
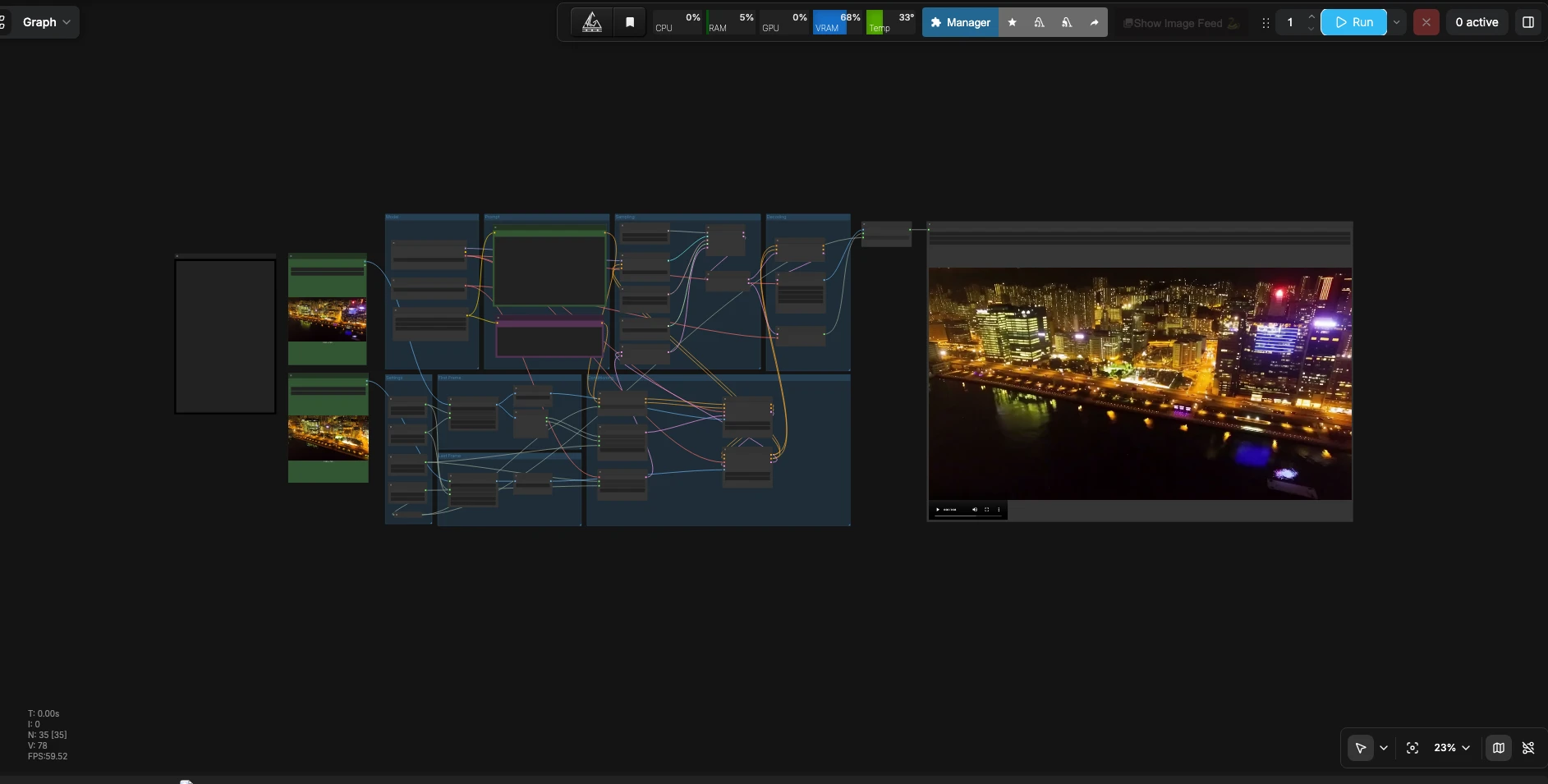
LTX 2.3 首尾影格到影片#
LTX 2.3 首尾影格到影片是 ComfyUI 的一個工作流程,能將兩張靜態圖片轉換為平滑、連續的影片,並同步音頻。您提供一個第一影格、一個最後影格和一個自然語言提示,描述運動、場景細節和聲音。這個流程由 LTX-2.3 22B distilled FP8 檢查點提供支持,在保持外觀和時間一致的情況下,插值這些圖片。這對於需要無縫過渡或直接在 ComfyUI 中創建短循環剪輯的編輯者、運動設計師和故事板藝術家來說是理想的選擇。
這個 LTX 2.3 首尾影格工作流程強調高效的推斷和高提示保真度。FP8 權重控制 VRAM 使用,而 Gemma 3 12B 文本編碼器提高了對視覺和音頻指令的語義理解。結果是一個從第一影格到最後影格的連貫視覺過程,忠實於您的提示並與生成的音頻同步。
Comfyui LTX 2.3 首尾影格工作流程中的關鍵模型#
- LTX-2.3 22B Distilled FP8 檢查點由 Lightricks 提供。核心影片生成模型,經過蒸餾以實現高效推斷,在此用於合成時間上連貫的影格,同時依賴於兩張圖片指導和文本提示。模型卡
- Gemma 3 12B IT 文本編碼器。提供對提示中視覺和音頻方面的強大語言理解能力,實現精確的運動、場景屬性和音軌提示。模型卡
- LTX-2.3 潛在變分自編碼器(VAEs)用於影片和音頻。這些組件在解碼過程中將圖片和波形音頻映射到緊湊的潛在空間並返回,保持質量同時保持高效的取樣。隨 LTX-2.3 FP8 發布。模型卡
如何使用 Comfyui LTX 2.3 首尾影格工作流程#
此工作流程採用兩張參考圖片和一個提示,利用首尾影格指導構建條件,取樣一個同步音頻的影片潛在空間,並將所有內容解碼為可播放文件。
設定
- 在設定組中設置目標解析度、影格數量和影格率。寬度和高度定義工作畫布;輸入影格會被調整大小以匹配,以便模型可以乾淨地插值。影格數量控制過渡持續時間,影格率設置播放速度。選擇與您的來源匹配的長寬比以避免不必要的裁剪。節點
WIDTH(#113)、HEIGHT(#98)、Length(#102) 和Frame Rate(int)(#114) 錨定這些選擇。
第一影格
- 在
Load First Frame(#31) 中加載您的起始圖片。它被ResizeImageMaskNode(#124) 調整到目標尺寸,並由LTXVPreprocess(#104) 正規化。這準備了第一影格,以在剪輯開始時作為強有力的結構和色彩指導。使用清晰、光線良好的圖片以獲得最佳效果。
最後影格
- 在
Load Last Frame(#39) 中加載您的結束圖片。圖片被ResizeImageMaskNode(#125) 調整到相同尺寸,並由LTXVPreprocess(#99) 正規化。這確保了您在過渡結束時想要的最終外觀和佈局。對於循環,請確保最後影格在視覺上與第一影格兼容。
提示
