文:Lightricks/LTX‑Video · arXiv
- Gemma 3 12B IT 編碼器 for LTX in ComfyUI:Comfy‑Org/ltx‑2 text_encoders
- Mel‑Band RoFormer 背景:arXiv
感謝#
此工作流程實施並建立在以下作品和資源之上。我們感謝 LTX 2.3 ID-LoRA Source 的創建者對 LTX 2.3 ID-LoRA Source 工作流程的貢獻和維護。欲獲取權威詳情,請參閱下方鏈接的原始文檔和儲存庫。
資源#
- LTX 2.3 ID-LoRA Source
- 文檔 / 發布說明:YouTube @Benji’s AI Playground
注意:參考模型、數據集和代碼的使用受其作者和維護者提供的相應許可和條款約束。