LTXAVTextEncoderLoader(#103) 提供文本編碼器,兩個CLIPTextEncode節點捕獲您的正面和負面提示。在正面提示中 (CLIPTextEncode(#128)),描述相機運動、主題、照明,還包括音頻提示,如 "Music: ambient pads with soft percussion" 或 "Dialogue: brief whisper." 負面提示 (CLIPTextEncode(#112)) 可以列出您想要抑制的工Artifacts 或特徵。
條件
LTXVConditioning(#109) 將文本條件與時間信息合併,以便運動和音頻與您選擇的影格率對齊。EmptyLTXVLatentVideo(#108) 在您的解析度和長度上創建一個影片潛在空間。兩次LTXVAddGuide操作首先附加第一影格 (LTXVAddGuide(#115)) 然後附加最後影格 (LTXVAddGuide(#111)),以便模型知道從哪裡開始和結束。LTXVEmptyLatentAudio(#101) 初始化一個匹配持續時間的音頻潛在空間,並由LTXVConcatAVLatent(#119) 將音頻和影片潛在空間合併以進行取樣。
模型
CheckpointLoaderSimple(#127) 加載 LTX-2.3 22B distilled FP8 權重和影片 VAE,而LTXVAudioVAELoader(#126) 提供音頻 VAE。這些都已預配置好,讓您可以專注於創意輸入而非設置細節。
取樣
CFGGuider(#116) 平衡文本和指導影格的遵循與創意自由。RandomNoise(#100) 設定一個種子以便重現性。取樣器使用SamplerEulerAncestral(#117),自ManualSigmas(#118) 提供的自定義計劃,由SamplerCustomAdvanced(#120) 組織,以逐步完善潛在空間,符合您的運動和音頻指令。
解碼
- 取樣後,
LTXVSeparateAVLatent(#121) 將合併的潛在空間分離回影片和音頻。LTXVCropGuides(#106) 精煉空間指導以減少邊緣工Artifacts,在圖像解碼之前。VAEDecodeTiled(#105) 生成影格序列,LTXVAudioVAEDecode(#107) 產生音頻波形。CreateVideo(#122) 在您選擇的 fps 下多工影格和聲音,SaveVideo(#68) 將最終文件寫入您的 ComfyUI 輸出。
Comfyui LTX 2.3 首尾影格工作流程中的關鍵節點#
EmptyLTXVLatentVideo (#108)
- 定義剪輯的工作解析度和持續時間。在這裡調整寬度、高度和長度以設置視覺尺度和過渡時間。較長的持續時間需要提示中更強的運動提示以避免停滯。
LTXVAddGuide (#115)
- 在序列開始時注入第一影格作為結構和色彩錨點。如果開頭偏離您的來源,增加此指導的影響力;如果感覺過於受限,稍微減少它以允許更多運動。
LTXVAddGuide (#111)
- 在剪輯結束時使用最後影格錨定目標外觀。如果過渡超出或從未完全落到您的最後影格上,增加指導影響力;如果最後過於緊繃,稍微減少它。
CFGGuider (#116)
- 控制模型遵循文本和圖像條件的強度。較高的指導強調您的提示和指導,但可能降低流暢性;較低的值感覺更自由,但可能偏離預期外觀。在比較時小步調整,並重用相同的種子。
SamplerCustomAdvanced (#120) 與 SamplerEulerAncestral (#117) 和 ManualSigmas (#118)
- 使用一致的計劃推動去噪,以保持穩定運動。較短的計劃渲染更快但可能粗糙;較長或較緩和的計劃提高一致性但增加計算成本。在 A/B 測試其他參數時保持計劃一致。
CreateVideo (#122)
- 以您選擇的影格率多工解碼的影格和音頻。使用與您設置的 fps 相同的 fps,這樣唇形、腳步聲或音樂節拍保持對齊。
可選附加功能#
- 使用動詞和時間編寫提示:“相機向前移動”,“燈光隨著我們接近而變暗”,“音樂:稀疏鋼琴與柔和混響。”清晰的動詞幫助 LTX 2.3 首尾影格管道推斷運動和節奏。
- 匹配您的兩張圖片的長寬比和方向。大的不匹配可能會引入不必要的裁剪或拉伸。
- 為了實現無縫循環,使最後影格與第一影格接近匹配,並保持相機運動循環。
- 在
RandomNoise中重用種子以在提示或指導強度上迭代時重現外觀;更改種子以探索新的變化。 - 如果您需要實施細節或自定義節點參考,請參閱 ComfyUI 的 LTX 集成和實用程序,如 ComfyUI-LTXTricks。倉庫
致謝#
此工作流程實施並建立在以下作品和資源之上。我們對 Lightricks 的 LTX-2.3 22B Distilled FP8 Checkpoint、Google 的 Gemma 3 12B IT FP4 Text Encoder、logtd 的 ComfyUI-LTXTricks Custom Nodes 和 Comfy.org 的 Comfy.org Official Workflow 的貢獻和維護表示感謝。欲了解詳情,請參閱以下鏈接的原始文檔和倉庫。
資源#
- Lightricks/LTX-2.3 22B Distilled FP8 Checkpoint
- Hugging Face: Lightricks/LTX-2.3-fp8
- Google/Gemma 3 12B IT FP4 Text Encoder
- Hugging Face: google/gemma-3-12b-it
- logtd/ComfyUI-LTXTricks Custom Nodes
- GitHub: logtd/ComfyUI-LTXTricks
- Comfy.org/Comfy.org Official Workflow
- Docs / Release Notes: comfy.org/workflows/video_ltx2_3_flf2v
注意:所引用的模型、數據集和代碼的使用需遵循其作者和維護者提供的相應許可和條款。
